| 구분 | 특징 요약 | 핵심 키워드 |
|---|---|---|
| B-Tree | 기본형 균형 트리 | 50% 최소 점유 |
| B+ Tree | 리프 노드에만 데이터 저장 + 리프 간 연결 리스트 | 범위 스캔 최적화 (가장 많이 쓰임) |
| B* Tree | 가득 찬 노드를 형제와 공유 후 분할 | 공간 효율성 극대화 |
B* Tree 인덱스
B* Tree 구조를 요약하면 다음과 같다.
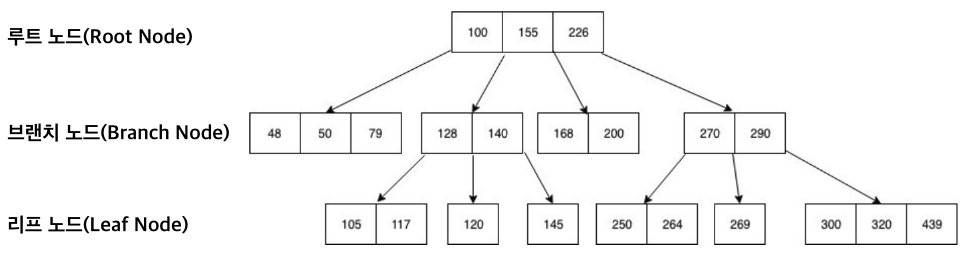
- 브랜치 블록
- 브랜치 블록의 각 row 는 하위 블록에 대한 주소값을 갖는다.
- 브랜치 블록 각 row 의 키값은 하위 블록이 갖는 값의 범위를 의미한다.
- 리프 블록
- 리프 블록의 각 row 는 테이블 row 에 대한 주소값을 갖는다.
- 리프 블록 각 row 의 키값과 테이블 row 의 키값은 서로 일치한다.
- 리프 블록의 각 row 와 테이블 row 간에는 1:1 관계다.
- 리프 블록끼리는 이중 연결 리스트(double linked list) 관계다. (DLL로 연결되어 있다.)
- 따라서 순차 스캔 시 정렬 순서를 보장한다.
B* Tree 인덱스를 탐색할 때는
- 우선 루트→브랜치→리프로 수직 탐색한다.
- 수직 참색을 통해 조건을 만족하는 첫 레코드를 찾는다.
- 찾으면, 인덱스 리프 블록을 스캔하면서 찾고자 하는 데이터가 더 안 나타날때까지 수평 스캔을 진행한다.
브랜치 블록 각 row 의 키값은 하위 블록이 갖는 값의 범위를 의미한다. 따라서 하위 블록 첫번째 row 의 키값과 일치하지 않을 수도 있다.
우선 수직적
Index Fragmentation
-
Index Skew
- 인덱스 엔트리가 한쪽(왼쪽/오른쪽)으로 치우치는 현상
- ex) 시계열적으로 증가하는 인덱스에서 과거 데이터를 일괄 삭제하고 나면,
- 왼쪽 리프 블록들은 텅 빈다
- 오른쪽 블록들은 꽉 찬 상태
-
Index Sparse
- 인덱스 블록 전반에 걸쳐 밀도(density)가 떨어지는 현상
-
B* Tree의 B는 Balanced
- 인덱스 루트로부터 모든 리프 블록까지의 높이는 항상 동일하다.
- 따라서 인덱스 높이가 다른 불균형 (unbalanced) 는 발생할 수 없음
-
불균형은 발생할 수 없지만,
- Index Fragmentation 에 의한 Skew/Sparse 같은 현상은 종종 발생
- 이는 인덱스 스캔에 나쁜 영향을 미친다