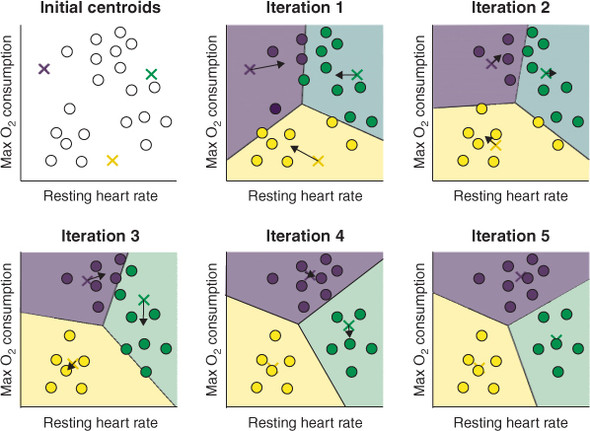
주어진 데이터를 개의 클러스터로 묶는 알고리즘
각 클러스터 간의 거리의, 분산을 최소화하는 식으로 동작
- 원하는 군집의 개수 와 초기 seed 정해 초기 seed 중심으로 군집 형성
- 각 데이터를 거리가 가장 가까운 seed 가 있는 군집으로 분류
- 각 군집의 seed 값을 다시 계산
- 모든 개체가 군집으로 할당될 때까지 위 과정 반복
| 장점 | 단점 |
|---|---|
| 알고리즘이 단순, 빠르게 수행되어 분석 방법 적요이 용이 | 군집의 수, 가중치, 거리 정의가 어려움 |
| 계층적 군집분석에 비해 많은 양의 데이터 다룰 수 있음 | 사전에 주어진 목적이 없으므로 결과 해석이 어려움 |
| 내부 구조에 대한 사전정보가 없어도, 의미있는 자료 구조를 찾을 수 잇음 | 잡음, 이상값의 영향을 많이 받음 |
| 다양한 형태의 데이터에 적용이 가능함 | non-convex (볼록한 형태가 아닌) 군집이 존재할 경우 성능 하락 (ex. U 형태의 군집) |
| 초기 군집수 결정에 어려움이 있음 |