attention
| 구분 | 어텐션 (Attention) | 어텐션 메커니즘 (Attention Mechanism) |
|---|---|---|
| 의미 | 모델이 입력 데이터의 특정 부분에 ‘주의’를 기울이는 상태 또는 개념 | 쿼리(Query), 키(Key), 값(Value) 등을 이용해 가중치를 계산하는 알고리즘 |
| 관점 | 결과론적 관점: “모델이 이 단어를 중요하게 봤구나!” | 구조적 관점: “닷-프로덕트(Dot-product)를 써서 점수를 냈구나!” |
| 유래 | 인간의 인지 능력(여러 정보 중 필요한 것만 골라 집중하는 능력) | 신경망 기계 번역(NMT)에서 긴 문장을 처리하기 위해 설계된 기술적 장치 |
- Attention: “중요한 것에 집중하자”라는 현상 또는 능력(What)
- 전통적인 RNN 기반 seq2seq에서 사용하던 ‘Attention’을 Transformer 구조로 넘어오면서 Self-Attention과 구분하기 위해 Cross-Attention 으로 지칭
- Attention Mechanism: 그 능력을 구현하기 위한 수학적 계산 방식(How)
입력에 대해 특정한 가중치를 부여하여 입력의 다른 요소들과의 상호작용에 대한 중요도를 계산하는 메커니즘
- 주로 딥러닝 모델의 시퀀스 관련 작업에서 활용되는 기술
- 특히 자연어 처리(Natural Language Processing, NLP)에서 널리 사용
- 자연어 처리, 기계 번역, 이미지 캡셔닝 등 다양한 시퀀스 관련 작업에서 좋은 성능
- 최근에는 transformer 와 같은 모델에서 핵심 구성 요소로 널리 활용
특징
- 상호작용 중요도 계산
- 주어진 입력에서 각 요소들 간의 상호작용에 대한 중요도를 계산
- 주로 유사도(similarity)나 거리(distance)를 기반으로 계산
- 가중치 부여
- 계산된 상호작용 중요도에 따라 입력의 각 요소들에 가중치를 부여
- 가중치는 주로 소프트맥스(softmax) 함수를 사용하여 정규화
- 문맥 정보 획득
- Attention은 입력의 다른 요소들과 상호작용을 통해 문맥 정보를 획득하는데 유용
- 이를 통해 모델은 입력에 있는 중요한 정보들을 강조하고, 불필요한 정보를 무시
기본 종류 2가지
정보를 가져오는 ‘대상(Source)’ 이 누구인가에 초점
- Cross-Attention
- 입력 시퀀스와 다른 시퀀스 (예: 번역 작업에서 입력 문장과 번역 문장) 사이의 상호작용을 계산하는 기술
- Seq2Seq 모델과 같은 작업에서 활용 -
- Self-Attention
- 주어진 입력 시퀀스 내의 각 요소들 사이의 상호작용을 계산하는 기술
- 하나의 문장 내에서 단어들끼리 서로를 참조 (입력 시퀀스 내부)
- Transformer에서 주로 사용
- 주어진 입력 시퀀스 내의 각 요소들 사이의 상호작용을 계산하는 기술
scope 관점에서의 구분
정보를 훑어보는 ‘범위(Scope)’ 가 어디까지인가에 초점
- local Attention
- Global Attention
- 시퀀스 내에서 ‘모든 위치’ 를 다 살펴본다
- 예시)
- RNN 기반 NMT (Luong et al., 2015): 인코더의 모든 숨겨진 상태(Hidden States)를 고려하면 ‘글로벌’, 특정 윈도우(부분)만 고려하면 ‘로컬’ 이라고 지칭
- 효율적 트랜스포머 (Longformer, BigBird 등): 문장이 너무 길어 모든 단어를 다 계산하기 힘들 때(O(n2)), 중요한 몇몇 토큰(예:
[CLS])만 전체를 다 보게 설정하는데 이를 ‘글로벌 어텐션 토큰’이라고 지칭칭
attention mechanism
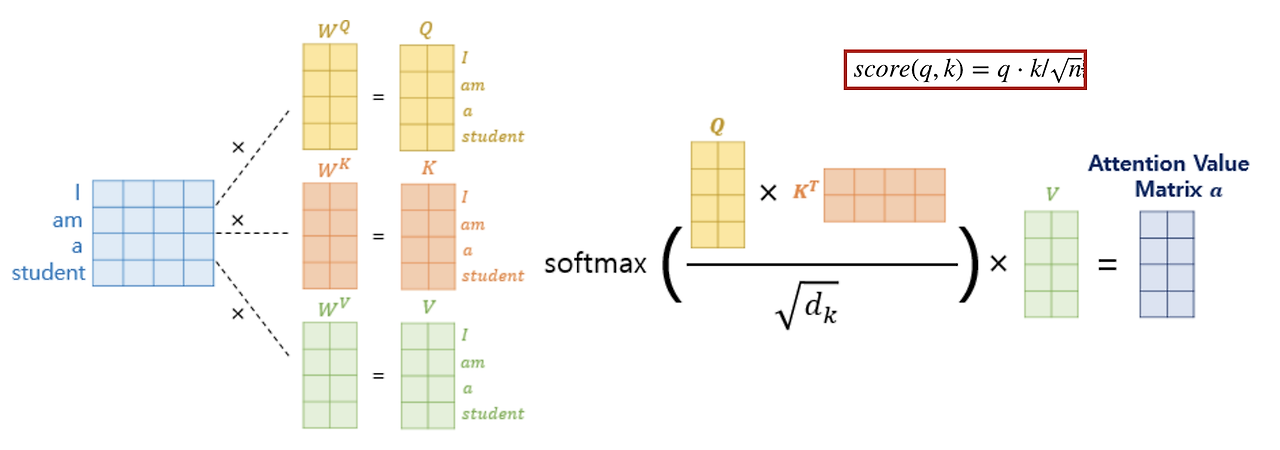
입력 시퀀스의 모든 위치에 대해 각각의 위치가 출력 시퀀스의 어떤 위치에 얼마나 영향을 미치는지를 계산하는 방법 이를 통해 모델은 입력 시퀀스의 중요한 정보에 집중하며, 장기의존성 문제를 해결 가능
구성요소
- attention score
- 현재 디코더의 시점 에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현 시점의 은닉 상태와 얼마나 유사한지를 판단하는 스코어값
- attention distribution
- attention score에 softmax를 적용한 확률 분포.
- attention weight
- attention distribution의 각각의 값.
- attention value
- 각 인코더의 은닉 상태 attention weight값
- 인코더의 문맥을 포함하고 있다고 하여 context vector라고도 불린다.
- 참고로 seq2seq에서는 인코더의 마지막 은닉 상태를 컨텍스트 벡터라고 부른다.
어텐션의 정보출처
- 크로스 어텐션 (Cross-Attention)
두 개의 서로 다른 시퀀스 사이의 관계를 파악할 때 사용
- 핵심: Query는 A 시퀀스에서, Key와 Value는 B 시퀀스에서 가져온다
- 대표 사례: 트랜스포머의 디코더가 인코더의 출력값을 참조할 때 사용
- (번역할 때 번역중인 단어가 원문의 어떤 단어와 연관 있는지 확인)
- 비유: 영어 문장을 보면서(Key/Value) 한국어 문장을 쓰는(Query) 상황
| 구분 | Attention (Cross) | Self-Attention |
|---|---|---|
| 관점 | 외부 참조 (타겟 ↔ 소스) | 내부 참조 (소스 ↔ 소스) |
| 번역기(NMT)를 예로 들면, “현재 번역 중인 단어(Q)가 원문(K,V)의 어디를 참고해야 할까?” 를 결정하는 과정 | 문장 내에서 단어들끼리의 관계를 파악하는 과정, “문장 안에서 이 단어가 다른 단어들과 어떤 관계를 맺고 있지?”를 스스로 묻고 답하는 과정 | |
| 비유 | 원문에 이 단어가 있었는데, 지금 번역할 단어랑 관련 있어? | 이 문장 안에서 이 단어는 저 단어랑 친해. |
| 위치 | 인코더와 디코더의 사이(다리 역할) | 인코더 내부 혹은 디코더 내부 |
| 서로 다른 두 시퀀스(원문과 번역문) 사이의 연결 고리 역할 | ”The animal didn’t cross the street because it was too tired”에서 ‘it’이 ‘animal’임을 알아내는 것처럼, 문장 내부의 문맥적 의미를 풍부하게 만든다. |
| cross-attention | self-attention | |
|---|---|---|
| Q (query) | 모든 시점의 디코더 셀에서의 은닉 상태 ”다음에 나올 단어는 무엇이지?”라고 묻는 주체 | 입력 문장의 모든 단어 벡터들 |
| K (key) | 모든 시점의 인코더 셀의 은닉 상태들 번역해야 할 원래 문장(원본 정보)의 데이터베이스 | 입력 문장의 모든 단어 벡터들 |
| V (value) | 모든 시점의 인코더 셀의 은닉 상태들 번역해야 할 원래 문장(원본 정보)의 데이터베이스 | 입력 문장의 모든 단어 벡터들 |
| 하나의 입력 벡터 행렬에 서로 다른 가중치 행렬(, , )을 곱해 Q,K,V를 각각 만든다. |
self-attention
입력 시퀀스 내의 각 요소가 서로 어떤 관련성을 가지는지를 계산하는 메커니즘
- 각 요소 (단어, 토큰, 또는 벡터) 들은 자신과 다른 요소들 사이의 상관 관계를 계산하여 중요도를 가중치로 표현
- 이렇게 각 요소마다 자신과의 관련성에 대한 가중치를 얻은 후, 이를 사용하여 다른 요소들과의 가중합을 계산
- transformer의 인코더와 디코더는 여러 개의 층으로 구성되고, 각 층에서 Self-attention이 적용
특징
- 모든 요소 간의 상호작용
- Self-attention은 모든 요소들 간의 상호작용을 고려
- 따라서 긴 시퀀스에서도 먼 거리의 의존성을 파악하는 데 용이
- 병렬 처리 가능
- Self-attention은 각 요소 간의 관련성을 독립적으로 계산하므로, 병렬 처리가 가능
- 이는 효율적인 학습과 예측을 가능하게 한다
- 문맥 정보 포착
- 각 요소가 다른 모든 요소들과의 관계를 계산하므로, 문맥 정보를 포착하는 데 용이
- 이는 자연어 처리 작업에서 문장 내 단어들의 관련성을 잘 파악할 수 있도록 도움
multi-head attention
일반적인 어텐션은 입력 시퀀스의 모든 요소들 간의 상호작용을 계산하는데, 이를 하나의 어텐션 헤드로 처리
- 그러나 멀티 헤드 어텐션은 여러 개의 어텐션 헤드를 독립적으로 사용하여 여러 다른 선형 변환을 수행하고, 그 결과를 결합
- 어텐션 메커니즘을 한 번만 사용하는 것이 아니라, 여러 개(Head)를 병렬로 동시에 사용하여 다양한 측면의 문맥 정보를 포착하는 기술
동작
- 입력 시퀀스에 대해 여러 개의 어텐션 헤드를 생성합니다. 각 헤드는 가중치 행렬을 사용하여 다른 관점에서 상호작용을 계산합니다.
- 각 헤드마다 얻은 결과를 합치기 위해 선형 변환을 수행합니다. 이 때, 각 헤드의 결과에 대해 서로 다른 가중치를 사용합니다.
- 각 헤드가 추출한 서로 다른 문맥 정보를 다시 하나로 합쳐서(Concatenate), 합쳐진 결과를 최종 멀티 헤드 어텐션 결과로 사용합니다.
장점
- 다양한 정보 추출
- 각 헤드는 서로 다른 관점에서 상호작용을 계산하므로, 입력에 대해 다양한 정보를 추출할 수 있습니다.
- 병렬 처리 가능
- 각 헤드는 독립적으로 계산되므로, 병렬 처리가 가능합니다. 이는 모델의 학습과 예측을 더 효율적으로 만들어 줍니다.
- 효율적인 표현 학습
- 멀티 헤드 어텐션은 입력 시퀀스의 다양한 관점에서 상호작용을 수행하여 더 효과적인 표현 학습을 가능하게 합니다.