RAG
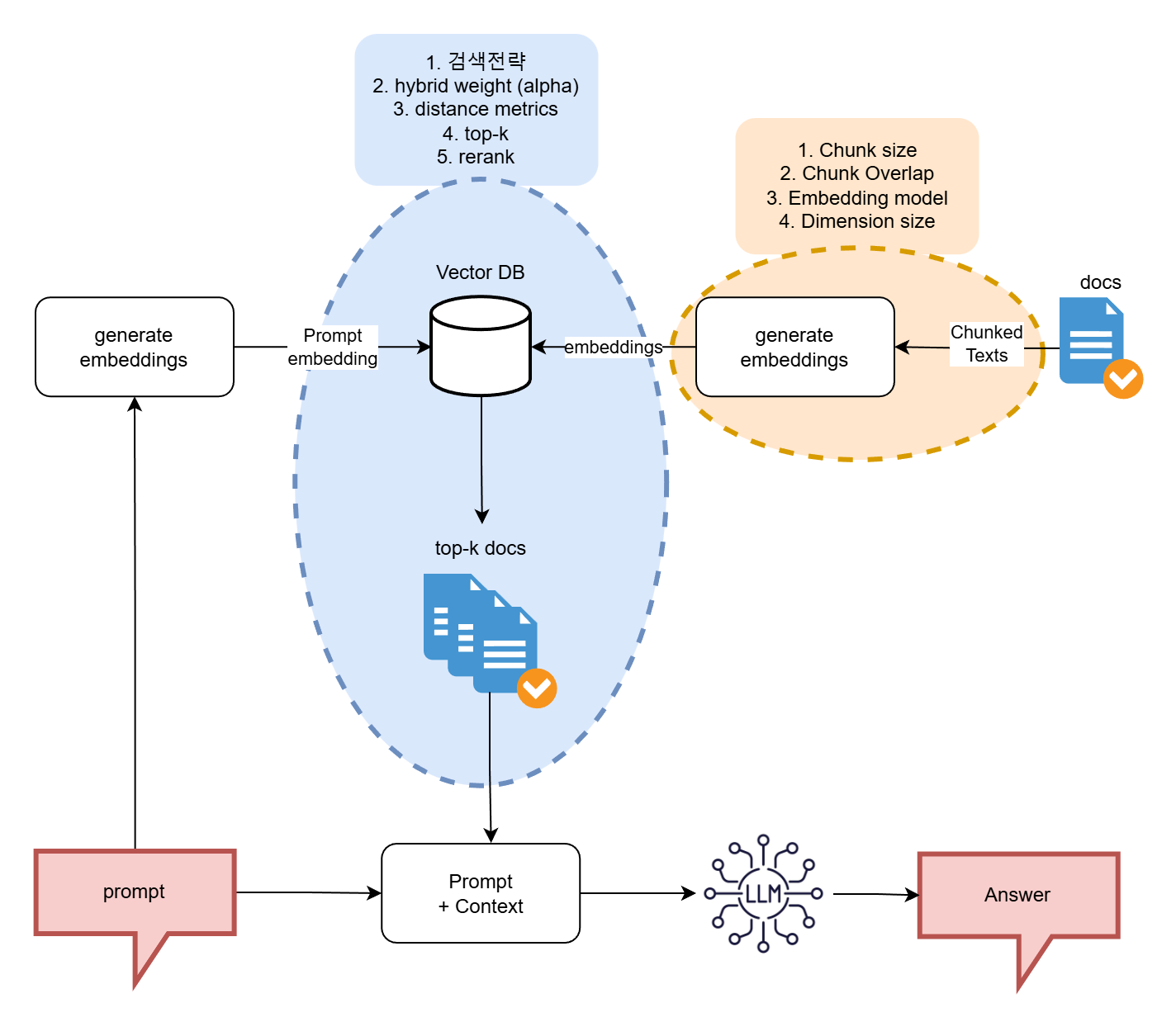
워크플로우
-
질의 입력
-
질의 재작성
- 임베딩 모델과 검색기의 효율을 높이기 위해 원본 질문의 문맥을 보완하거나, 다중 질의(Multi-query)로 분할/확장
-
질의 텍스트를 임베딩 모델을 통해 질의 임베딩 벡터로 변환
-
벡터 DB 에 질의 벡터를 던져, 유사도 지표(Distance Metric)를 기준으로 유사도가 높은 Top-K개의 청크를 반환
- 하이브리드 검색 시 Dense/Sparse 가중치(Alpha) 연산이 개입
-
리랭킹을 통해 노이즈를 제거, 가장 적합한 Top-N개의 청크로 압축
- 1차 반환된 Top-K 청크들을 Cross-Encoder 등의 리랭커 모델에 통과시켜 질의와의 실제 논리적 연관성을 재평가
-
최종 Top-N 청크들을 컨텍스트로 지정, 컨텍스트와 원본 질문을 결합해 최종 프롬프트를 구성
- LLM의 컨텍스트 윈도우 크기 한도 내에서
-
조립된 프롬프트 LLM 에 전달,
-
환각 통제를 위해 temp 같은 파라미터가 적용
-
검색된 컨텍스트에 근거해 답변을 획득
주요 하이퍼패러미터
쿼리 임베딩과 docs 임베딩이 다른 임베딩을 쓰는 이유
질의와 문서는 텍스트 구조와 내포하는 정보의 목적이 근본적으로 다르다. 이를 정보 검색(IR) 영역에서는 비대칭 검색(Asymmetric Search) 환경이라고 정의한다.
- 텍스트 비대칭성 (Text Asymmetry)
- 질의(Query): 짧고, 문맥이 부족하며, 사용자의 ‘의도’가 강하게 압축
- 문서(Document): 길고, 문맥이 풍부하며, 서술형 구조. 구체적인 ‘정보’와 ‘사실’을 담음.
둘 사이의 토큰 분포와 어휘의 특성이 완전히 다르므로, 단일 모델에 동일한 방식으로 밀어 넣을 경우, 구조적 차이로 인해 벡터 공간에서 질문은 질문끼리, 문서는 문서끼리 군집을 형성해버리는 문제가 발생한다.
- 사용자 입력: “BGE-M3 모델의 3가지 주요 특징은 무엇인가?”
- 유사도 검색 1위 (오류): “BGE-M3 모델의 아키텍처는 무엇인가?” 또는 “임베딩 모델의 3가지 주요 특징은 무엇인가?” (동일한 질문 형태)
- 실제 찾아야 할 타겟 문서: “M3는 Multi-Linguality, Multi-Functionality, Multi-Granularity를 의미하며, 밀집 검색과 희소 검색을 모두 지원하는…”
따라서 질의와 문서를 동일한 의미 공간(Semantic Space) 상에 겹치도록 정렬(Alignment)하기 위해 임베딩 생성 방식을 분리한다.
| 구분 | 듀얼 인코더 (Dual-Encoder) | 지시어 튜닝 (Instruction-Tuning) |
|---|---|---|
| 아키텍처 구조 | 질의용, 문서용 2개의 독립된 물리적 신경망 사용 | 질의와 문서 모두 1개의 단일 신경망 공유 |
| 투 타워(Two-Tower) 아키텍처 | ||
| 임베딩 분리 방식 | 가중치가 완전히 다른 별개의 인코더 네트워크를 각각 통과시킴 | 입력 텍스트 앞에 작업 목적을 명시하는 지시어(Prompt)를 강제 삽입 |
| 자원 및 서빙 비용 | 높음 (2개의 모델 가중치를 메모리에 동시에 적재해야 함) | 낮음 (1개의 모델만 서빙하므로 인프라 구축 및 유지에 효율적) |
| 유연성 및 범용성 | 낮음 (학습된 특정 검색 태스크 구조에 고정됨) | 매우 높음 (지시어 텍스트만 바꾸면 대칭/비대칭 검색, 군집화 등 태스크 전환 가능) |
| 대표 모델 | DPR (Dense Passage Retrieval) | INSTRUCTOR, BGE, E5 |
지시어 튜닝
과거에는 질의용 / docs 용 2개로 인코더 자체를 분리하는 쪽이 메이저였으나, 요즘에는 프롬프트 앞단에 지시어를 삽입하여 모델이 자체적으로 분류하는 쪽이 메이저. 이것이 가능한 이유는 임베딩 모델의 대조 학습(Contrastive Learning) 과정 때문이다.
패키지나 코드 아키텍처 수준에서 질문용 임베딩 함수와 문서용 임베딩 함수를 물리적으로 분리한 것이 아니라, 모델을 통과하는 수학적 매핑 함수(트랜스포머 네트워크) 자체는 동일하게 하나만 존재한다. 단지 입력 텍스트 앞에 특정 프롬프트(토큰)를 추가함으로써, 내부의 Self-Attention 연산 결과가 훈련된 패턴에 따라 알아서 벡터의 방향을 틀어버리도록 유도하는 것.
LLM 생성 모델에서의 프롬프트 엔지니어링과 달리, 임베딩 모델의 인스트럭션(프롬프트) 튜닝은 수학적으로 철저히 계산된 제어 메커니즘(Control Mechanism)의 결과다. 명확한 연산 과정으로 볼 수 있는 이유는 다음과 같다.
-
프롬프트 토큰은 단순한 텍스트가 아닌 ‘제어 벡터(Control Vector)‘다. Self-Attention 연산 과정에서 이 프롬프트 토큰들은 전체 시퀀스의 기준점(Anchor) 역할을 한다. 어텐션 행렬 연산 을 거치면서, 프롬프트 토큰의 임베딩 값이 입력된 ‘질문 토큰’들의 어텐션 가중치를 특정 방향으로 강하게 끌어당긴다. 즉, 프롬프트는 고차원 매니폴드(Manifold) 상에서 질의 벡터를 정답 벡터의 하위 공간(Subspace)으로 이동시키는 명시적인 이동 연산자(Shift Operator)로 작용한다.
-
대조 학습에 사용되는 InfoNCE Loss 같은 목적 함수는 프롬프트가 포함된 쿼리 벡터 q와 정답 문서 벡터 간의 내적은 최대화하고, 오답 문서 벡터 와의 내적은 최소화하도록 오차를 계산한다. 방향을 향하지 않으면 모델이 학습되지 않도록 손실 함수가 강제한다. 훈련 과정(수십억 번의 역전파)을 통해, 트랜스포머의 가중치 행렬은 저 프롬프트 토큰 배열이 입력되었을 때 정확히 가 위치한 공간으로 벡터를 사영(Projection)시키도록 물리적으로 깎여 나간다.
-
최신 임베딩 모델(E5, Instructor, BGE 등)은 학습 단계에서부터 검색, 분류, 클러스터링 등 수십 가지의 서로 다른 프롬프트(Task Instruction)와 그에 맞는 정답 쌍을 학습한다. 그 결과, 단일 가중치 모델 내부에는 입력된 프롬프트에 따라 활성화되는 경로가 나뉘는 하위 공간들이 형성된다. 다중 작업 하위 공간(Task-specific Subspace) 자체가 분리된다. 프롬프트를 넣는 행위는 모델 내부에서 “검색용 투영 레이어 연산을 활성화하라”는 스위치를 켜는 것과 동일한 구조적 역할을 수행한다.
Retrieval 방식
| 구분 | Sparse Retrieval (희소 검색) | Dense Retrieval (밀집 검색) | ColBERT (다중 벡터 / 지연 교차) |
|---|---|---|---|
| 핵심 메커니즘 | 키워드 빈도 및 형태 일치 기반 매칭 | 문맥 및 의미(Semantic) 기반 유사도 매칭 | 토큰 단위의 개별 의미 매칭 (Late Interaction) |
| 벡터 생성 단위 | 문서 전체 (어휘 사전 크기의 가변 차원) | 문서(청크) 전체를 1개의 고정 차원 벡터로 압축 | 문서(청크) 내의 모든 개별 단어(토큰)마다 1개의 벡터 생성 |
| 알고리즘/아키텍처 | 통계적 알고리즘 (BM25, TF-IDF 등) | Bi-Encoder 기반 딥러닝 모델 | 딥러닝 모델 (Token-level Bi-Encoder + MaxSim) |
| 장점 | 고유명사, 숫자, 식별자 등 정확한 키워드 검색에 최적 | 동의어 파악 및 문맥 추론 능력 우수 | Dense의 문맥 파악 + Sparse의 정밀한 토큰 매칭 동시 달성 |
| 단점 | 어휘 불일치(Vocabulary mismatch) 발생 시 검색 실패 | 정보 압축으로 인한 세부 맥락 손실, 고유명사 매칭 취약 | 막대한 스토리지 비용 폭발, 높은 연산량 및 검색 지연(Latency) |
| 자원 및 연산 비용 | 매우 낮음 | 보통 (1문서 1벡터 연산) | 매우 높음 (토큰 수만큼 벡터 저장, 교차 내적 연산 필요) |
| RAG 아키텍처 위치 | 1차 검색 (주로 Dense와 하이브리드 결합) | 1차 검색 (주로 하이브리드의 메인 지표) | 1차 검색된 후보군에 대한 정밀 리랭커(Re-ranker)로 주로 활용 |
| Multi-Vector |
주요 임베딩 모델
| 구분 | BGE-M3 | text-embedding-3 | E5 (multilingual-e5) | Cohere Embed v3 | Nomic Embed Text |
|---|---|---|---|---|---|
| 개발사 | BAAI | OpenAI | Microsoft | Cohere | Nomic AI |
| 제공 형태 | 오픈소스 | API (상용) | 오픈소스 | API (상용) | 오픈소스 |
| 지원 아키텍처 | Dense, Sparse, Multi-Vector (동시 지원) | Dense | Dense | Dense | Dense |
| 차원 수 | 1024 | 최대 3072 (축소 가능) | 768 / 1024 | 1024 | 최대 768 (축소 가능) |
| 지시어 튜닝 | 적용 (목적별 프롬프트) | 미적용 (내부 자동 처리) | 필수 적용 (query:, passage: 접두사) | 적용 (API 파라미터 분리) | 적용 (search_query:, search_document:) |
| 핵심 강점 및 특징 | 단일 모델로 3대 검색 원칙 모두 수행 가능, 100개 이상의 다국어 최적화 | Matryoshka 표현 학습으로 성능 저하 없이 차원 축소 가능, 압도적인 범용 성능 | Text-to-Text 검색 환경에서 일관되게 높은 정확도, RAG 파이프라인의 오픈소스 표준 | 엔터프라이즈 환경 특화, RAG용 문서-질의 비대칭 환경 매칭에 매우 강력함 | 완전 개방형(학습 데이터/코드 모두 공개), 8192 토큰의 매우 긴 컨텍스트 윈도우 지원 |
임베딩 모델 서빙 프레임워크
| 구분 | TEI (Text Embeddings Inference) | Infinity |
|---|---|---|
| 기반 언어 및 구조 | Rust | Python (FastAPI) + C++ Backend (CTranslate2, ONNX, Torch) |
| 모델 호환성 | 낮음 (Hugging Face가 사전에 하드코딩으로 승인한 특정 모델 아키텍처만 실행 가능) | 매우 높음 (대부분의 트랜스포머 기반 모델 지원, 신규 아키텍처 적용이 유연함) |
| 지연 시간 (Latency) 및 속도 | 극도로 빠름 (Rust 기반의 낮은 오버헤드, FlashAttention 및 커스텀 CUDA 커널 적용) | 빠름 (연산 코어는 CTranslate2/ONNX를 사용하여 가속하나, 구조상 TEI보다 미세한 오버헤드 존재) |
| 동적 배치(Dynamic Batching) | 네이티브 지원 (트래픽 스파이크 시 토큰 처리 효율 극대화) | 지원됨 (비동기 큐 기반 배치 처리) |
| 다중 태스크 지원 | 텍스트 임베딩, 리랭킹(Cross-Encoder)에 집중 | 텍스트 임베딩, 리랭킹, 멀티모달(CLIP), 시맨틱 라우팅 등 다목적 활용 가능 |
| 권장 사용 환경 | TEI 지원 목록에 포함된 모델을 단일로 고정하고, 엔터프라이즈급 대규모 트래픽을 최소의 Latency로 서빙할 때 | BGE-M3와 같은 복잡한 아키텍처를 쓰거나, 여러 모델을 자주 교체하며 높은 호환성을 요구할 때 |
- BGE-m3 는 TEI 를 받지 않는다. BGE-m3 는 단일 신경망 연산 후 마지막 단계에서 Dense, Sparse, ColBERT 의 세 가지 형태의 값을 동시에 계산하여 반환하는 특수한 구조(Head)를 가진다. TEI 의 규격에서 벗어나므로,
/sparse_embed와 같은 엔드포인트 호출시 에러가 난다. - BGE-m3 는 inifinity 도 받지 않는다. 올릴수는 있는데 infinity 에서 sparse 벡터 리턴을 지원을 안한다.
- BGE-m3 를 올리고 서버단에서 서빙하려면 간단한 api 래핑 코드를 수제로 작성해야 한다.
embedding / encoder
- SPARSE_EMBEDDING_MODEL
- SPARSE_ENCODER_MODEL
실무와 학계(NLP/정보검색 분야)에서 이 두 용어는 거의 95% 이상 같은 대상을 가리키며 상호호환적으로 (Interchangeably) 사용되지만, 맥락/문맥에 따라 때로는 물리적 실체에 가끔 차이가 있음.
자연어 처리(NLP)와 RAG 시스템에서 정보를 검색하기 위해서는 결국 문서를 벡터로 변환하는 ‘인코더(Encoder)’ 장치가 필요하고, 그 결과물이 ‘임베딩(Embedding)‘이기 때문입니다. 결국 산출물과 산출과정 중 어디에 집중하냐의 차이일 뿐, 일반적으로는 사실상 구분하지 않음. 양쪽 모두 둘 다 SPLADE, ELSER, BGE-M3의 희소 검색 모듈과 같이 “문맥을 반영한 단어 가중치(Sparse Vector)를 뽑아내는 모델”을 의미.
| 구분 | SPARSE_EMBEDDING_MODEL (희소 임베딩 모델) | SPARSE_ENCODER_MODEL (희소 인코더 모델) |
|---|---|---|
| 핵심 초점 | 출력 데이터 (Output/Representation) 에 집중 | 네트워크 구조 및 기능 (Architecture/Process) 에 집중 |
| 결과물(데이터)의 형태에 이름붙임 | 그 결과물을 만들어내는 기계(신경망 구조)에 이름붙임 | |
| 의미 | 결과물로 ‘희소 벡터(Sparse Vector)‘를 뱉어내는 모델임을 강조 | 텍스트를 희소 표현으로 ‘인코딩(변환)‘하는 신경망임을 강조 |
| 대비되는 개념 | Dense Embedding Model (밀집 임베딩 모델) | Dense Encoder Model (밀집 인코더 모델) |
| 직관적 비유 | ”이 공장의 산출물은 희소 임베딩이다.” (생성물 중심) | “이 기계는 자연어 입력을 받아서 희소 형태로 압축하는 인코더다.” (동작 중심) |
| “SPLADE는 성능 좋은 Sparse Encoder Model이다.” (모델의 인코딩 동작을 설명할 때) | “SPLADE는 Sparse Embedding Model로서 하이브리드 검색에 유용하다.” (출력 벡터를 인덱싱하고 저장하는 관점을 설명할 때) | |
| 실무적 맥락 | 출력 벡터를 인덱싱하고 저장하는 관점 설명 시 주로 사용 | 모델의 인코딩 동작 자체를 설명 시 주로 사용 |
단, 인공지능 ‘해석 가능성 연구(Interpretability, SAE)’ 분야의 맥락이면 차이가 있음.
- Sparse Autoencoder (SAE, 희소 오토인코더): 거대 언어 모델(LLM) 내부의 뉴런 활성화 값(Activation)을 분석하여 모델이 어떤 개념을 이해하고 있는지 인간이 해석할 수 있도록 분해해 주는 특수한 ‘연구용 모델’을 의미함
- 이 영역에서는 이를 Embedding 모델이라 부르지 않고 오직 Encoder/Decoder 관점으로만 부름