loss function
gradient descent
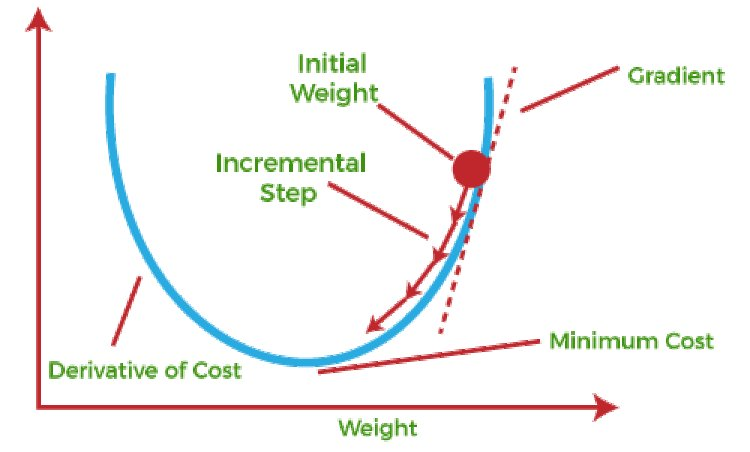
- 현재 위치에서 기울기 (경사) 를 구한다.
- 기울기 아래 방향으로 일정 거리를 이동한다.
- 손실 함수가 최소가 될 때까지 (현재 위치의 기울기가 0) 위를 반복한다.
학습률 (learning rate)
- 기울기 방향으로 얼마만큼 이동할지 결정하는 값
- 학습률이, 가중치를 한 번에 얼마나 갱신할지를 결정한다.
- 신규 가중치 = 기존 가중치 - (학습률 * 기울기)
- 편향 갱신도 마찬가지
- 학습률에 따라 훈련 속도가 달라짐
- 크면 최적 가중치를 찾지 못할 수 있음 (더 빠른 길로 이어지는 지점을 건너뛸 위험)
- 작으면 학습 속도가 너무 느려짐
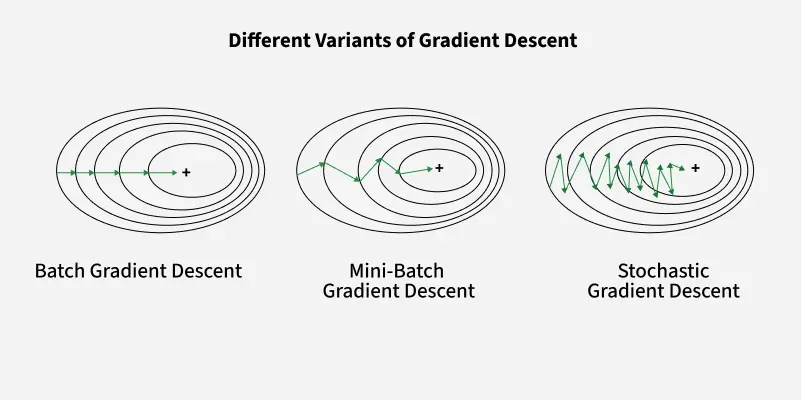
SGD
- Stochastic Gredient Descent (확률적 경사 하강법)
전체 학습 데이터에서 데이터를 무작위로 뽑아 경사 하강법을 수행. ANN 학습 때는 대체로 데이터가 너무 많아, 단순한 SGD 로는 학습 효율이 너무 떨어짐. 이를 해결하기 위해 보통 MGD 사용.
MGD
- Mini-batch Gredient Descent (미니배치 경사 하강법)
데이터를 미니배치 단위로 무작위로 추출해 경사하강법을 수행.
- 미니배치란 여러 데이터의 묶음을 뜻함.
데이터를 하나씩 훈련하기보다, 여러개를 한 묶음으로 처리하는게 더 효유렂ㄱ.
gradient vanishing
• 역전파 알고리즘에서 gradient 값이 신경망의 하위 층으로 전달될 때 지수적으로 감소하여 사라지는 현상 • 주로 활성화 함수로 시그모이드 함수를 사용할 때 발생하는데, 시그모이드 함수의 미분값이 0에 가까워지는 영역에서 기울기가 소실되기 때문입니다. 따라서 깊은 신경망에서는 역전파 알고리즘이 잘 작동하지 않고, 학습이 어려워집니다. • 심층 신경망의 훈련에 영향을 주는 중요한 문제이며, 이를 극복하기 위해 연구와 개발이 계속 진행되고 있습니다. • 완화하기 위한 기법 ◦ ReLU(Rectified Linear Unit) 사용 ◦ 그래디언트 클리핑(Gradient Clipping) 방법을 사용하여 기울기 값을 제한하는 등의 전처리나 알고리즘적인 조치 ◦ regularization 기법을 사용하여 모델의 복잡성을 제어 ◦ 배치 정규화(Batch Normalization)와 같은 방법을 사용하여 그래디언트의 스케일을 조정하는 등의 기법.
gradient exploding
• 역전파 알고리즘에서 기울기(gradient) 값이 지수적으로 증가하여 발산하는 현상 • 완화하기 위한 기법 ◦ 활성화 함수로 시그모이드나 하이퍼볼릭탄젠트 함수 대신에 ReLU나 ReLU의 변형 함수와 같은 Leaky ReLU를 사용. ◦ 그래디언트 클리핑(Gradient Clipping)이 사용 ◦ 가중치 초기화(xavier initialization, he initialization), 학습률 조정, 배치 정규화 등의 기법을 사용하여 Gradient Exploding을 완화 ◦ 모델 구조와 하이퍼파라미터 설정, 데이터 전처리 등을 조절
gradient clipping
• 기울기 값이 임계값을 넘지 않도록 제한하는 방법( 일반적으로 L2 노름을 사용하여 기울기 벡터의 크기를 제한 )