개요
효율적인 활용을 전제할 경우, 인덱스의 선행조건은 결코 범위여서는 안된다.
선행조건이 범위일 경우,
- 인덱스를 사용하고는 있으나
- ‘수직적 탐색(Seek)’ 을 통해 읽기 범위를 줄이지 못한다
- 후행 컬럼의 동등 조건이 데이터 추출 단계가 아닌 ‘단순 필터링’ 으로 전락한다.
인덱스를 안 쓰는 것(Full Table Scan)보다는 빠를 수 있다. 하지만 인덱스 엔트리를 수만 건 읽어서 실제 결과 10건을 찾아낸다면, 이를 ‘인덱스를 효율적으로 썼다’ 고 보지 않는다.
인덱스는 선행 컬럼순으로 먼저 정렬되고, 그 안에서 후행 컬럼이 정렬된다.
- 선행 컬럼이 동등(=)일 때:
- 선행 컬럼이 특정 값으로 고정된다.
- 따라서 그 안에서 후행 컬럼은 완벽하게 정렬된 상태를 유지한다.
- 후행 컬럼의 조건도 시작점과 끝점을 정확히 집어내는 **‘액세스 조건(Access Predicate)‘**으로 작동한다.
- 선행 컬럼이 특정 값으로 고정된다.
- 선행 컬럼이 범위(Range)일 때:
- 선행 컬럼의 값이 바뀌는 구간마다 후행 컬럼의 정렬이 새로 시작된다.
- 즉, 전체 범위 안에서 후행 컬럼은 연속적으로 정렬되어 있지 않다.
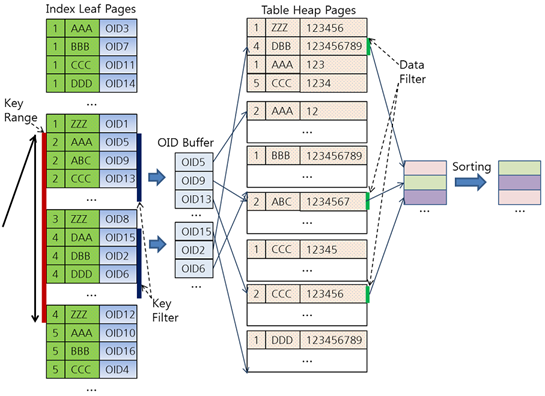
액세스 조건(Access Predicate) vs 필터 조건(Filter Predicate)
-
효율적인 상황 (동등 + 범위):
- 인덱스 리프 블록에서 읽어야 할 시작 지점과 끝 지점을 정확히 결정한다.
- 검색량 자체가 최소화된다.
-
비효율적인 상황 (범위 + 동등):
- 선행 컬럼의 범위에 해당하는 모든 인덱스 엔트리를 일단 다 읽어야 한다.
- 읽는 과정에서 후행 컬럼의 값이 조건과 맞는지 하나하나 검사(Filter)한다.
- 이때 후행 컬럼의 조건은 읽는 범위를 줄여주는 게 아니라, 읽은 것 중에서 버리는 역할을 할 뿐이다.
OR 조건의 본질적 한계
B-Tree 인덱스는 특정 컬럼의 값을 기준으로 수직 정렬되어 있다.
AND조건은 인덱스 리프 블록 내의 특정 구간을 집어낼 수 있다.OR조건은 그렇지 않다.- 연속성 결여:
- IDX=2와 NAME=AAA 는 인덱스 내에서 서로 다른 위치에 흩어져 존재한다.
- 단일 스캔 불가능:
- 하나의 인덱스 탐색(Index Root → Branch → Leaf)만으로는 두 조건을 동시에 만족하는 범위를 정의할 수 없다.
- 즉, 본질적으로 두 번의 탐색이 필요하다.
- 연속성 결여:
OR EXPANSION
오라클 등 대부분의 DBMS는 OR 조건을 내부적으로 분리하여 처리하는 OR Expansion(또는 CONCATENATION) 기능을 제공한다.
SELECT *
FROM 일별매출
WHERE IDX = 2
UNION ALL
SELECT *
FROM 일별매출
WHERE NAME = 'AAA' AND LNNVL(일자 = 2);그럼에도 불구하고 가끔 Full Scan 으로 선택되는 상황은 있다.
- 옵티마이저가 위와 같이 인덱스를 두 번 타고 테이블을 액세스하는 비용보다,
- Multi-Block I/O를 통해 테이블을 한 번에 다 읽는 비용이 더 저렴하다고 판단
- 데이터량이 적거나,
- 각 조건의 선택도(Selectivity)가 높아 읽어야 할 행이 많을 때 주로 발생한다.
인덱스가 [IDX + NAME] 순으로 구성된 결합 인덱스라면 더욱 심각하다.
- 첫 번째 조건인
IDX는 인덱스 선두 컬럼이므로 탐색이 가능하지만,OR뒤의NAME조건은 선두 컬럼 조건이 없으므로 인덱스를 효율적으로 탈 수 없다. - 결국 인덱스의 처음부터 끝까지 다 뒤져야 하는 상황이 발생하므로, 옵티마이저는 차라리 테이블
FULL SCAN을 선택한다.
결합 인덱스 키컬럼 조건
① 조건절에 항상 혹은 자주 사용되는 컬럼 (최우선 선정 기준)
인덱스는 조건절(WHERE)에 해당 컬럼이 존재해야만 사용될 수 있다. 특히 결합 인덱스의 경우, **선행 컬럼(Leading Column)**이 조건절에서 누락되면 인덱스 전체를 효율적으로 사용하지 못하고 Index Full Scan이나 Table Full Scan이 발생할 확률이 높다.
- 이유: 인덱스 탐색의 시작점이 되기 위해서는 반드시 쿼리에 포함되어야 하므로, 사용 빈도가 가장 높은 컬럼을 인덱스의 선두에 배치하거나 필수 구성 요소로 포함해야 한다.
② ’=’ 조건으로 자주 조회되는 컬럼 (효율성 기준)
앞선 질문에서도 다뤘듯이, 결합 인덱스의 성능은 **‘어디서 범위를 줄여주는가’**에 달려 있다.
-
이유: 선행 컬럼이
=조건이어야만 후행 컬럼이 인덱스 수직적 탐색(Seek)을 위한 **액세스 조건(Access Predicate)**으로 작동한다. -
부연: 선행 컬럼이 범위(
BETWEEN,LIKE,< >) 조건이면 후행 컬럼은 단순 필터 역할만 수행하게 되어 I/O 효율이 급격히 떨어진다. 따라서=조건으로 쓰이는 컬럼을 인덱스 앞부분에 배치하는 것이 설계의 핵심이다.
기타 기준 평가
-
데이터 분포(Selectivity): 단일 인덱스에서는 중요하지만, 결합 인덱스에서는 컬럼 순서(Operator 종류)에 의한 범위 축소 효과가 더 우선시된다. 분포도가 좋은 컬럼이라도 범위 조건으로 쓰이면 인덱스 효율이 낮아지기 때문이다.
-
정렬 기준 컬럼:
ORDER BY절을 위한 인덱스 구성은Sort Area부하를 줄여주지만, 이는 WHERE 절의 검색 조건 최적화가 선행된 후에 검토해야 할 부차적인 최적화 단계다.