-
데이터 마이닝, 통계분석과의 차이점
-
통계분석은 가설, 가정에 따른 분석이나 검증 진행
-
데이터마이닝은 다양한 수리 알고리즘을 이용해, DB의 데이터로부터 의미있는 정보를 찾아내는 방법을 통칭
-
종류
| 정보를 찾는 방법론에 따른 종류 | 분석대상, 활용목적, 표현방법에 따른 분류 |
|---|---|
| 인공지능 | 시각화분석 |
| 의사결정나무 | 분류 |
| K-Means Clustering | 군집화 |
| 연관분석 | 예측 |
| 회귀분석 | |
| k-최근접이웃 KNN |
데이터 마이닝 방법론
분석 목적에 따른 작업 유형과 기법
| 목적 | 작업유형 | 설명 | 사용기법 |
|---|---|---|---|
| 예측 | 분류규칙 | 회귀분석, 판별분석, 신경망, 의사결정나무 | |
| 설명 | 연관규칙 | 동시발생 매트릭스 | |
| 연속규칙 | 동시발생 매트릭스 | ||
| 데이터 군집화 | k-최근접이웃 |
데이터마이닝 추진단계
- 목적설정 → 데이터준비 → 가공 → 기법적용 → 검증
데이터 분할
| 역할 | 데이터 중 비중 |
|---|---|
| 학습용 | 50% |
| 검정용 | 30% |
| 시험용 | 20% |
- 데이터 양이 충분하지 않거나, 입력변수에 대한 설명이 충분한 경우
- HOLD-OUT: 주어진 데이터를 랜덤하게 2종류의 데이터로 구분하여 사용. 주로 학습용 / 시험용으로 구분.
- k-fold 교차분석: Cross Validation. 주어진 데이터를 k개의 하부집단으로 구분. k=10이 메이저. k-1 개는 학습용, 나머지 1개는 검증용으로 설정하여 학습하고, 에 대해 돌아가면서 반복. 이게 1회 시행임.
- LOOCV: Leave-one-out cross valiation. k-fold 랑 동일한데 k개의 집단이 아니라, 전체 데이터 n개에서 1개 샘플만을 남김. 1/10이 아니라 1개.
성과분석
Confusion Matrix (혼동행렬)
- Accuracy
- Error Rate (Accurary)
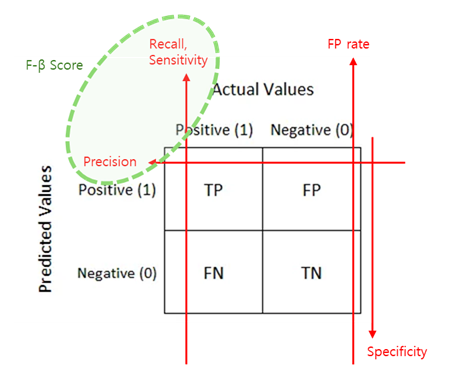
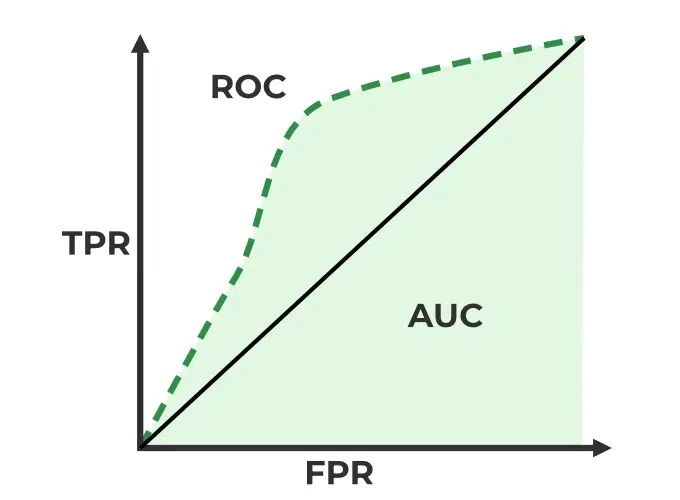
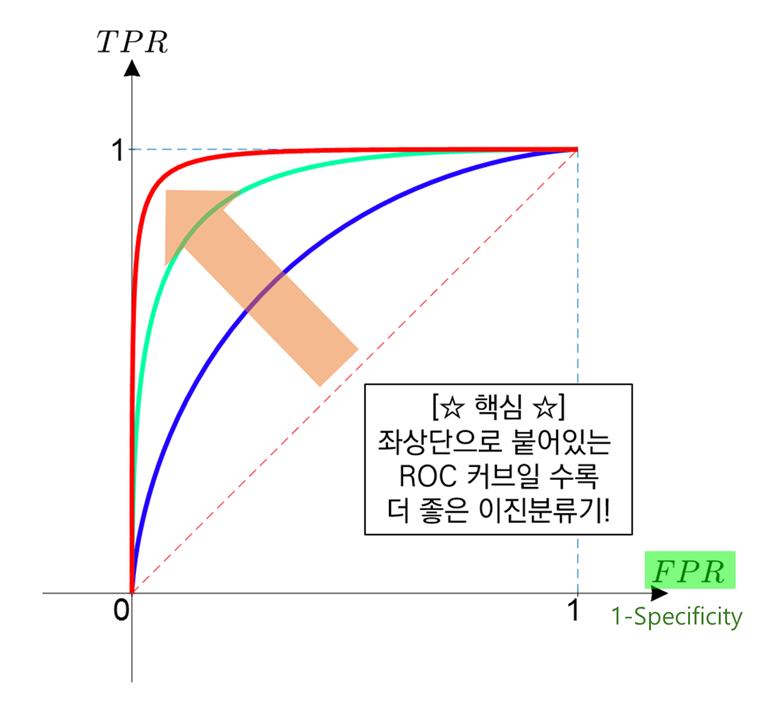
ROC Curve
- 2진 분류 (Binary Classification) 에서 모형의 성능 평가 위해 많이 사용
- AUC, AUROC (Area Under ROC): 1일수록 모형의 성능이 좋다.
- AR = 2 * AUROC - 100%
| AUC 기준 | 구분 |
|---|---|
| 0.9 - 1.0 | Excellent (A) |
| 0.8 - 0.9 | Good |
| 0.7 - 0.8 | Fair |
| 0.6 - 0.7 | Poor |
| 0.5 - 0.6 | Fail |
이익도표 (Lift Chart)
분류모형의 성능을 평가하기 위한 척도. 분류된 관측치에 대해 임의로 나눈 각 등급별로 반응검출율, 반응률, 리프트 등의 정보를 산출하여 나타내는 도표.
- 각 관측치에 대한 예측확률
- 데이터를 10개의 구간으로 나눈 후, 각 구간의 반응율 (% response)
- 향상도 (Lift) 란, 기본 향상도 (Baseline Lift)에 비해 반응률이 몇배나 높은지
이익도표의 각 등급은 예측확률에 따라 매겨진 순위이므로, 상위 등급에서는 더 높은 반응률을 보이는 것이 좋은 모형.
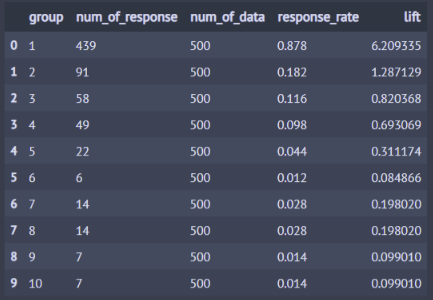
- 전체 5000명 중 707명이 구매
- Frequency of “buy”: 5000명 중 실제로 구매한 사람
- % Captured Response, 반응검출율 = 해당 등급의 실제 구매자 / 전체 구매자
- % Response, 반응률 = 해당 긍급의 실제 구매자 / 500명
- Lift, 향상도 = 반응률 / 기본 향상도. 좋은 모델이라면 Lift 가 빠른 속도로 감소해야 한다.
- Baseline Lift, 기본 향상도 = 707/5000 = 0.1414
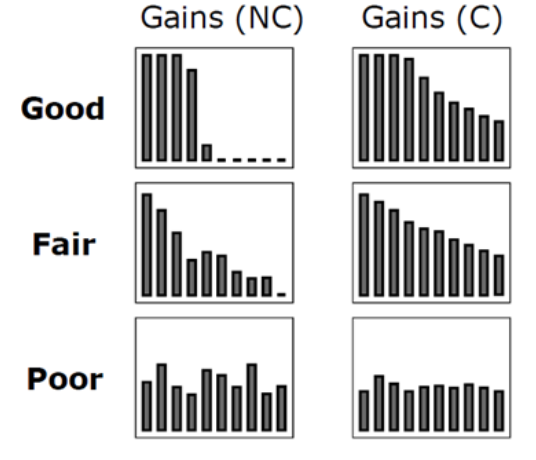
- 등급별로 향상도가 급격하게 변동할수록 좋은 모형이라고 할 수 있다.
- 각 등급별로 향상도가 들쭉날쭉하면 좋은 모형이라고 할 수 없다.
Feature Selection (변수선택)
| 구분 | 설명 | |
|---|---|---|
| 필터 방법 | 특정 모델링 기법에 의존하지 않고, 데이터의 통계적 특징으로 변수 선택 | 변수 간의 연관성 (relavance) 측정 |
| 래퍼 방법 | 변수의 일부만을 사용해 모델링 수행 후, 결과를 확인하는 작업을 반복하여 변수 선택 | 가장 좋은 성능을 보이는 변수 집합 (Feature Subset) 을 찾아내는 방법 |
| 임베디드 방법 | 모델링 기법 자체에 변수 선택이 포함되어 있는 방법 | 가장 좋은 성능을 보이는 변수 집합 (Feature Subset) 을 찾아내는 방법 |
필터 방법 : 데이터에 대한 통계적 특성 (ex 상호정보량, 상관계수) 등으로부터 변수를 선택
- 0에 가까운 분산을 갖는 변수를 제거. 서로 다른 관찰은 하는게 큰 의미가 없음.
- 두 변수간의 상관계수가 큼. 이때 두 변수는 같은 역할의 영향력을 지닐 가능성이 높음. PCA 등을 통해 독립차원으로 변환하거나 제거.
래퍼 방법: 일반적으로 필터 방법보다 래퍼 방법의 정확도가 더 높다. 시간이 오래 걸리며 OverFitting 위험이 있다.
| 구분 | 설명 |
|---|---|
| 전진 선택 | 변수 없이 시작, 가장 중요한 변수 추가 |
| 후진 제거 | 모든 변수 시작, 가장 사소한 변수 제거 |
| 단계별 선택 | 변수 삭제 / 추가 반복. 모든 변수 시작 / 변수 없이 시작 모두 가능 |
| 최적조합 선택 | 모든 경우의 모델 비교 All Subset Regression (부분집합 회귀분석) 이며, |
임베디드 방법: 모델링 기법 자체에 변수선택이 포함되어 있는 케이스.
| 구분 | 설명 |
|---|---|
| Lasso (L1 Penalty) | 가중치 절댓값의 합을 최소화하는 것을 제약조건으로 추가 중요하지 않은 가중치는 0이 될 수도 있다 변수간 상관관계가 높은 상황에서는 Ridge 에 비해 예측성능 하락할 수 있음 |
| Elastic Net | L1 규제와 L2 규제 복합 상관관계가 큰 변수를 동시에 선택하거나 배제하는 특징이 있음 |
DeepLearning
머신러닝
경험적인 데이터를 바탕으로, 기계가 지식을 습득하여 스스로 성능을 향상시킴
- 지도학습: 정답 줌
- 비지도학습: 정답 X
- 강화학습: 정답 X, 보상 줌
| 지도학습 | 비지도학습 |
|---|---|
| KNN | k-Means Clustering |
| 선형회귀 | 계층 군집 분석 |
| 로지스틱회귀 | 주성분 분석 |
| SVM | 연관규칙분석 |
| 의사결정나무 | 사회연결망 분석 |
| 랜덤포레스트 | 텍스트 마이닝 |
| 인공신경망 ANN |
딥러닝
인공신경망 에 기반을 둔 기계학습의 한 종류로, 여러 비선형 변환기법의 조합을 통해 많은 데이터로부터 특징들을 학습하는 기법