- k-최근접이웃 알고리즘
- 어떤 범주로 나누어져 있는 dataset 이 있을 때, 새로운 데이터가 추가된다면 이를 어떤 범주로 분류할 것인지를 결정할 때 사용
- 지도학습의 한 종류
KNN 원리
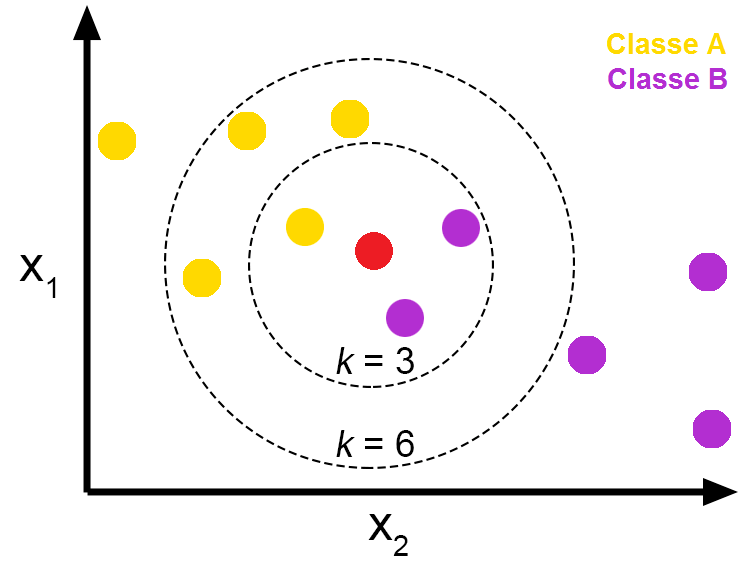
- k= 새로운 데이터의 클래스 (범주) 를, 해당 데이터와 가장 가까이 있는 k 개 데이터의 클래스 (범주) 로 결정
- 이진 (2개의 클래스) 분류 문제에서는 k 가 홀수인게 적합함
- 3개 이상일 경우에는 그때그때
- 일반적으로는 훈련 데이터 개수 n 의 sqrt n
- k 가 너무 클 경우, underfitting
- n=50,k=50 이면 모든 값이 동일한 범주로 분류
- k 가 너무 작다면, overfitting
사용되는 거리 종류
- Euclidean, n차원 두 점 P,Q 에 대해 ∑i=1n(pi−qi)2
- Manhattan
- Minkowski
| 장점 | 단점 |
|---|
| 사용이 간단 | k 값 결정이 어려움 |
| 범주를 나눈 기준을 알지 못해도, 데이터를 분류할 수 있음 | 수치형 데이터가 아닐 경우, 유사도 정의가 어려움 |
| 추가된 데이터의 처리가 용이함 | 데이터 내에 이상치가 존재하면 분류 성능에 큰 영향을 받음 |