optimizer
신경망의 최적 가중치를 찾아주는 알고리즘
손실 함수(loss function)의 값을 최소화하기 위해 모델의 가중치(Weights)를 어떻게 업데이트할지 결정하는 알고리즘
- 핵심 역할: 기울기(Gradient)를 계산하여 가중치를 어느 방향으로 수정할지 결정
- 작동 원리: 가장 기본적인 업데이트 식 ( 는 학습률, 은 기울기)
SGD 도 대표적인 예시
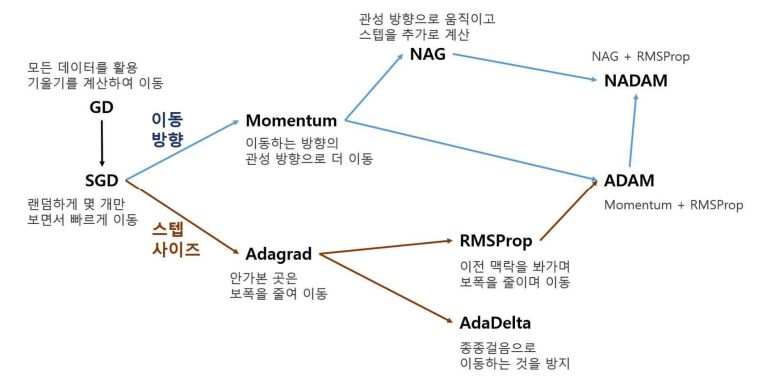
optimizer
• 모델의 학습 과정에서 사용되는 알고리즘 또는 방법을 의미 • 모델의 가중치와 편향을 조정하여 손실 함수를 최소화하는 최적의 파라미터 값을 찾는 역할을 수행 • 옵티마이저의 선택은 학습의 속도와 결과에 큰 영향을 미칠 수 있으며, 적절한 옵티마이저를 선택하는 것이 중요 • optimizer 기능 ◦ 기울기 계산: 옵티마이저는 손실 함수의 기울기(경사)를 계산합니다. 이를 통해 현재 파라미터 값에서의 손실 함수의 변화를 알 수 있습니다. ◦ 파라미터 업데이트: 옵티마이저는 계산된 기울기를 사용하여 모델의 파라미터 값을 업데이트합니다. 이는 손실 함수를 최소화하는 방향으로 파라미터 값을 이동시킵니다. • 주요 optimizer 알고리즘 ◦ 확률적 경사 하강법 (Stochastic Gradient Descent, SGD): 각 학습 단계에서 무작위로 선택한 일부 데이터만을 사용하여 기울기를 계산하고 파라미터를 업데이트합니다. ◦ 모멘텀 최적화 (Momentum Optimization): 이전 업데이트에서의 기울기를 이용하여 업데이트를 진행하는 방식으로, 학습 속도를 빠르게 만들고 지역 최솟값에서 벗어나는 데 도움을 줍니다. ◦ 아다그라드 (Adagrad): 매개변수마다 학습률을 조정하여 학습을 진행하는 방식으로, 희소한 기울기에 대해서는 큰 학습률을 적용하고 자주 등장하는 기울기에 대해서는 작은 학습률을 적용합니다. ◦ RMSProp: 아다그라드의 단점을 보완한 알고리즘으로, 누적된 기울기 제곱값이 계속해서 커지는 문제를 해결합니다. ◦ 아담 (Adam): 모멘텀 최적화와 RMSProp을 결합한 알고리즘으로, 학습률을 자동으로 조절하면서 최적화 과정을 진행합니다.
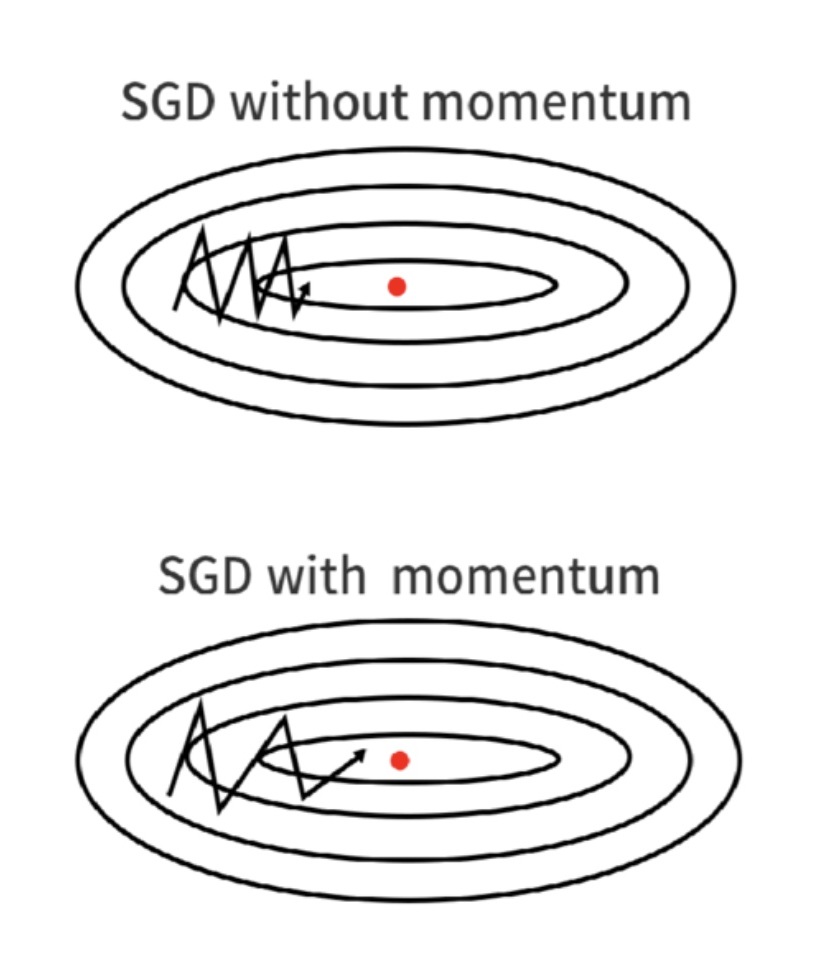 |  |
Momentum
SGD 옵티마이저는 최적 패러미터를 찾아가는 경로가 지그재그. 상당히 비효율적.
SGD 의 문제를 개선해 최적 패러미터를 더 빠르게 찾는 방법이 모멘텀.
SGD 에 물리학의 관성 개념을 추가한 옵티마이저.
이전 단계의 진행 방향을 기억하여 일정 비율로 현 단계에 반영
지그재그가 줄어드는 효과
전체적으로 지그재그 모양은 있지만 관성이 추가된 것을 확인 가능. SGD 보다 최적 패러미터 수렴이 빠름
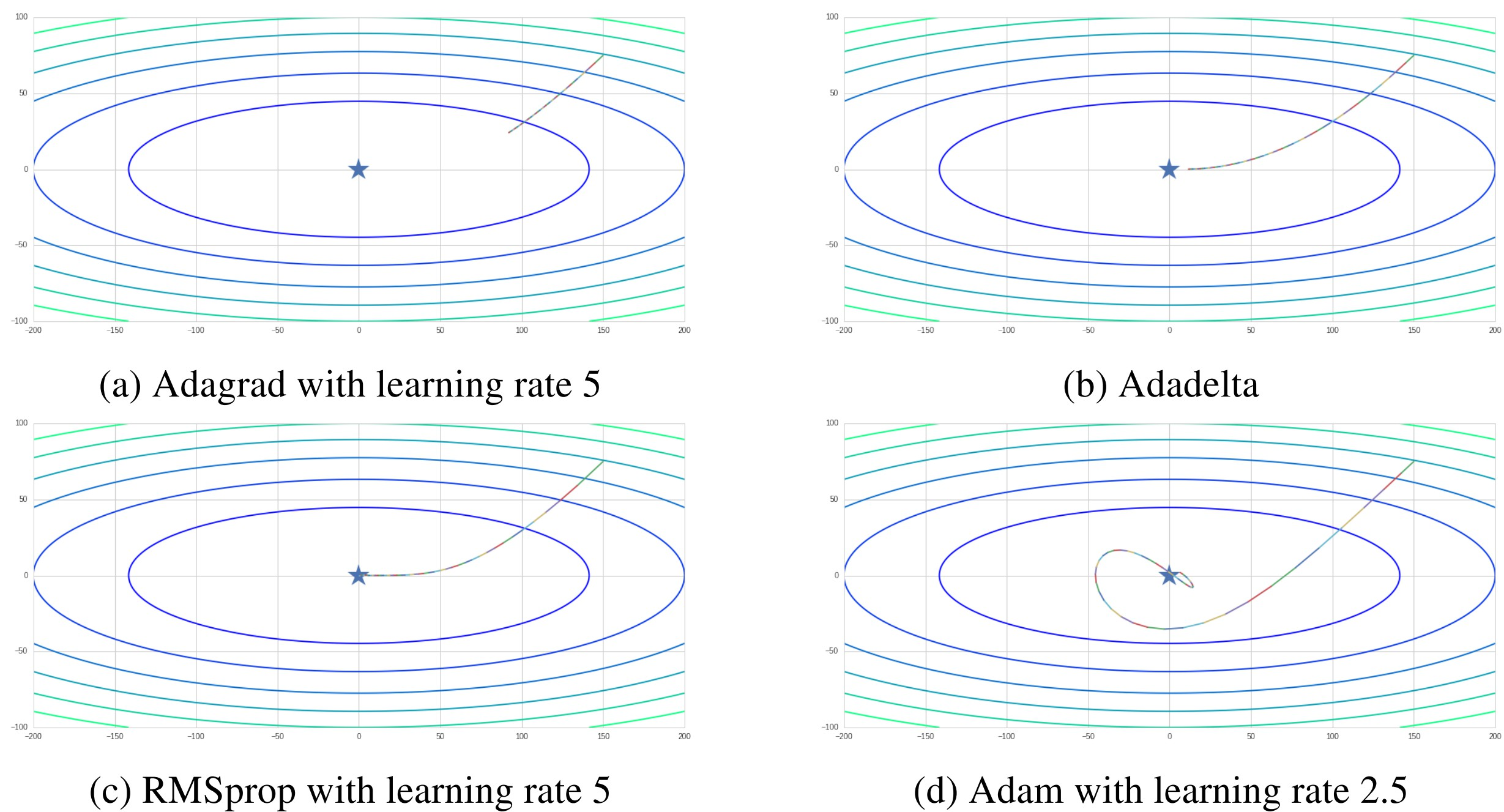
Adagrad
- 학습률이 너무 크면 최적 패러미터를 찾지 못하고 지나침
- 학습률이 너무 작으면 훈련 시간이 오래 걸림
따라서 학습률이 상황에 따라 변하는게 좋음. Adagrad 는 최적 패러미터에 도달할 수록 학습률을 낮추도록 한 옵티마이저
최적점에서 멀 때는 학습률을 크게 잡아 빠르게 수렴하도록 최적점에 가까워졌을 때는 학습률을 낮춰 최적점을 지나치지 않도록
이런 학습률을 적응적 학습률 (adaptive learning rate) 라고 한다.
Adagrad 는 개별 패러미터에 적응하며 학습률을 갱신하는 옵티마이저
RMSProp
Adagrad 의 단점 보완
Adagrad 는 훈련을 진행할수록 학습률이 작아져, 오래 지속하면 결국 에 가까워짐
- 모델 가중치가 거의 갱신되지 않음
RMSProp 은 최근 기울기만 고려해 학습률을 낮춤
- Adagrad 는 훈련 시작 단계부터 기울기를 누적해 학습률을 낮춤
훈련을 오래 지속해도 학습률이 0에 수렴하지 않음
Adam
가장 메이저한 옵티마이저
모멘텀과 RMSProp 의 장점을 결함
모멘텀처럼 관성을 이용하면서, RMSProp 처럼 적응적 학습률을 적용