주요 조인
NL 조인
- 은 driving 집합의 크기
- 일의 횟수, driving 건수, 조인 시도 횟수 = 반복문이 돌아가는 수
- 은 driven 집합의 크기
- 일의 강도, driven 액세스 량, 조인 1회에 내부에서 읽는 블록수
- 이 일정할 경우, 을 최소화해야 한다.
- 이 크다는 것은 “똑같은 일을 처음부터 다시 시작하는 행위” 를 반복하는 것
- 반복되는 수직적 탐색: 아무리 이 1이라도, 매번 인덱스의 루트 블록부터 브랜치, 리프 블록까지 찾아 내려가는 CPU 연산을 n번 반복해야 한다.
- 버퍼 캐시 체인 경합: 블록을 읽을 때마다
cache buffers chains래치를 획득해야 하는데, n이 크면 이 래치를 얻기 위한 세션 간의 전쟁이 벌어진다. - 랜덤 액세스의 한계: n이 크면 디스크 헤더가 물리적으로 여기저기 튀어야 하므로 I/O 효율이 바닥을 친다.
| 구분 | NL 조인 (Nested Loops) | Hash 조인 (Hash Join) |
|---|---|---|
| 처리 방식 | 파이프라이닝 (Stream) | Stop-and-Go (Batch) |
| 중간 집합 | 없음 (레코드 단위 처리) | **필수 (해시 테이블 적재)** 소트머지도 동일 |
| 메모리 사용 | 매우 적음 | 높음 (Hash Area 점유) |
| 응답 속도 | 첫 로우(First Row) 응답이 매우 빠름 | 전체 결과 처리에 최적화 (대량 데이터) |
| 조인 조건 | 모든 연산자 가능 | 동치 조인(=)에서만 가능 |
- 랜덤 액세스 위주의 조인
- 인덱스 구성이 아무리 완벽해도 대량 데이터 조인할 때 NL조인은 불리
- 조인을 한 레코드씩 순차적으로 진행
- 부분범위 처리가 가능하다면 조인할 대상 레코드가 아무리 많아도 빠른 응답 속도를 낼 수 있다
- 순차적으로 진행하므로 먼저 액세스되는 테이블 처리 범위에 의해 전체 일량이 결정
- = 드라이빙 집합 크기
- 다른 조인 방식에 비해 인덱스 구성 전략이 특히 중요
- 조인 컬럼에 대한 인덱스가 있으냐 없느냐
- 있다면 컬럼이 어떻게 구성됐느냐
- 에 따라 조인 효율이 크게 달라진다
따라서 소량 데이터 처리, 또는 부분범위 처리가 가능한 OLTP 에 적합
먼저 액세스한 테이블의 처리 범위에 따라 전체 일의 양이 결정
-
해시 조인(Hash Join): 두 테이블을 각각 읽어 해시 테이블을 만든 후 조인하므로, 어느 한쪽의 범위가 줄어든다고 해서 전체 루프 횟수가 NL 조인처럼 드라마틱하게 변하지 않는다. 주로 대량 데이터 처리에 적합하다.
-
소트 머지 조인(Sort Merge Join): 양쪽 테이블을 각각 정렬한 후 병합한다. 역시 전체 데이터의 스캔 및 정렬 부하가 일의 양을 결정한다.
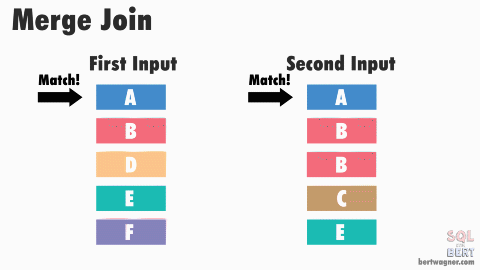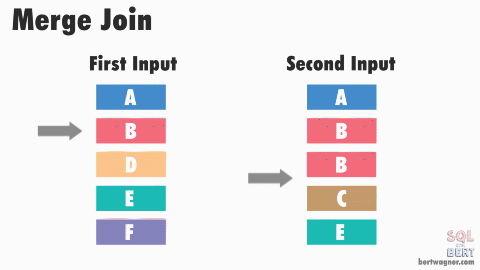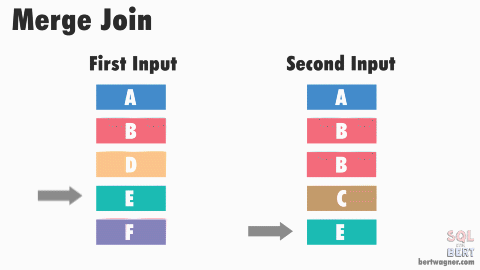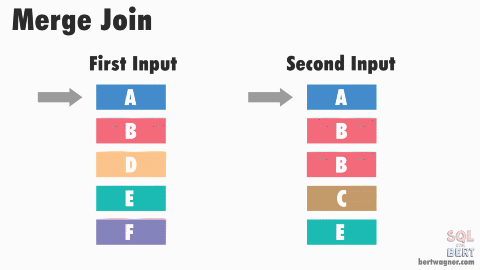
소트 머지 조인
조인 컬럼에 적당한 인덱스가 없어서
 | 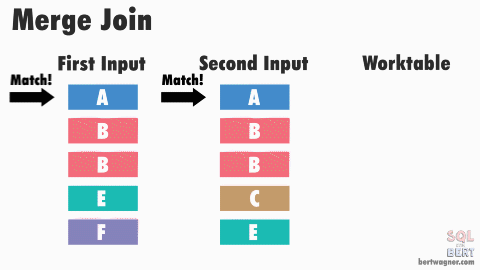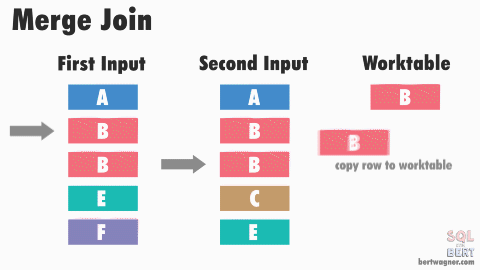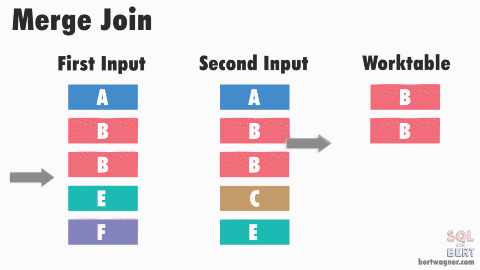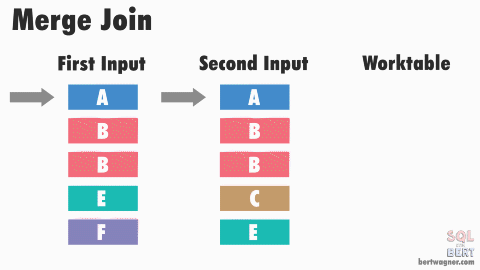 |
조인 컬럼에 적당한 인덱스가 업성서 NL조인이 비효율적일 때 사용할 수 있다
Driving 테이블의 개념이 중요하지 않은 조인 방식이다
조인 조건의 인덱스 유무에 영향을 받지 않는다
조인 프로세싱 자체는 NL 조인과 동일. 그럼에도 대량 데이터에 소트 머지가 적합한 이유는
- 양쪽 집합을 각각 읽어 정렬(SORT)한 후,
- 정렬된 결과를 머지하면서 조인한다.
즉, 소트 머지 조인은 조인을 위해 실시간으로 인덱스를 생성하는 것과 다름없 다. PGA 영역에 저장된 데이터를 사용하므로 빠르다.
정렬 (소트) 부하만 감수할 수 있으면, 건건이 버퍼캐시 경유 + 래치/버퍼체인 경합이 반복될 수 있는 NL보다 빠를 수 있다.
- 조인 컬럼 인덱스 유무의 영향을 NL보다 덜 받는다.
- 두 테이블을 “각각 읽고 나서” 조인을 시작한다는 성격이 강하다.
- 스캔 위주 액세스 방식을 사용한다.
- 단, 조인 과정에서 랜덤 액세스가 “완전히 0”인 것은 아니며, 상황에 따라 발생할 수 있다.
- 양쪽 소스 집합으로부터 조인 대상 레코드를 찾을 때, 인덱스를 사용한다면 랜덤 액세스가 일어난다.
- 이는 해시 조인도 마찬가지다.
해시 조인의 핵심(정답 34 흐름 복구)
해시 조인이 인덱스 기반 NL보다 빠른 결정적 이유도 본질적으로는 소트 머지와 비슷하다.
- 조인 프로세싱 자체는 NL 조인과 동일하지만
- 조인 연산 자체를 PGA(메모리)에서 처리하므로
- 건건이 INNER 집합을 버퍼캐시에서 탐색하는게 아니라, PGA 에 미리 생성해둔 해시 테이블 (해시 맵) 을 탐색해서 조인한다
- 해시 맵을 이용하므로 조인 컬럼에 인덱스가 없어도 상관없다
- NL처럼 매 건마다 래치/버퍼체인 탐색/버퍼락 같은 반복 비용이 줄어든다.
하지만 해시 조인도 입력을 읽는 단계에서는 DB 버퍼캐시를 경유하며, 해시 테이블(Build)을 만드는 사전 준비 비용이 든다.
PGA를 초과하면 TEMP로 스필(spill)되어 디스크 작업이 커진다.
해시맵을 PGA 에 생성해야 하므로, 둘 중 어느 한쪽이 PGA 에 담을 수 있을 정도로 충분히 작을 때 가장 효과적이다.
그리고 중요한 조건:
- 해시 조인은 원칙적으로 조인 조건이 ‘=’(등치) 일 때만 사용 가능하다.
- (LIKE/BETWEEN 등은 해시 키 매칭 구조상 불리하거나 불가)
또한 OLTP에서 “해시 조인이 빠르다”는 이유로 남용하면 위험하다.
- 해시 테이블은 실행마다 만들어지고 사라지는 구조라,
- 수행 빈도가 높은 짧은 쿼리에서 CPU/메모리/래치 경합을 오히려 키울 수 있다.
그래서 해시 조인은 보통 다음 3조건에 해당하는 SQL에 적합하다.
- 수행 빈도가 낮고
- 수행 시간이 길며
- 대량 데이터를 조인하는 배치/OLAP성 쿼리
왜 해시 조인은 조인조건이 ’=’ 경우에만 가능한가?
=과 함께 기술된 범위 조건(>, <, BETWEEN 등)은 해시 테이블을 만드는 데 기여하지 못한다.
- 작동 방식:
- Probe 단계에서 해시 버킷을 찾아 매칭되는 데이터를 발견했을 때, 그 데이터가 범위 조건까지 만족하는지 검사하는 단계에서만 사용된다.
- 성능 영향:
- 조인 연결고리에 범위 조건이 많더라도,
=조건의 변별력이 낮으면 일단 해시 테이블에서 많은 데이터를 매칭(Probe)한 뒤 필터링으로 버려야 하므로 비효율이 발생한다.
- 조인 연결고리에 범위 조건이 많더라도,
이는 비단 해시 조인만의 특징은 아니다.
- 해시 클러스터도 ’=’ 검색일 때만 사용 가능
- 해시 파티션도 ’=’ 일때만 Partition Pruning 이 작동
필터 전락 상황
| 조인 방식 | 필터 전락 주요 원인 | 결과 및 영향 |
|---|---|---|
| NL Join | 인덱스 부재, 컬럼 가공, 선두 컬럼 누락 | Driven 테이블 반복 전체 스캔 (I/O 폭증) |
| Sort Merge | 비동등 조건, 보조 조인 조건 | 머지 단계에서의 불필요한 비교 연산 증가 |
| Hash Join | 범위/부등호 조건, 타입 불일치 | 해시 버킷 내 대조 작업량 증가 (CPU 부하) |
① NL Join (Nested Loops Join)
NL 조인에서 Driven(Inner) 테이블의 조인 조건이 필터로 전락하는 경우는 주로 인덱스 활용 능력의 상실과 직결된다.
-
Driven 테이블 인덱스 부재: 조인 컬럼에 인덱스가 없으면, Driving 테이블에서 넘어온 레코드마다 Driven 테이블 전체를 스캔(Full Scan)하며 조건을 검사하게 된다.
-
조인 컬럼의 가공: 조인 절에
ON A.KEY = FUNC(B.KEY)와 같이 Driven 컬럼을 가공하면 인덱스를 사용하지 못하고 필터로 작동한다. -
복합 인덱스 선두 컬럼 누락: Driven 테이블 인덱스가
[COL1 + COL2]순인데 조인 조건이COL2만 포함하는 경우, 인덱스 수직 탐색이 불가능하여 인덱스 전체를 필터링하며 읽어야 한다. -
범위 조건 뒤의 동등 조건: 인덱스가
[범위컬럼 + 동등컬럼]일 때, 앞선 범위 조건 때문에 뒤의 동등 조건은 스캔 범위를 줄이지 못하고 필터 역할만 수행한다.
② Sort Merge Join
소트 머지 조인은 양쪽 테이블을 정렬한 후 병합하는 방식이므로, 정렬에 기여하지 못하는 조건은 모두 필터가 된다.
-
Non-Equi Join (비동등 조인): 조인 조건이
>,<,BETWEEN등인 경우, 해당 컬럼으로 정렬은 수행하지만 머지 단계에서 범위를 하나하나 대조하며 필터링해야 한다. -
추가 조인 조건: 조인 연결고리가 여러 개일 때, 옵티마이저가 선택한 주 정렬 키(Major Sort Key) 외의 나머지 조건들은 머지 과정에서 데이터가 일치하는지 확인하는 필터로 사용된다.
③ Hash Join
해시 조인은 알고리즘 특성상 **동등 조건(=)**에만 최적화되어 있다.
-
범위 및 부등호 조건: 해시 함수는 값이 같아야 동일한 버킷으로 안내한다. 따라서
>,<,LIKE등의 범위 조건은 해시 버킷을 찾는 데 쓰이지 못하고, 매칭된 버킷 내 데이터를 검증하는 필터로만 작동한다. -
동등 조건이 하나도 없는 경우: 조인절에
=조건이 아예 없다면 해시 조인 자체가 불가능하거나(Oracle 기준), 극히 제한적인 상황에서만 필터 방식으로 수행된다. -
데이터 타입 불일치: 두 조인 컬럼의 데이터 타입이 달라 묵시적 형변환이 발생하면 해시 함수 적용이 불가능해져 필터링 부하가 급증한다.
그외
SEMI / ANTI 조인
세미 조인(Semi Join)과 안티 조인(Anti Join)은 서브쿼리를 사용하여 데이터를 필터링할 때 오라클 및 SQL Server 옵티마이저가 사용하는 핵심 조인 메커니즘이다. 일반적인 조인과 달리 결과 집합의 중복을 방지하고 I/O를 최적화하는 데 특화되어 있다.
1. 세미 조인 (Semi Join)
정의: 서브쿼리 내에 존재(Exists)하는 데이터가 메인 쿼리의 행과 일치하는지 확인하여, 일치하는 행이 최소 하나라도 발견되면 즉시 해당 행을 반환하고 다음 행으로 넘어가는 방식이다.
-
주요 구문:
EXISTS,IN -
작동 메커니즘: 메인 테이블의 레코드당 서브쿼리 테이블을 탐색하다가 첫 번째 일치 항목을 찾는 즉시 탐색을 중단(First-match)한다.
-
특징: 일반 Inner Join과 달리 메인 쿼리의 행이 서브쿼리의 여러 행과 일치하더라도 중복된 행이 발생하지 않는다. 따라서
DISTINCT연산이 필요 없어 성능상 유리하다.
2. 안티 조인 (Anti Join)
정의: 세미 조인의 반대 개념으로, 서브쿼리 내에 일치하는 데이터가 전혀 존재하지 않는(Not Exists) 경우에만 메인 쿼리의 행을 반환하는 방식이다.
-
주요 구문:
NOT EXISTS,NOT IN -
작동 메커니즘: 서브쿼리 테이블을 탐색하다가 일치하는 항목이 하나라도 발견되면 해당 메인 행을 버리고 다음 행으로 넘어간다. 끝까지 탐색했는데 일치하는 것이 없을 때만 최종 결과에 포함한다.
-
특징: 주로 차집합(Difference)을 구할 때 사용된다.
3. 주요 차이점 및 비교
| 구분 | 세미 조인 (Semi Join) | 안티 조인 (Anti Join) |
|---|---|---|
| 목적 | 존재 여부 확인 (Existence) | 미존재 여부 확인 (Non-existence) |
| 대표 구문 | EXISTS, IN | NOT EXISTS, NOT IN |
| 중단 시점 | 첫 번째 일치 항목 발견 시 | 첫 번째 일치 항목 발견 시 (해당 행 탈락) |
| 결과 집합 | 메인 테이블의 고유 행 유지 | 메인 테이블의 고유 행 유지 |
4. 실무적 주의사항: NOT IN과 NULL (Anti Join의 함정)
안티 조인 수행 시 NOT IN을 사용할 때 서브쿼리 결과에 NULL이 포함되어 있으면, 전체 쿼리 결과가 아무것도 나오지 않는 현상이 발생한다.
-
원인:
NOT IN (..., NULL)은 논리적으로column != val1 AND column != NULL로 풀리는데, 오라클에서NULL과의 비교 연산은 항상UNKNOWN을 반환하기 때문이다. -
해결책: 1. 서브쿼리에
IS NOT NULL조건을 추가한다. 2.NOT IN대신 NULL 처리가 안전한 **NOT EXISTS**를 사용한다. (전문가들은NOT EXISTS사용을 권장한다.)
5. 실행 계획에서의 확인
-
Oracle: 실행 계획에
HASH JOIN SEMI,NESTED LOOPS SEMI,HASH JOIN ANTI등의 오퍼레이션이 명시된다. -
SQL Server: 실행 계획의 연산자 아이콘 속성에
Left Semi Join또는Left Anti Join으로 표시된다.
Full Partition Wise Join
| 구분 | Full Partition Wise Join | Partial Partition Wise Join |
|---|---|---|
| 파티션 상태 | 두 테이블 모두 조인 키로 파티셔닝 | 한쪽 테이블만 조인 키로 파티셔닝 |
| 재분배 부하 | 없음 (가장 빠름) | 파티션 안 된 테이블을 동적으로 재분배함 |
| 유연성 | 낮음 (설계 시부터 고려 필요) | 높음 |
대용량 파티션 테이블 간의 조인 성능을 극대화하기 위해 설계된 오라클의 최적화 기법이다. 조인에 참여하는 두 테이블이 조인 컬럼을 기준으로 동일하게 파티셔닝되어 있을 때, 오라클은 전체 데이터를 조인하는 대신 파티션 짝(Pair)끼리만 독립적으로 조인을 수행한다.
① 핵심 개념 및 메커니즘
두 테이블이 동일한 파티션 키와 방식으로 나누어져 있다면, Table A의 1번 파티션 데이터는 오직 Table B의 1번 파티션 데이터와만 조인될 가능성이 있다. 이를 이용해 조인 단위를 파티션 수준으로 잘게 쪼개는 것이다.
-
독립적 수행: 각 파티션 쌍의 조인은 다른 파티션과 완전히 독립적으로 이루어진다.
-
병렬 처리 최적화: 병렬 쿼리(Parallel Query) 실행 시, 각 병렬 서버 프로세스(Slave)가 특정 파티션 짝을 전담하여 조인한다.
② 성능상 이점
이 기법의 진가는 병렬 쿼리 환경에서 나타난다.
-
데이터 재분배(Redistribution) 제거: 일반적인 병렬 조인에서는 데이터를 서로 다른 프로세스에 뿌려주는 ‘Distribute’ 과정(Hash 또는 Broadcast)이 필수적이며, 여기서 심각한 네트워크/메모리 병목이 발생한다. Full Partition Wise Join은 이 과정이 아예 생략된다.
-
메모리 부하 감소: 조인 단위가 파티션으로 국한되므로, 해시 조인(Hash Join) 시 필요한 해시 테이블 크기가 작아져 메모리 부족으로 인한 Temp 디스크 사용(Pass-out)을 방지한다.
-
스케일 아웃: 파티션 개수가 많을수록 더 많은 병렬 프로세스를 투입하여 선형적으로 성능을 높일 수 있다.
③ 성립 조건
Full Partition Wise Join이 작동하려면 매우 엄격한 조건이 충족되어야 한다.
-
조인 컬럼 = 파티션 키: 조인 조건에 사용된 컬럼이 두 테이블의 파티션 키여야 한다.
-
동일한 파티션 방식: 두 테이블이 동일한 파티션 방식(Range-Range, Hash-Hash 등)을 사용해야 한다.
-
파티션 개수 일치: 두 테이블의 파티션 개수가 동일해야 한다. (단, 12c 이후 버전 및 특정 조건에서는 배수 관계에서도 작동할 수 있음)
-
병렬 실행: 주로 병렬 환경에서 의미가 크며, 힌트(
/*+ PQ_DISTRIBUTE(table_name NONE NONE) */)를 통해 유도하기도 한다.
④ 실행 계획 확인법
실행 계획(Execution Plan)에서 다음과 같은 특징이 나타나면 Full Partition Wise Join이 수행된 것이다.
-
PX SEND나PX RECEIVE같은 데이터 재분배 오퍼레이션이 조인 상단에 존재하지 않는다. -
PARTITION RANGE/HASH ALL오퍼레이션이 조인 하위에 나타난다. -
Operation컬럼 부근에P->P(Parallel to Parallel)가 아닌 내부적인 로컬 수행 구조가 관찰된다.
주의: 통계정보가 부정확하거나 파티션 키 컬럼에 대한 형변환이 발생하면 옵티마이저는 이 기법을 선택하지 않는다.