0
0 1 2 3 4 5 6
SQL 레벨에서 배치 성능을 극대화하기 위한 구현 패턴을 정리했다. 애플리케이션 로직보다는 DB 엔진의 특성을 활용하는 것이 핵심이다.
핵심 요약
- 커서 사용 금지: 배치의 적은 RBAR(Row By Agonizing Row) 방식이다. 무조건 집합 단위 SQL을 작성하라.
- 로그 최소화: 복구 전략이 허용하는 한 Redo 로그 생성을 줄이는 방식을 택하라.
- 인덱스 관리: 입력 시 인덱스는 짐이다. 대량 입력 시에는 과감히 끄고 작업 후 다시 켜라.
- SQL 배치 성능 개선 구현 패턴
| 분류 | 패턴명 | 구현 내용 및 전략 | 기대 효과 |
|---|---|---|---|
| 로직 처리 | 집합 처리 (Set-based) | 커서(Cursor)나 루프(Loop)를 사용한 Row-by-Row 처리를 지양하고, INSERT INTO ... SELECT나 MERGE 문을 사용하여 단일 쿼리로 대량 데이터를 처리한다. | Context Switch 비용 제거, 엔진 최적화 활용 극대화 |
| I/O 최적화 | Array Processing (Bulk) | 애플리케이션에서 DB로 데이터를 보낼 때 한 건씩 보내지 않고, 배열(Array) 단위로 바인딩하여 한 번의 네트워크 호출로 다수의 레코드를 처리한다. | 네트워크 왕복 횟수(Round-trip) 감소, 통신 오버헤드 최소화 |
| I/O 최적화 | Direct Path Load (Nologging) | Undo/Redo 로그 생성을 최소화하거나 생략하고, 버퍼 캐시를 거치지 않고 데이터 파일에 직접 쓴다. (/*+ APPEND */ 힌트나 NOLOGGING 옵션 활용) | 로그 기록 부하 제거, 대량 데이터 적재 속도 비약적 향상 |
| 인덱스 전략 | Index Drop & Rebuild | 대량 INSERT/UPDATE 수행 전 인덱스를 제거(Drop)하거나 비활성화(Unusable)하고, 배치 종료 후 다시 생성(Rebuild)한다. | 인덱스 갱신에 따른 랜덤 I/O 부하 및 정렬 비용 제거 |
| 구조적 최적화 | Partition Pruning | 파티션 키를 조건절에 명시하여 전체 테이블이 아닌 필요한 파티션만 스캔하도록 유도한다. | I/O 범위 축소, 메모리 효율성 증대 |
| 자원 활용 | Parallel Query | /*+ PARALLEL(t, n) */ 등의 힌트를 사용하여 하나의 대형 쿼리를 여러 CPU 프로세스가 나누어 처리하도록 강제한다. | 대용량 집계 및 풀 스캔(Full Scan) 시 처리 시간 단축 |
| 중간 저장 | Intermediate Table (CTAS) | 복잡한 조인이나 연산이 필요한 데이터는 CREATE TABLE AS SELECT 등을 이용해 임시 테이블(GTT)로 먼저 추출한 후, 이를 기반으로 후속 작업을 진행한다. | 반복적인 조인 비용 제거, 락(Lock) 경합 최소화 |
| 커밋 전략 | Batch Commit | 트랜잭션 단위를 너무 작게(매 건마다) 혹은 너무 크게(전체 통으로) 잡지 않고, 적절한 주기(예: 1만 건)로 커밋하여 Undo 세그먼트 부하를 관리한다. | 시스템 안정성 확보, 롤백 세그먼트 오버플로우 방지 |
| 1 |
- 비용 계산의 주요 항목 (포함 항목)
| 항목 | 설명 | 영향도 |
|---|---|---|
| 선택도 (Selectivity) | 전체 로우 중 특정 조건에 의해 선택될 것으로 예상되는 비율 (0~1 사이의 값). | 가장 기본적인 변수로, 선택도가 낮을수록(추출 건수가 적을수록) 인덱스 스캔이 유리하다고 판단한다. |
| 클러스터링 팩터 (Clustering Factor) | 인덱스 정렬 순서와 테이블 데이터 저장 순서가 얼마나 일치하는지를 나타내는 지표. | 이 값이 테이블 블록 개수에 가까울수록 효율적이며, 총 로우 수에 가까울수록(무작위 저장) 비용이 높게 책정된다. |
| 인덱스 높이 (Index Height) | 루트 블록에서 리프 블록까지의 단계(Level). | 인덱스 탐색 시 읽어야 하는 최소 블록 수를 결정하며, 높이가 높을수록 I/O 비용이 증가한다. |
| 라이브러리 캐시(Library Cache)는 실행 계획(Execution Plan)이나 SQL 문장 자체를 저장하고 공유하는 공간이다. CBO가 ‘비용(Cost)‘을 계산하는 과정은 데이터의 분포와 I/O 효율성을 따지는 것이지, 실행 계획을 저장할 공간의 크기를 고려하여 경로를 결정하지 않는다. |
SQL에서 **업무 규칙(Business Rule)**이란 기업이 데이터를 처리, 관리, 보호하기 위해 정의한 비즈니스적 제약이나 로직을 데이터베이스 수준에서 강제하는 규칙을 의미한다. 데이터의 무결성(Integrity)을 유지하고 비즈니스 프로세스의 일관성을 보장하는 핵심 수단이다.
바인드 변수를 사용하면, 옵티마이저는 변수가 균등하게 분포되어 있다고 가정한다. 조건절에 실제값이 아닌 변수가 들어오면 히스토그램 정보를 사용할 수 없어 평균 분포를 가정한다.
병렬처리 (PP) 시스템에서 병렬 SQL문을 발행한 세션을 의미하며, 작업을 서버 프로세스에 할당하고 관리하는 주체는?
- Query Coordinator: 병렬 SQL문을 발행한 사용자 세션 그 자체를 의미
- Parallel Execution Server: QC로부터 할당받은 실제 작업을 수행하는 개별 프로세스들
- server set: 병렬 작업을 수행하기 위해 할당된 프로세스들의 집합
- table queue: QC와 서버 프로세스 간, 또는 서버 프로세스 상호 간의 통신 통로
- Parallel Execution Server Pool: 인스턴스 기동 시 또는 필요 시 생성되어 대기하고 있는 병렬 프로세스들의 가용 자원 집합이다. QC는 이 풀에서 프로세스를 가져와 사용한다.
- Data Bus / Process Channel: 일반적으로 DBMS의 병렬 실행 아키텍처 공식 용어라기보다 일반적인 컴퓨팅 시스템의 전송 경로를 의미하는 용어
| 구분 | 식별 관계 (Identifying) | 비식별 관계 (Non-Identifying) |
|---|---|---|
| 정의 | 부모의 PK가 자식의 **PK(기본키)**의 일부가 됨 | 부모의 PK가 자식의 **일반 속성(FK)**이 됨 |
| 표기법 (ERD) | 실선 (Solid Line) | 점선 (Dashed Line) |
| 종속성 | 강한 종속 관계 (부모 없이 자식 존재 불가) | 약한 종속 관계 (부모 없이 자식 존재 가능성 있음) |
| 데이터 조회 | 조인 시 비교적 효율적 (PK 인덱스 활용) | 조인이 잦아지면 인덱스 관리가 복잡해질 수 있음 |
| 단점 | PK 구조가 자식, 손자 엔티티로 갈수록 비대해짐 | 부모 데이터와의 정합성 유지를 위한 제약 조건 필요 |
| 종류 | 다른 명칭 | 특징 및 정의 | 예시 |
|---|---|---|---|
| 기본 엔티티 | 키 엔티티 (Key Entity) | 다른 엔티티의 도움 없이도 독립적으로 생성되는 엔티티 | 사원, 고객, 상품, 부서 |
| 중심 엔티티 | 메인 엔티티 (Main Entity) | 기본 엔티티로부터 발생하며, 비즈니스의 핵심 로직을 담고 있는 엔티티 | 주문, 매출, 계약, 접수 |
| 행위 엔티티 | 액티브 엔티티 (Active Entity) | 두 개 이상의 부모 엔티티로부터 발생하거나 내용이 자주 변경되는 엔티티 | 주문내역, 배송이력, 정산내역 |
| 구분 | 파급효과 내용 | 결과 |
|---|---|---|
| 품질 관점 | 데이터 중복 및 부정합 발생 | 의사결정 신뢰도 하락 |
| 비용 관점 | 유지보수 및 수정 비용 급증 | 프로젝트 TCO(총소유비용) 상승 |
| 성능 관점 | 시스템 처리량 감소 및 장애 발생 | 사용자 만족도 저하 및 서비스 중단 위험 |
| 종류 | 특징 및 정의 | 예시 |
|---|---|---|
| 기본 속성 (Basic) | 업무로부터 추출된 가장 일반적인 속성 | 사원명, 단가, 주소, 생년월일 |
| 관계 속성 (Relationship) | 엔티티 간의 관계를 맺어주기 위해 포함된 속성 | 부서코드, 고객번호 (FK 등) |
| 파생 속성 (Derived) | 다른 속성으로부터 계산되거나 가공되어 생성된 속성 | 총금액, 이자계산액, 전체인원수 |
| 설계 속성 | 업무 분석 단계에서는 도출되지 않지만, 데이터 모델링을 하는 과정에서 필요에 따라 설계자가 임의로 정의하는 속성 | 코드성 속성, 일련번호 |
1.
SQL 은 이하의 성질을 가지는 질의 언어
- 구조적 (structured)
- 집합적 (set-based)
- 선언적 (declarative)
PL/SQL, T-SQL 처럼 절차적 (procedural) 프로그래밍 기능을 구현할 수 있는 확장 언어도 있긴 하지만 위 성질을 벗어나지 않음.
원하는 결과집합을 구조적, 집합적으로 선언하지만, 그 결과집합을 만드는 과정은 절차적일수밖에 없다.
즉, 프로시져가 필요하다.
그런 프로시져를 만들어내는 DBMS 내부 엔진이 바로 SQL 옵티마이저다. 옵티마이저가 프로그래밍을 대신하는 셈이다.
DBMS 내부에서 프로시저를 작성하고, 컴파일해서, 실행가능한 상태로 만드는 모든 과정을 ‘SQL 최적화’ 라고 한다.
SQL 최적화
- SQL 파싱
- SQL 최적화
- 로우소스 생성
유저가 SQL 전달 → SQL 파서가 파싱 진행 (파싱 트리 생성 → Syntax 체크 → Semantic 체크) → SQL 최적화 → 로우소스 생성
- 파싱트리 생성: SQL문을 이루는 개별 구성요소를 분석, 파싱트리 생성
- Syntax 체크: 문법적 오류가 없는지 확인.
- ex) 사용할 수 없는 키워드 사용, 순서가 바르지 않음, 누락된 키워드가 있음
- Semantic 체크: 의미상 오류가 없는지 확인.
- ex) 존재하지 않은 테이블/컬럼 사용, 사용한 오브젝트에 대한 권한이 있는지
- SQL 최적화: 옵티마이저가 담당. 옵티마이저는 미리 수집한 시스템 및 오브젝트 통계정보를 바탕으로 다양한 실행경로를 생성해 비교한 후, 가장 효율적인 하나를 선택한다. **데이터베이스 성능을 결정하는 가장 핵심적인 엔진이다.**
- 로우소스 생성: 옵티마이저가 선택한 실행결로를, 실제 실행 가능한 코드 또는 프로시져 형태로 포맷팅하는 단계다. 로우 소스 생성기가 그 역할을 맡는다.
SQL 옵티마이저
사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는, 최적의 액세스 경로를 선택해주는 DBMS 의 핵심 엔진. 최적화 단계를 요약하면 아래와 같다.
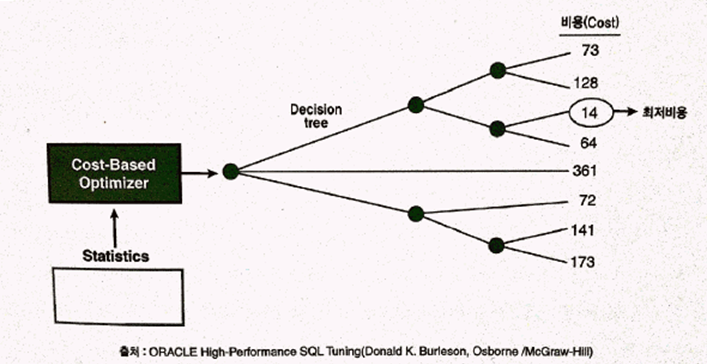
- 사용자가 전달한 쿼리를 수행하는데 후보군이 될만한 실행계획들을 찾아낸다.
- Data Dictionary 에 미리 수집해둔 오브젝트 통계 및 시스템 통계정보를 이용해, 각 실행계획의 예상비용을 산정한다.
- 최저비용을 나타내는 실행계획을 선택한다.
SQL 옵티마이저를 DBWR, LGWR, PMON, SMO 같은 백그라운드 프로세스로 이해하기 쉽다. 서버 프로세스가 SQL 을 전달하면, 옵티마이저가 최적화해서 실행계획을 돌려준다고 생각하는 것이다. 하지만, 옵티마이저는 별도 프로세스가 아니라 서버 프로세스가 가진 기능 (function) 일 뿐이다. SQL 파서와 로우 소스 실행기도 마찬가지다.
→ DBWR, LGWR, PMON, SMON 같은 애들은 실제로 존재하는 백그라운드 프로세스(daemon). 이런 흐름으로 머릿속에 그림을 그리면 직관적으로 이해하기 편하다. (마치 “옵티마이저라는 별도 담당자가 있다”고 상상하는 방식) 하지만 실제 구현은 ‘옵티마이저 프로세스’라는 게 따로 있는 게 아니라, 서버 프로세스 안에 있는 하나의 코드 (함수/모듈) 일 뿐이다. 옵티마이저, 파서, 실행기는 개념적으로 각각의 ‘역할/모듈’로 나눠서 설명할 수 있지만, 실제 구현은 DBWR·LGWR처럼 따로 떠 있는 프로세스가 아니라, 하나의 서버 프로세스 안에서 돌아가는 코드 조각들이다.
SELECT /*+leading(거래@subq) use_nl(C)*/
C.고객번호, C.고객명
FROM 고객 C
WHERE C.가입일시 >= TRUNC(ADD_MONTHS(SYSDATE, -1), 'MM')
AND EXISTS
(
SELECT /*+ QB_NAME(subq) unnest */
'x'
FROM 거래
WHERE 고객번호 = c.고객번호
AND 거래일시 >= TRUNC(SYSDATE, 'MM')
)
/*
## Execution Plan
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=253K Card=190 Bytes=11K)
1 0 NESTED LOOPS
2 1 NESTED LOOPS (Cost=253K Card=190 Bytes=11K)
3 2 SORT (UNIQUE) (Cost=2K Card=190 Bytes=9M)
4 3 TABLE ACCESS (BY INDEX ROWID) OF '거래' (TABLE) (Cost=2K Card=427K Bytes=9M)
5 4 INDEX (RANGE SCAN) OF '거래_X02' (INDEX) (Cost=988 Card=427K)
6 2 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=1 Card=190)
7 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE) (Cost=3 Card=1 Bytes=…)
*/
SELECT /*+NO_MERGE(T) LEADING(T) use_nl(C)*/
C.고객번호, C.고객명
FROM
(
SELECT DISTINCT 고객번호
FROM 거래
WHERE 거래일시 >= TRUNC(SSDATE, 'MM')
) T, 고객 C
WHERE C.가입일시 >= TRUNC(ADD_MONTHS(SYSDATE, -1), 'MM')
AND C.고객번호 = T.고객번호
select c.고객번호, c.고객명
from 고객 c
where c.가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and exists (
select /*+ unnest hash_sj */ *
from 거래별 x
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, 'mm')
);
/*
## Execution Plan
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=2K Card=38 Bytes=2K)
1 0 FILTER
2 1 HASH JOIN (SEMI) (Cost=2K Card=38 Bytes=2K)
3 2 TABLE ACCESS (BY INDEX ROWID) OF '고객' (TABLE) (Cost=3 Card=38 ...)
4 3 INDEX (RANGE SCAN) OF '고객_X01' (INDEX) (Cost=2 Card=38 ...)
5 2 TABLE ACCESS (BY INDEX ROWID) OF '거래' (TABLE) (Cost=2K Card=427K ...)
6 5 INDEX (RANGE SCAN) OF '거래_X02' (INDEX) (Cost=988 Card=427K ...)
*/