지도학습
로지스틱 회귀(Logistic Regression)는 종속변수가 범주형(주로 이항 0 또는 1)일 때 사용하는 분류 알고리즘이다. ADP 실기 시험에서 데이터 분류 문제에 가장 기본적으로 사용되며 베이스라인 모델로 자주 요구된다. 알아야 할 핵심 개념은 다음과 같다.
- 오즈(Odds)와 로짓(Logit) 변환 오즈(Odds)는 사건이 발생할 확률(p)이 발생하지 않을 확률(1−p)의 몇 배인지를 나타내는 값이다.
오즈 수식:
선형 회귀 방정식의 우변은 (−∞,∞) 범위를 가지지만, 확률 p는 의 범위를 가진다. 이 범위를 맞추기 위해 오즈에 자연로그를 취하는 로짓(Logit) 변환을 수행하여 선형 회귀 모델과 연결한다.
- 로짓 변환 수식:
- 시그모이드 함수(Sigmoid Function) 위의 로짓 방정식을 확률 p에 대해 정리하면 시그모이드 함수가 도출된다. 이 함수는 입력된 독립변수들의 선형 결합 값을 0과 1 사이의 비선형적인 확률값으로 변환(S자 곡선)한다. 모델이 도출한 확률값이 임계값(기본 0.5) 이상이면 1, 미만이면 0으로 분류한다.
- 시그모이드 수식:
-
최대우도추정법(Maximum Likelihood Estimation, MLE) 선형 회귀는 오차의 제곱합을 최소화하는 최소제곱법(OLS)을 사용하지만, 로지스틱 회귀는 종속변수가 이항 분포를 따르므로 오차의 정규분포를 가정할 수 없다. 따라서 주어진 데이터 관측치들이 나타날 확률(우도)을 최대화하는 파라미터(β)를 찾는 최대우도추정법(MLE)을 통해 최적화한다. 주로 계산의 편의를 위해 Log-Likelihood를 사용한다.
-
모델 평가 지표 연속형 변수를 예측하는 것이 아니므로 MSE, RMSE 등의 지표를 사용할 수 없다. 혼동 행렬(Confusion Matrix)을 기반으로 성능을 평가한다. 클래스 불균형(Class Imbalance)이 심한 경우 정확도(Accuracy)보다 F1-점수나 ROC-AUC를 중점적으로 확인해야 한다.
import pandas as pd; import seaborn as sns
df = sns.load_dataset('iris')
df = df.loc[:99]
df = pd.get_dummies(df, drop_first=True)
from sklearn.model_selection import train_test_split
X = df.drop('species_versicolor', axis=1)
y = df['species_versicolor']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
from sklearn.preprocessing import StandardScaler
stdscaler = StandardScaler()
stdscaler.fit(X_train)
X_train_scaled = stdscaler.transform(X_train)
X_scaled = stdscaler.transform(X_train)
X_test_scaled = stdscaler.transform(X_test)| 모델명 | 핵심 원리 | 장점 | 단점 및 한계 | 의존도 | 주요 | 튜닝 민감도 |
|---|---|---|---|---|---|---|
| 로지스틱 회귀 | 시그모이드 함수를 통한 확률 변환, 로그 오즈(Log-odds) 선형 결합 | 해석 용이성, 계수 기반 변수 영향력 설명, L1/L2 정규화 가능 | 선형 분리 가능 데이터에 국한, 다중공선성에 민감 | 중 | C (Regularization strength), penalty | 중간 (규제 강도에 따라 변동) |
| 나이브 베이즈 | 베이즈 정리 기반, 특성 간 독립성 가정, 사후 확률 최대화 | 계산 속도 매우 빠름, 대용량/텍스트 데이터 효율적 | 변수 간 상관관계 무시, 연속형 데이터 처리 시 가우시안 가정 필요 | 극하 | (Smoothing) | 거의 없음 |
| SVM | 마진(Margin) 최대화 초평면 탐색, 커널 트릭을 통한 고차원 매핑 | 고차원 데이터 성능 우수, 비선형 분류 가능 | 대규모 데이터에서 속도 저하, 메모리 사용량 큼, 파라미터 튜닝 복잡 | 최상 | C, kernel, gamma | 매우 높음 (스케일링 및 커널 필수) |
| 결정트리 | 정보이득/지니지수 기준 데이터 분할, 재귀적 분기 | 결과 시각화 및 직관적 해석 가능, 비모수적 모델 | 과적합 발생 가능성 높음, 데이터 변화에 민감(불안정성) | 상 | max_depth, min_samples_split | 높음 (과적합 위험 매우 높음) |
| 랜덤 포레스트 | 배깅(Bagging) 기반 다수 결정트리 앙상블, 무작위 특징 선택 | 과적합 억제력 강함, 높은 범용적 성능 | 개별 트리 해석 어려움, 계산 자원 및 메모리 소모 큼 | 하 | n_estimators, max_features | 낮음 (기본값 우수) |
| XGBoost | 그래디언트 부스팅(GBM) 기반, 정규화(Regularization) 포함 | 매우 높은 예측 성능, 병렬 처리 및 효율적 자원 사용 | 하이퍼파라미터 튜닝 난이도 높음, 학습 시간 다소 소요 | 최상 | learning_rate, max_depth, num_leaves | 매우 높음 (미세 튜닝 필수) |
| LightGBM | 리프 중심 트리 성장(Leaf-wise), GOSS/EFB 알고리즘 활용 | 학습 속도 매우 빠름, 메모리 사용량 최소화 | 소량 데이터에서 과적합 위험, 복잡한 파라미터 조정 필요 | 최상 | learning_rate, max_depth, num_leaves | 매우 높음 (미세 튜닝 필수) |
| Catboost | 하 | depth, learning_rate, iterations | 낮음 (기본값 최적화 우수) | |||
| 신경망(MLP) | 다층 퍼셉트론 구조, 역전파(Backprop) 기반 비선형 관계 학습 | 복잡한 비선형 패턴 학습 가능, 유연한 모델 구조 | 대규모 데이터 성능 저하 가능성, 블랙박스 모델(해석력 부재) | 최상 | hidden_layers, lr, optimizer, batch_size | 극도로 높음 (구조 설계 자체에 의존) |
- 는 하이퍼패러미터
- 로지스틱
확률 p가 0에서 1 사이의 범위를 가질 때, 오즈는 0에서 무한대(∞)의 범위를 가진다. 선형 회귀모형의 가정상 우변(독립변수의 선형결합)은 의 범위를 가지므로, 좌변의 종속변수도 이와 동일한 범위를 갖도록 맞춰주어야 한다. 이를 위해 오즈에 자연로그를 취하는 로짓 변환(Logit Transformation) 을 수행한다.
오즈비는 두 오즈의 비율이다. 다중 로지스틱 회귀모형에서 오즈비는 나머지 모든 통제 변수가 고정되어 있을 때, 특정 관심 독립변수 X1 이 1단위 증가함에 따라 변화하는 ‘사건 발생 오즈’의 비율을 의미한다.
즉, 모델을 적합시킨 후 도출된 변수 X1 의 회귀계수 β1 에 지수함수(exponential)를 취한 값() 이 해당 변수의 오즈비가 된다. 이 오즈비 값을 통해 독립변수가 종속변수에 미치는 영향의 방향과 크기를 해석한다.
-
XGBoost나 LightGBM이 하이퍼파라미터 튜닝(특히 학습률, 트리 깊이 등)에 극도로 민감한 것과 대조적으로, CatBoost는 대칭 트리(Symmetric Trees) 구조와 정렬된 부스팅(Ordered Boosting) 기법을 사용하여 타겟 누수(Target Leakage)를 원천적으로 방지한다.
- 논문 및 실험 결과에 따르면, 튜닝을 거치지 않은 기본 파라미터 상태에서 다른 GBM 기반 모델들(튜닝 전)을 압도하며, 튜닝 후의 다른 모델 성능과도 거의 유사한 결과를 낸다. 범주형 변수의 자동 처리 기능(Target Encoding)이 내장되어 있어 전처리 파라미터에 대한 고민도 줄여준다.
| 오즈비(OR) 범위 | 회귀계수() | 통계적 해석 |
|---|---|---|
| 양(+)의 관계. 가 1단위 증가할 때 사건 발생(Y=1) 오즈가 배 증가한다. | ||
| 독립. 의 변화가 사건 발생 오즈에 영향을 주지 않는다. | ||
| 음(-)의 관계. 가 1단위 증가할 때 사건 발생(Y=1) 오즈가 배로 감소한다. |
import numpy as np
if '로지스틱 회귀':
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
model.coef_ # 회귀계수
if '수동계산':
# 시그모이드 + 회귀계수로 모델예측확률 계산
def sigmoid(z):
return 1 / (1 + np.exp(-z))
z = np.dot(X_test, model.coef_.T) + model.intercept_
probabilities = sigmoid(z)
if '자동계산':
# [:, 0]은 음성, [:, 1]은 양성 클래스의 예측 확률을 반환한다
# 이는 probabilities 와 동일하다
model.predict_proba(X_test)[:, 1]
# 회귀계수의 지수값이 오즈비(odds ratio)로 해석됨
odds_ratios = np.exp(model.coef_)
# 예측되는 클래스 자체
y_pred = model.predict(X_test)
# X_constant = sm.add_constant(X)
# logit_model = sm.Logit(y, X_constant)
# # 3. 모형 적합 (최우추정법, Maximum Likelihood Estimation 사용)
# # method 파라미터로 최적화 알고리즘 변경 가능 (기본값: 'newton')
# logit_result = logit_model.fit()
# print(logit_result.summary())
#model = sm.Logit(y,X).fit(method='newton',maxiter=200,tol=1e-2)
# 오즈비>1, 오즈비=exp(beta)
# X j 가 1단위 증가할 때, 관심 사건이 발생할 오즈가 [OR 값]배 증가한다."
# 오즈비<1
# X j 가 1단위 증가할 때, 관심 사건이 발생할 오즈가 [OR 값]배로 감소한다."
if '나이브 베이즈':
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
if 'SVM, 서포트 벡터 머신':
from sklearn.svm import SVC, SVR # 각각 분류, 회귀
model = SVC()
model = SVC(probability=True) # predict_proba 사용
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
model.support_vectors_ # 서포트 벡터 확인
# decision_values = model.decision_function(X_test) # 결정 함수 값 확인
model.decision_function(X_test) # 결정 함수 값 확인
model.coef_ if model.kernel == 'linear' else None # 선형 커널의 초평면 가중치 확인
if '결정 트리':
from sklearn.tree import plot_tree #트리 시각화
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
model.feature_importances_ # 특징 중요도 확인
model.predict_proba(X_test) # 클래스별 예측 확률 확인
model.get_depth() # 트리의 깊이 확인
"""
==============================================================================================
!!!!!!!!!!!!!!!!!!!!아래는 앙상블임!!!!!!!!!!!!!!!!!!!!
==============================================================================================
"""
from sklearn.ensemble import GradientBoostingClassifier
if '랜덤 포레스트':
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
model.feature_importances_ # 각 특징의 중요도 확인
model.predict_proba(X_test) # 모든 결정 트리의 예측값 확인
len(model.estimators_) # 전체 결정 트리 개수 확인, n_estimators로도 확인 가능, n_trees
# 특정 트리 선택하여 예측값 확인, 이 경우에는 1번째 트리, single_tree_pred
model.estimators_[0].predict(X_test)
if 'XGBoost':
from xgboost import XGBClassifier, XGBRegressor, plot_tree
model = XGBClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
model.feature_importances_ # 각 특징의 중요도 확인
model.get_booster().best_iteration # 학습된 모델의 부스팅 라운드 수 확인, n_rounds
# 특정 예측 확률 확인, probas, predict_proba는 클래스별 확률을 반환하므로,
# 특정 클래스의 확률을 확인하려면 [:, class_index] 형태로 접근해야 함
model.predict_proba(X_test)
# 학습 과정에서의 손실 값 확인, history, get_dump()는 모델의 트리 구조와 함께
# 각 트리의 정보(예: split_gain, internal_value 등)를 포함한 리스트를 반환함
model.get_booster().get_dump()
if 'LightGBM':
from lightgbm import LGBMClassifier, LGBMRegressor, plot_tree # sklearn plot_tree와 다름
model = LGBMClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
model.feature_importances_ # 각 특징의 중요도 확인
model.n_estimators # 모델의 부스팅 라운드 수 확인, n_rounds
model.predict_proba(X_test) # 예측 확률 확인, probas
# 모델 예측 결과의 기본 통계 확인, stats, raw_score=True로 설정하면
# 예측 확률 대신 트리의 출력값(로그 오즈)을 반환함
model.predict(X_test, raw_score=True)
if '신경망':
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(hidden_layer_sizes=(100,), max_iter=500, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
weights = model.coefs_ # 각 은닉층의 가중치 확인
biases = model.intercepts_ # 각 은닉층의 편향 확인
loss_values = model.loss_ # 학습 과정에서의 손실 값 확인
probas = model.predict_proba(X_test) # 예측 확률 확인
n_layers = model.n_layers_ # 모델의 은닉층 수 확인
if ['결정 트리', '랜덤 포레스트', 'XGBoost', 'LightGBM']:
plt.figure(figsize=(10, 8))
# '결정 트리'
sklearn.tree.plot_tree(
model, filled=True, feature_names=feature_names_list
, class_names=target_names_list
)
# '랜덤 포레스트', 하나의 결정 트리 시각화 (첫 번째 트리 선택)
sklearn.tree.plot_tree(
model.estimators_[0], filled=True
, feature_names=data.feature_names, class_names=data.target_names
)
# 'XGBoost', 첫 번째 트리 시각화
# num_trees=0은 첫 번째 트리를 의미 , graphviz 에러가 날 수도 있음
xgboost.plot_tree(model, num_trees=0, fontsize=10)
# 'LightGBM', 첫 번째 트리 시각화
lightgbm.plot_tree(model, tree_index=0, figsize=(10, 8), show_info=['split_gain', 'internal_value'])
plt.show()
voting
앙상블 기법 중 하나
- 여러개의 분류 모델을 결합 (분류 모델 종류 자체가 다름)
- 모델 각각의 장점을 활용하여 성능 향상
| 구분 | 하드 보팅 (Hard Voting) | 소프트 보팅 (Soft Voting) |
|---|---|---|
| 작동 원리 | 다수결 투표: 각 분류기가 예측한 클래스 중 가장 많이 득표한 클래스를 최종 선택 | 확률 투표: 모든 분류기가 예측한 클래스별 확률의 평균을 구한 뒤, 평균 확률이 가장 높은 클래스 최종 선택 |
| 통계적 관점 | 최빈값 (Mode) 추출 | 확률값의 산술 평균 (Arithmetic Mean) 계산 |
| 주요 특징 | 개별 모델의 예측 확률(확신도)을 무시하고 라벨 결과값만 집계 | 모델별 확신도를 반영하며, 일반적으로 하드 보팅보다 우수한 성능을 냄 (VotingClassifier에서도 권장) |
| 장점 | 특정 모델의 극단적인 오답 확률에 영향을 받지 않음 (강건성), 확률 출력이 없는 모델도 결합 가능 (범용성) | 확신이 높은 모델에 가중이 실려 일반적 성능 우수 (정밀성), 매끄러운 결정 경계(Decision Boundary) 생성 (유연성) |
| 단점 | 모델의 확신도(Confidence) 정보를 무시 (정보 손실), 결과가 박빙일 때 논리적 판단 근거 부족 (단순성)결과가 박빙일 때 논리적 판단 근거 부족 | 확률 보정(Calibration)이 안 된 모델의 극단적 값에 결과가 왜곡될 위험 (편향 취약), 확률 출력이 필수적임 (제약) |
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import VotingRegressor
# 분류
model1 = LogisticRegression()
model2 = DecisionTreeClassifier()
model3 = SVC(probability=True)
# soft : 확률 평균 / hard : 레이블 다수결
voting_clf = VotingClassifier(
estimators=[('lr', model1), ('dt', model2), ('svc', model3)]
, voting='soft'
)
voting_clf.predict(test)
# 회귀 / 모델들의 예측값의 평균
model1 = LinearRegression()
model2 = DecisionTreeRegressor()
model3 = SVR()
voting_regressor = VotingRegressor(
estimators=[('lr', model1), ('dt', model2), ('svr', model3)]
)
voting_regressor.predict(test)
평가 (분류/회귀)
분류모델
- 클래스 불균형 상황
| 함수명 | 용도 및 핵심 개념 | 주요 사용 상황 (시험 대응) | |
|---|---|---|---|
sklearn.metrics | confusion_matrix | 예측 결과와 실제 값을 교차 표로 정리 | 오분류의 양상(FP, FN 중 어디에 치우쳤는지) 파악 |
| accuracy_score | 전체 중 맞춘 비율 | 클래스 분포가 균형 잡힌 데이터의 기본 평가 | |
| precision_score | 양성 예측 중 실제 양성 비율 | **Type I Error(FP)**를 낮추는 것이 중요할 때 (스팸 분류 등) | |
| recall_score | 실제 양성 중 양성 예측 비율 | **Type II Error(FN)**를 낮추는 것이 중요할 때 (암 진단 등) | |
| f1_score | 정밀도와 재현율의 조화 평균 | 클래스 불균형이 심할 때 모델의 전반적인 성능 평가 | |
| string 형식, print() | classification_report | 주요 지표를 한 번에 문자열로 반환 | 전반적인 성능을 일목요연하게 보고서 형태로 출력 |
| roc_curve | 임계값 변화에 따른 TPR, FPR 변화량 | 최적의 임계값(Threshold)을 찾기 위한 시각화 기초 자료 | |
| roc_auc_score | ROC 곡선 아래 면적 | 모델의 변별력(Discrimination)을 단일 수치로 평가 | |
| auc | 주어진 곡선 아래 면적 계산 | roc_curve 등으로 구한 x, y 좌표를 바탕으로 면적 산출 | |
| predict_proba | 클래스별 예측 확률값 반환 | AUC 계산 및 임계값 조정 시 필수 데이터 추출 |
| 구분 | 계산 기준 | 클래스 불균형 시 영향 | 활용 목적 |
|---|---|---|---|
| Macro F1 | 각 클래스별 F1 계산 후 단순 평균 | 소수 클래스의 성능 저하에 매우 민감함 | 소수 클래스 예측을 포함해 모든 클래스를 동등하게 평가할 때 |
| Micro F1 | 전체 데이터의 TP, FP, FN 총합 기반 계산 | 다수 클래스의 성능에 절대적으로 종속됨 | 전체적인 예측 성공 비율(Accuracy) 자체를 중시할 때 |
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import pandas as pd; import seaborn as sns
df = sns.load_dataset('iris')
y=df['species']; X=df.drop(columns='species')
# # y = y.map({'setosa': 0, 'versicolor': 1, 'virginica': 0})
# y = y.replace({'setosa': 0, 'versicolor': 1, 'virginica': 0})
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# 2. 모델 학습
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
if 'confusion matrix':
import matplotlib.pyplot as plt; plt.clf()
from sklearn.metrics import (ConfusionMatrixDisplay
, confusion_matrix, multilabel_confusion_matrix)
cm = confusion_matrix(y_test, y_pred)
# tn, fp, fn, tp = cm.ravel()
# pd.DataFrame(cm, index=['real 0','real 1'], columns=['pred 0', 'pred 1'])
mcm = multilabel_confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(cm, display_labels = [0,1,2,3,4])
disp.plot()
plt.show()
if 'AUC 계산의 인풋인 예측확률 계산':
# 양성 클래스의 예측확률 계산 / 추출
# 주의: predict()가 아닌 predict_proba()를 사용해야 함
# y_score = model.predict_proba(X_test)[:, 1]
y_pred_proba = model.predict_proba(X_test)[:, 1]
if 'AUC 계산':
from sklearn.metrics import roc_auc_score
roc_auc_score_val = roc_auc_score(y_test, y_pred_proba, multi_class='raise')
if 'FPR TPR 기초값 수동생산 후 AUC':
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
auc_val = auc(fpr, tpr)
# roc_auc_score_val == auc_val
if 'ROC 커브':
import matplotlib.pyplot as plt; plt.clf()
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(4, 4))
# 완전 무작위 분류기(Random Guess)의 ROC 곡선 (AUC = 0.5 기준선)
# 모델의 ROC 곡선
ax.plot([0, 1], [0, 1], color='blue', linestyle='--', lw=1, label='완전무작위, Random Guess')
ax.plot(fpr, tpr, color='red', label=f'Model ROC curve (AUC = {roc_auc_score_val:.2f})')
ax.set(xlim=[0.0, 1.0], ylim=[0.0, 1.0])
ax.xlabel('False Positive Rate')
ax.ylabel('True Positive Rate')
plt.legend()
plt.grid()
plt.show()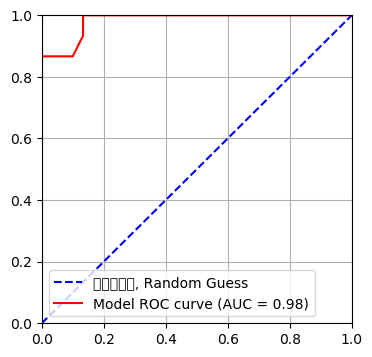
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, roc_auc_score
from sklearn.preprocessing import label_binarize
import numpy as np
y_pred_proba = model.predict_proba(X_test)
if '다중 클래스 AUC 계산':
from sklearn.metrics import roc_auc_score
macro_auc = roc_auc_score(y_test, y_pred_proba, multi_class='ovr', average='macro')
if '다중 클래스 FPR TPR 기초값 수동생산 후 AUC':
from sklearn.metrics import roc_curve, auc
classes = ['versicolor', 'setosa', 'virginica']
y_test_bin = label_binarize(y_test, classes=classes)
n_classes = y_test_bin.shape[1]
fpr,tpr,roc_auc = dict(),dict(),dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test_bin[:, i], y_pred_proba[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
if 'ROC 커브':
import matplotlib.pyplot as plt; plt.clf()
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(6, 6))
# 완전 무작위 분류기(Random Guess)의 ROC 곡선 (AUC = 0.5 기준선)
# 모델의 ROC 곡선
ax.plot([0, 1], [0, 1], color='gray', linestyle='--', label='완전무작위, Random Guess')
colors = ['blue', 'red', 'green']
for i, color in zip(range(n_classes), colors):
ax.plot(fpr[i], tpr[i], color=color, lw=2,
label=f'ROC curve of class {i} (area = {roc_auc[i]:0.2f})')
ax.set(xlim=[0.0, 1.0], ylim=[0.0, 1.0])
ax.set_xlabel('False Positive Rate')
ax.set_ylabel('True Positive Rate')
# ax.set_title('Receiver Operating Characteristic (Multi-class)')
ax.set_title('ROC (Multi-class)')
plt.legend(loc="lower right")
plt.tight_layout()
plt.show()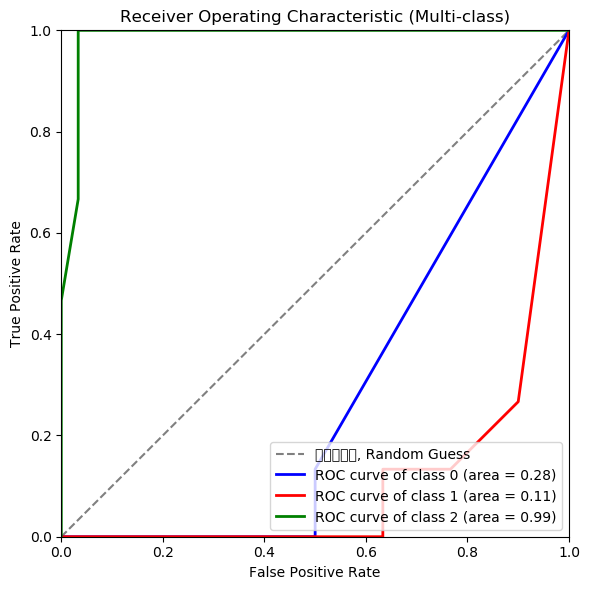
회귀모델 평가
| 지표 (함수명) | 통계적 의미 | 주요 사용 상황 (시험 및 실무 대응) | |
|---|---|---|---|
sklearn.metrics | MAE (mean_absolute_error) | 잔차의 절댓값 평균 (L1 Loss) | 오차를 직관적으로 해석해야 할 때, 이상치(Outlier)의 영향을 적게 받고 싶을 때 |
MSE (mean_squared_error) | 잔차의 제곱 평균 (L2 Loss) | 오차가 클수록 모델에 더 큰 페널티를 부여해야 할 때 (이상치에 민감함) | |
RMSE (rmse 등) | MSE의 제곱근 | 오차의 단위를 **실제 타겟 변수와 동일한 척도(Scale)**로 맞춰 직관성을 높일 때 | |
MSLE (mean_squared_log_error) | 로그를 취한 오차의 제곱 평균 | 타겟 변수가 기하급수적으로 클 때, 과소평가(Under-prediction)에 더 큰 페널티를 줄 때 | |
R2 Score (r2_score) | 결정 계수 (설명력) | 모델의 성능을 종속 변수의 분산 대비 **상대적인 비율(0~1)**로 파악하고자 할 때 |
- RMSE 값은 약 5.6이었다. 이는 모델이 예측할 떄 실제값과의 차이가 약 5.6 정도 난다는 의미이다.
if 'RMSE':
import numpy as np
from sklearn.metrics import mean_squared_error
# RMSE 계산
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
if 'r2_score':
from sklearn.metrics import r2_score
r2 = r2_score(y_test, y_pred)
# 혹은
# model.score(X_test_scaled, y_test)변수선택
선택된 특성을 이용한 모델 성능 평가
- 예를 들어, 선택된 특성만을 사용하여 X_train, X_test를 재구성하고 모델을 재훈련한 후 성능을 평가할 수 있다.
| 분류 | 기법명 (Method) | 핵심 개념 및 주요 사용 상황 |
|---|---|---|
| Filter | VIF (Variance Inflation Factor) | 모델 학습 전 독립 변수 간의 다중공선성을 진단. 보통 VIF가 10 이상인 변수를 제거할 때 사용한다. |
| Wrapper | Forward Selection (전진 선택법) | 상수항만 있는 모델에서 시작해, 타겟 변수에 가장 큰 영향을 미치는 유의한 변수를 하나씩 추가한다. 변수가 매우 많을 때 연산량을 줄이기 위해 쓴다. |
| Wrapper | Backward Elimination (후진 제거법) | 모든 변수가 포함된 모델에서 시작해, 가장 유의하지 않은(p-value가 높은) 변수를 하나씩 제거한다. 변수 간의 상호작용을 고려하기 좋다. |
| Wrapper | Stepwise Selection (단계적 선택법) | 전진 선택과 후진 제거를 교대로 수행. 변수를 추가한 뒤 기존 변수들의 유의성을 다시 검정하여 불필요해진 변수를 제거한다. ADP에서 가장 빈출되는 전통적 통계 기법이다. |
| Embedded | Lasso (L1 Regularization) | 회귀 계수의 절댓값 합에 페널티를 부여하여, 덜 중요한 변수의 회귀 계수를 0으로 만든다. 고차원 데이터에서 자동 변수 선택이 필요할 때 사용한다. |
| Embedded | Tree-based Importance | Random Forest, Gradient Boosting 등의 알고리즘에서 제공하는 feature_importances_ 속성을 기준으로 변수를 선택한다. |
| 파라미터 설정 | 기법명 (Method) | 머신러닝 관점의 작동 방식 |
|---|---|---|
forward=True, floating=False | SFS (Sequential Forward Selection) | 빈 집합에서 시작. 모델 교차 검증 성능을 가장 높이는 변수를 매 턴마다 하나씩 추가. |
forward=False, floating=False | SBS (Sequential Backward Selection) | 전체 변수 집합에서 시작. 제거했을 때 모델 성능 저하가 가장 적은(또는 향상되는) 변수를 하나씩 제거. |
forward=True, floating=True | SFFS (Sequential Forward Floating Selection) | SFS 수행 중, 매 단계마다 조건부 Backward 단계를 추가하여 ‘이미 추가된 변수를 뺐을 때 성능이 더 좋은지’ 재평가하여 덫(Local Optima)에 빠지는 것을 방지. |
forward=False, floating=True | SBFS (Sequential Backward Floating Selection) | SBS 수행 중, 매 단계마다 조건부 Forward 단계를 추가하여 ‘이미 제거된 변수를 다시 넣었을 때 성능이 더 좋은지’ 재평가. |
import numpy as np; import pandas as pd
import sklearn
housing = sklearn.datasets.fetch_california_housing()
df = pd.DataFrame(housing.data, columns=housing.feature_names)
df['target'] = housing.target
# =================================================================
#
# =================================================================
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
X = df.drop(columns='target')
y = df['target']
lr = LinearRegression()
sfs = SFS(lr,
k_features=5, # 선택할 피쳐 수
forward=False, # 전진선택/후진선택
floating=True, # 단계별 선택 여부 (on/off)
scoring='neg_mean_squared_error', # 평가지표
cv=0) # 교차 검증 횟수, 0일 경우 사용 안함
sfs = sfs.fit(X, y)
# 최종적으로 선택된 피쳐 확인
selected_features = list(sfs.k_feature_idx_)
from xgboost import plot_importance
plot_importance(model, importance_type='gain', max_num_features=10)sklearn 에서 sm 스타일로 모형 작성
from patsy import dmatrices
from sklearn.linear_model import LinearRegression
# 1. 수식을 사용하여 데이터 분리 및 행렬 변환
# 'y ~ x1 + x2 + x1:x2' (상호작용 포함)
y, X = dmatrices('target ~ feature1 * feature2', data=df, return_type='dataframe')
# 2. sklearn 모델에 입력
model = LinearRegression()
model.fit(X, y)