설명
 | 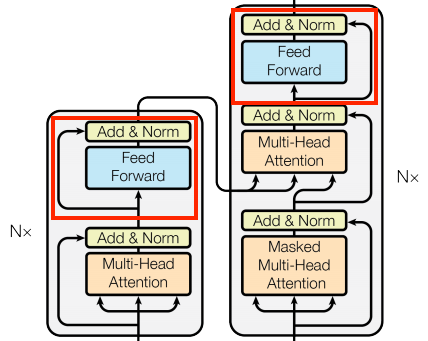 |
입력 (단어 벡터) Multi-Head Self-Attention: 단어들 간의 관계를 파악 (정보를 섞음) Add & Norm (잔차 연결 및 정규화) Position-wise FFNN: 각 단어 벡터를 개별적으로 변환 (정보를 정제/추출) Add & Norm (잔차 연결 및 정규화) 다음 층으로 전달
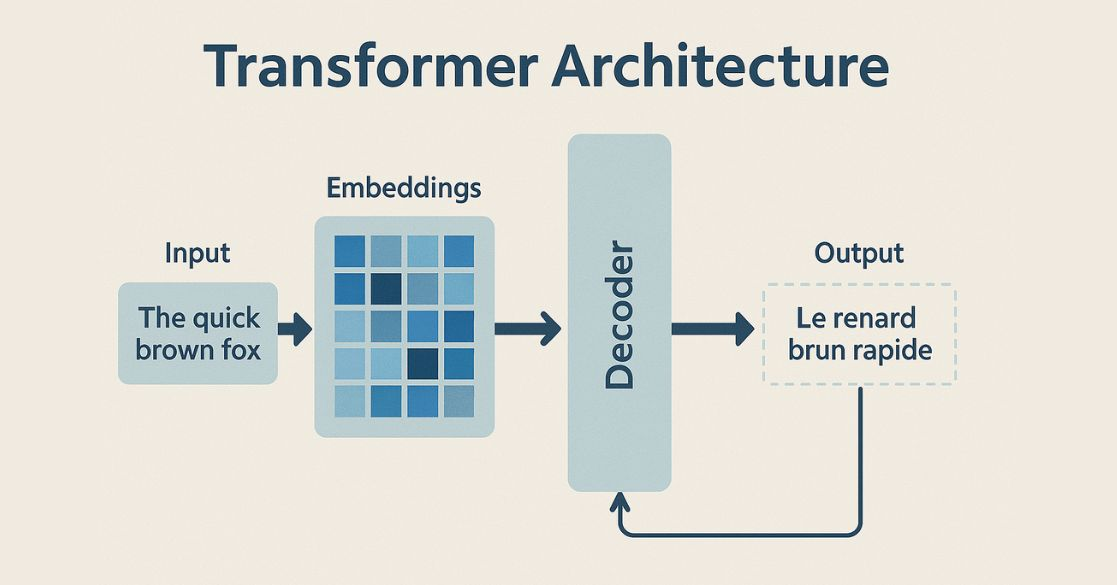
느린 속도와 병렬처리 불가 및 정보 손실의 단점을 개선한 Attention 모델
- 시퀀스 데이터를 처리하는 데에 뛰어난 성능을 보이는 모델
- 어텐션만으로 인코더와 디코더를 처리
- 어텐션을 RNN의 보정을 위한 용도로서 사용하는 것이 아님
- 기존의 순환 신경망 (RNN) 기반의 모델 대비
- 장기 의존성(long-range dependency) 문제를 해결
- 병렬 계산이 가능하여 학습과 추론 속도가 빠름
주요 엔진 (지능)
- 인코더(설계도)라는 공장 안에는,
- ‘Attention(집계 담당)‘과
- ‘FFNN(가공 담당)‘이라는
- 두 종류의 핵심 장비가 나란히 배치되어 있다.
- 어텐션의 한계: 주로 선형적인 가중치 계산
- FFNN의 보완: 활성화 함수(ReLU 또는 GELU)를 포함한 신경망을 통해 데이터의 복잡한 패턴을 학습할 수 있는 비선형성을 주입
attention
attention 의 3가지 형태
트랜스포머는 작업의 단계에 따라 어텐션을 세 가지 방식으로 변형하여 사용
- Encoder Self-Attention: 인코더 내부에서 작동하며, 입력 문장의 단어들이 서로의 문맥을 참조하여 의미를 풍부하게 만든다.
- Masked Decoder Self-Attention: 디코더 내부에서 작동. 미래의 단어를 미리 보고 정답을 베끼는 것을 방지하기 위해, 현재 시점 이후의 단어들을 가리는(Masking) 처리가 추가된 셀프 어텐션.
- Encoder-Decoder Attention: 디코더가 인코더의 정보를 가져올 때 사용. 출력할 단어가 원문의 어떤 부분에 집중해야 하는지 결정하는 ‘다리’ 역할을 한다.
FFNN
- Feed-Forward Neural Network
어텐션 층을 통과한 각 토큰의 벡터들을 독립적으로, 그리고 동일한 방식으로 변환하여
- 비선형성을 더하고
- 특징을 추출하는 층
보통 이하로 구성
- 두 개의 선형 변환(Linear Layer)
- 그 사이의 활성화 함수(Activation Function)
- 첫 번째 선형 변환 (, ): 입력 차원을 보통 4배로 확장 (예: 512→2048).
- 활성화 함수: 원본 논문에서는 ReLU(max(0,x))를 사용했으며, 최신 모델(BERT 등)에서는 GELU를 주로 사용
- 두 번째 선형 변환 (,): 확장된 차원을 다시 원래 차원으로 축소 (예: 2048→512)
- 핵심 특징 (왜 필요한가?)
- Position-wise (위치별 독립 처리)
- 어텐션이 단어 사이의 ‘관계’를 파악했다면, FFNN은 각 단어 벡터를 개별적으로 처리
- 문장 내 모든 단어에 동일한 파라미터(W,b)가 적용되지만, 각 위치마다 독립적으로 연산이 일어납니다.
- 비선형성 추가
- 단순한 어텐션(선형 연산의 조합)만으로는 복잡한 데이터를 학습하는 데 한계가 있음
- 단순히 어텐션만 있으면 모델은 ‘어떤 단어가 어떤 단어와 관련 있는지’는 알 수 있지만, 그 정보를 깊이 있게 처리하는 비선형 연산 능력이 부족해진다
- FFNN의 활성화 함수를 통해 모델에 비선형성을 부여하여 더 깊고 복잡한 의미를 포착
- 단순한 어텐션(선형 연산의 조합)만으로는 복잡한 데이터를 학습하는 데 한계가 있음
- 정보의 재구성
- 어텐션을 통해 섞인 정보들을 다시 정돈하고, 다음 인코더 층으로 넘겨주기 전 각 단어의 표현(Representation)을 더욱 풍부하게 함
• 어텐션을 통해 얻은 단어 임베딩을 다음 레이어로 전달하기 전에 비선형성을 추가하여 더 풍부한 표현을 만들어냅니다. • 구성: ◦ 피드포워드 신경망은 일반적으로 두 개의 선형 변환과 활성화 함수로 구성됩니다. 이 때, 선형 변환은 입력 차원과 출력 차원 사이의 가중치 행렬 연산을 의미하며, 활성화 함수로는 보통 ReLU(Rectified Linear Activation) 함수가 사용됩니다. ◦ 피드포워드 신경망은 하나의 특성 맵(feature map)에 적용되기 때문에, 모든 단어의 임베딩 벡터에 동일한 연산이 적용되며, 각 단어의 임베딩 벡터는 개별적으로 처리됩니다. • 연산: ◦ 피드포워드 신경망은 각 단어의 임베딩 벡터를 두 번의 선형 변환을 통해 차원을 확장하고 줄이는 과정을 거칩니다. ◦ 먼저, 입력 임베딩 벡터를 높은 차원의 은닉 상태로 매핑하기 위해 첫 번째 선형 변환을 수행합니다. 이 때, 해당 선형 변환은 가중치 행렬과 입력 벡터의 내적 연산을 통해 이루어집니다. ◦ 그 다음, ReLU 활성화 함수를 사용하여 음수 값을 제거하고 양수 값만을 유지합니다. ◦ 이후, 두 번째 선형 변환을 통해 은닉 상태를 다시 원래의 저차원으로 매핑합니다. 이러한 연산을 통해 단어의 임베딩 벡터에 비선형성을 부여하여 더 풍부한 문맥 정보를 표현하게 됩니다. • 정규화: ◦ 피드포워드 신경망은 잔차 연결(residual connection)과 레이어 정규화(layer normalization)를 통해 안정적인 학습을 지원합니다. ◦ 잔차 연결은 입력과 출력을 더하는 것으로, 신경망의 깊이가 깊어질수록 그레디언트 소실 문제를 완화하는 데 도움을 줍니다. ◦ 레이어 정규화는 각 레이어의 출력을 평균과 분산으로 정규화하여 학습 안정성을 향상시킵니다.
메커니즘 구조
Encoder-Decoder (뼈대)
seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점(time step)을 가지는 구조였다면 transformer에서는 인코더와 디코더라는 단위가 N개로 구성
- ChatGPT1은 decoder로 12개 layer를 사용함.
트랜스포머 기술의 핵심은 유지하되, 뼈대는 필요에 따라 변형 가능
- 인코더만 사용: BERT (문맥 이해 중심)
- 디코더만 사용: GPT (문장 생성 중심)
Positional Encoding
단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용(sin, cos 함수 사용)
Add&Norm
Add (residual connection)
Norm (Layer-Nomalization)
각 층의 활성화 값을 평균과 분산을 이용하여 정규화함으로써, 학습을 안정시키고 속도를 향상시키는 기술
- , : 입력 벡터 요소들의 평균, 분산
- : 분모가 0이 되는 것을 방지하는 아주 작은 상수
- : 모델이 학습을 통해 최적화하는 스케일(Scale) / 시프트(Shift) 패러미터