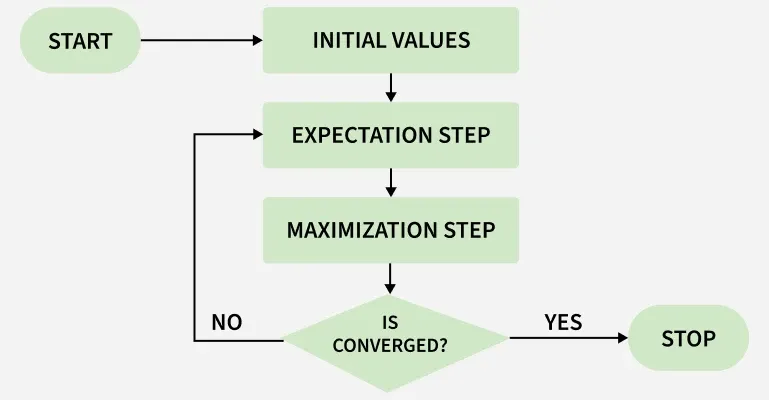
- 시작 전, 임의의 패러미터값즐 정한다.
- E 단계: 각 자료에 대해 잠재변수 Z 의 조건부분포로부터 잠재변수 Z 의 조건부 기댓값을 구할 수 있다.
- 조건부 분포는, 어느 집단에 속할지에 대한 조건부 분포 이다.
- M 단계: augmented 로그가능도함수에 대신 상수값인 의 조건부 기댓값을 대입하면, 로그가능도함수를 최대로 하는 모수를 쉽게 찾을 수 있다. 즉, 잠재변수 Z의 기댓값을 이용해 패러미터를 추정한다.
- augmented 로그가능도함수란, 관측변수 X 와 잠재변수 Z 를 포함하는 (X,Z) 에 대한 로그-가능도함수
- 갱신된 모수 추정치에 대해 위 과정을 반복한다면 수렴하는 값을 얻게 되고, 이는 최대 가능도 추정치로 사용될 수 있다. Likelihood 가 최대화된 값을 획득했다면 추정을 종료하고, 추정된 패러미터 추정값을 활용한다.
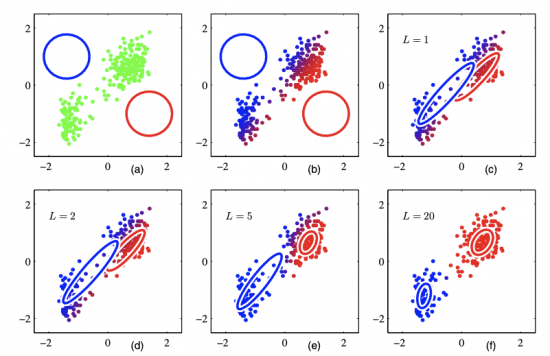
- KMC 의 절차와 유사하지만, 확률분포를 도입하여 군집을 수행한다.
- 군집을 몇개의 모수로 표현할 수 있으며, 서로 다른 크기나 모양의 군집을 찾을 수 있다.
- EM 알고리즘을 이용한 모수추정에서, 데이터가 커지면 수렴에 시간이 걸릴 수 있다.
- 군집의 크기가 너무 작으면 추정의 정도가 떨어지거나 어려울 수 있다.
- KMC 와 같이 이상치 자료에 민감하므로 사전에 조치가 필요하다.