옵티마이저의 최적화 단계
- 사용자로부터 전달받은 쿼리를 수행하는데 후보군이 될만한 실행계획들을 도출한다.
- DATA DICTIONARY 에 미리 수집해둔 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용을 산정한다.
- 최저비용을 나타내는 실행계획을 선택한다.
데이터 딕셔너리에 미리 수집해둔 오브젝트 통계 / 시스템 통계는 최적화 단계에서 활용된다.
SQL 파싱 단계에서는 테이블 정보, 컬럼 정보, 권한 정보 등을 활용한다.
RBO
- 규칙 기반 옵티마이저
| 구분 | 규칙 기반 (RBO) | 비용 기반 (CBO) |
|---|---|---|
| 기준 | 사전 정의된 우선순위 규칙 | 예상되는 소요 비용 (I/O, CPU 등) |
| 판단 근거 | 인덱스 유무, SQL 연산자 등 | 테이블 크기, 데이터 분포 (통계 정보) |
| 핵심 요소 | 개발자의 SQL 작성 숙련도 | 정확한 통계 정보 관리 |
| 유연성 | 낮음 (규칙에 고정됨) | 높음 (데이터 변화에 대응) |
| 주요 사용 | 과거 모델 (Legacy) | 현재 대부분의 DBMS 표준 |
RBO는 미리 정해진 우선순위 규칙에 따라 실행 계획을 세웁니다. 데이터의 실제 양이나 분포를 고려하지 않고, SQL 문 자체의 문법적 구조와 인덱스 존재 여부 등 ‘규칙’만을 따집니다.
- 특징: 통계 정보가 필요 없으며, 실행 계획이 예측 가능합니다.
- 우선순위 예시: (일반적으로 15단계 정도의 순위가 있음)
- Single Row by RowID (가장 빠름)
- Single Row by Unique Index
- Full Table Scan (가장 느림)
- 단점: 데이터 양이 적은 테이블에 인덱스가 있다고 해서 무조건 인덱스를 타게 만드는 등 비효율적인 경로를 선택할 수 있습니다.
- 현황: 과거 Oracle 등에서 사용되었으나, 현재는 거의 사용되지 않으며 하위 호환성을 위해서만 존재합니다.
CBO
- 비용 기반 옵티마이저
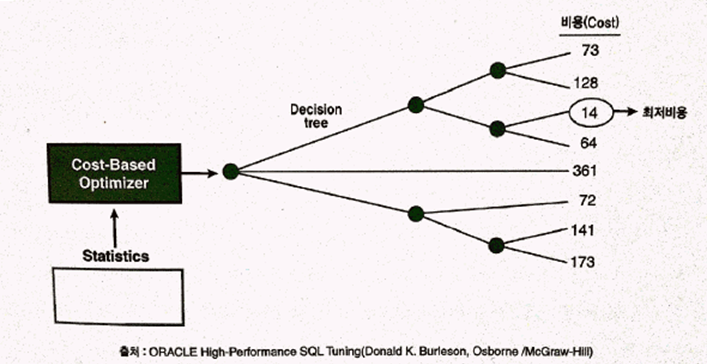
사용자로부터 전달받은 쿼리를 수행하는데 후보군이 될만한 실행계획들을 찾아내서, 각각의 예상비용을 산정한 후 최저비용을 나타내는 하나를 선택한다.
비용을 산정하는 과정에 예상 랜덤 I/O 발생량을 고려하지만, 궁극의 선택 기준은 예상 비용이다. 최신 CPU 비용 모델에서는 예상 CPU 사용량도 고려한다.
CBO는 SQL을 실행하는 데 필요한 **비용(Cost)**을 계산하여 가장 적은 비용이 드는 계획을 선택합니다. 여기서 ‘비용’이란 쿼리를 수행하는 데 예상되는 I/O 횟수, CPU 사용량, 메모리 사용량 등을 의미합니다.
- 특징: 데이터베이스의 **통계 정보(Statistics)**를 활용합니다. 테이블의 레코드 수, 컬럼의 값 분포, 인덱스 높이 등을 참조합니다.
- 장점: 실제 데이터의 상황을 반영하므로 RBO보다 훨씬 효율적인 실행 계획을 생성합니다.
- 단점: 통계 정보가 최신 상태로 관리되지 않으면 잘못된 실행 계획을 세울 수 있습니다. 또한, 최적의 경로를 찾는 계산 과정 자체가 복잡하여 약간의 시간이 소요됩니다.
옵티마이저 힌트
옵티마이저 힌트는 명령어 (DIRECTIVES) 이므로 특별한 이유가 없는 한 그대로 실행된다. 힌트가 무시되는 특별한 이유는 아래와 같다.
- 문법적으로 맞지 않게 힌트를 기술
- 잘못된 참조 사용
- 없는 테이블이나 별칭 (alias) 를 사용한 경우
- 없는 인덱스명을 지정한 경우 등
- 논리적으로 불가능한 액세스 경로
- ex) 조인절에 등치 (=) 조건이 하나도 없는데 해시조인으로 유도
- 테이블 전체 건수를 COUNT 하는 쿼리에 NULL 을 허용하는 단일 컬럼으로 생성한 인덱스를 사용하도록 힌트를 지정
- 의미적으로 맞지 않게 힌트를 기술
- ex) 서브쿼리에 UNNEST 와 PUSH_SUBQ 를 같이 기술
- 옵티마이저에 의해 내부적으로 쿼리가 변환된 경우
- 버그
SQL SERVER 는 힌트에 오류가 있으면 에러가 발생하지만, 오라클은 그렇지 않다. 옵티마이저 힌트를 사용하면 SQL 최적화 소요 시간은 오히려 감소한다.
INDEX 힌트에 인덱스명을 지정하지 않으면, 어떤 인덱스를 사용할지 옵티마이저가 결정한다. LEADING 힌트에 나열하지 않은 테이블의 조인순서는 옵티마이저가 결정한다.
옵티마이저 힌트를 사용할 때 유의할 점은 아래와 같다.
- 힌트 안에 인자를 나열할 땐 ’,’ (콤마) 를 사용할 수 있지만, 힌트와 힌트 사이에 사용하면 안된다.
- 힌트에 인자를 나열할 때 콤마를 사용해도 되고, 생략해도 된다.
- 테이블을 지정할 때 스키마명까지 지정하면 안된다.
- FROM 절 테이블명 옆에 ALIAS 를 지정했다면, 힌트에서 반드시 ALIAS 를 사용해야 한다.
옵티마이저
규칙기반 옵티마이저(RBO)
통계정보를 전혀 활용하지 않고, 각 액세스 경로에 대한 우선순위 규칙만으로 실행계획을 만드는 옵티마이저를 규칙기반(Rule-Based) 옵티마이저, 줄여서 RBO라고 한다.
RBO는 데이터 특성이나 통계정보를 전혀 반영하지 않기 때문에, 대용량 데이터베이스 환경에서는 적합하지 않다. 아래는 RBO가 사용하는 대표적인 규칙(우선순위)이며, 인덱스 구조/연산자/조건절 형태 등이 순위 결정의 주요 요소임을 알 수 있다.
- Single Row by ROWID
- Single Row by Cluster Join
- Primary Key(Unique) / Single Row by Unique or Primary Key
- Hash Cluster Key / Clustered Join / Hash Cluster Key
- Composite Index …
- Bounded Range Search on Indexed Columns
- Unbounded Range Search on Indexed Columns
- Sort Merge Join
- MAX/MIN of Indexed Column
- ORDER BY Indexed Column
- Full Table Scan (가장 낮은 순위)
예전에는 RBO 규칙이 어느 정도 통했지만, 지금과 같은 대용량 환경에서는 대안이 되기 어렵다.
RBO 선택의 문제점 예시(원문 취지 복원)
Full Table Scan의 우선순위가 가장 낮기 때문에, RBO는 상황을 가리지 않고 인덱스를 선호한다. 예를 들어 조건을 만족하는 비율이 전체의 90% 라면, 인덱스를 타는 것이 결코 좋은 선택이 아니다.
ORDER BY가 인덱스 컬럼으로 해결 가능하다는 이유만으로 인덱스를 선택하기도 한다. 부분범위 처리가 가능한 상황이면 유리할 수 있으나, 전체 범위를 끝까지 처리해야 하는 상황에서 인덱스로 전체 레코드를 액세스하는 것은 오히려 불리하다.
BETWEEN(닫힌 범위)이 부등호(열린 범위)보다 유리하다는 규칙도 “일반적으로” 맞는 편이지만, 실제 데이터 분포(예: 60세 이상보다 3000~6000 연봉 구간의 사람이 훨씬 많음)를 RBO는 전혀 모른다.
비용기반 옵티마이저(CBO)와 비용(Cost)의 의미, 한계
비용기반(Cost-Based) 옵티마이저(CBO) 는 데이터 딕셔너리에 미리 수집된 통계정보를 이용해 각 실행 대안의 비용(Cost)을 계산하고, 그중 비용이 가장 낮다고 판단되는 계획을 선택한다.
다만 CBO의 비용 모델에는 한계가 있다.
- (1) I/O 비용 모델
전통적인 I/O 비용 모델에서 실행계획에 표시되는 Cost는 “예상 디스크 I/O Call 횟수” 를 의미한다. 즉 캐시 효과를 적극 반영하기보다는 디스크 I/O 발생량 중심으로 판단하는 경향이 있다.
- (2) CPU 비용 모델
CPU 비용 모델에서는 예상 I/O 발생량을 시간으로 환산하고 CPU 시간까지 더해 Single Block I/O 시간 단위의 상대 비용으로 Cost를 계산한다. 하지만 이 또한 기본적으로 캐시 효과를 완벽하게 반영하는 모델은 아니다.
참고: optimizer_index_caching 같은 파라미터로 캐시 효과를 일부 고려하도록 “가정”을 줄 수는 있다.
SQL 최적화 과정: Transformer / Estimator / Plan Generator
옵티마이저가 SQL을 최적화할 때는 보통 생각보다 훨씬 많은 일을 수행한다. 예를 들어 5개 테이블 조인만 해도 조인 순서 경우의 수가 120(=5!) 가지이며, 여기에 조인 방식(NL/소트머지/해시), 액세스 경로(Full Scan/Index Range/Unique/Full/Fast Full/Skip Scan), 인덱스 선택까지 고려하면 후보가 폭발적으로 늘어난다.
옵티마이저 내부 처리는 큰 흐름으로 다음과 같이 이해하면 된다.
- Query Transformer: SQL을 더 유리한 형태로 변환(뷰 머지, 조건 푸시다운, 서브쿼리 변환 등)
- Estimator: 선택도(Selectivity), 카디널리티(Cardinality) 추정
- Plan Generator: 후보 실행계획 생성 및 비용 계산, 최종 계획 선택
하드 파싱이 “하드(Hard)”한 이유는, 이 최적화 과정에서 딕셔너리/통계정보를 읽고 수많은 후보를 평가하느라 CPU를 많이 쓰기 때문이다.
힌트(Hint)는 “명령”이지만 무시되는 경우가 있다
힌트는 사용자가 옵티마이저에 주는 지시(directive) 이지만, 항상 그대로 적용되는 것은 아니다. 다음과 같은 경우 힌트는 무시될 수 있다.
- 논리적으로 불가능한 액세스 경로를 지시한 경우
- 의미적으로 맞지 않게 힌트를 기술한 경우
- 옵티마이저가 내부적으로 쿼리 변환을 수행하면서 힌트 의미가 달라지거나 적용 대상이 사라진 경우
바인드 관련 기능들
Bind Variable Peeking (SQL Server에서는 Parameter Sniffing)
SQL이 처음 수행될 때 전달된 바인드 값을 “살짝 훔쳐보고(peek)”,
- 그 값의 컬럼 분포(히스토그램 등)를 이용해 실행계획을 결정하는 기능이다.
다만 이는 “스스로 학습하는 기능”이라기보다는, 바인드 변수 사용 시 히스토그램 활용이 제한되는 문제를 완화하려는 장치에 가깝다.
Adaptive Cursor Sharing
처음 실행계획으로 실행했다가, 바인드 값이 달라졌을 때 예상보다 I/O가 크게 늘면 다른 실행계획을 추가로 생성하고, 이후 바인드 값 분포에 따라 실행계획을 선택적으로 사용한다.
Cardinality Feedback (12c에서 Statistics Feedback으로 명칭 변경)
최초 실행 시 추정 카디널리티와 실제 실행 로우 수의 차이가 크면 보정된 카디널리티 정보를 저장해 두었다가 다음 실행에서 반영해 다른 실행계획이 수립되도록 돕는다.
Adaptive Plans (12c) 런타임에 실행계획을 바꿀 수 있는 기능들을 포함한다. 예: 통계상 작은 집합이라 생각해 NL 조인을 골랐는데, 실제로는 로우가 예상보다 많으면 해시 조인으로 전환하는 식이다.
옵티마이저 통계정보 종류
옵티마이저가 사용하는 통계정보는 크게 오브젝트 통계와 시스템 통계로 구분한다.
오브젝트 통계
- 테이블 통계: 로우 수, 블록 수, 평균 행 길이 등
- 인덱스 통계: 인덱스 높이, 리프 블록 수, 클러스터링 팩터 등
- 컬럼 통계: NDV(값 종류 수), 최소/최대값, NULL 개수, 밀도(density), 히스토그램 등
시스템 통계
- CPU 속도
- Single Block I/O 속도
- Multiblock I/O 속도
- 평균 Multiblock I/O 개수
- I/O 처리량(Throughput) 등
선택도(Selectivity)와 카디널리티(Cardinality)
선택도: 전체 레코드 중 조건절로 선택되는 비율
단순 등치 조건의 대표식: 선택도 = 1 / NDV
카디널리티: 조건절로 선택되는 레코드 “개수”
카디널리티 = 총 로우 수 × 선택도 = 총 로우 수 / NDV
옵티마이저의 한계
옵티마이저가 항상 최적의 실행계획을 만들지 못하는 이유는 대표적으로 다음과 같다.
- 오브젝트 구성 요인(인덱스, IOT, 클러스터링, 파티셔닝 등)의 복잡성
- 통계정보 부정확/불충분(샘플링 비율, 수집 주기, 보관 비용 한계)
- 결합 선택도 추정의 어려움
- 바인드 변수 사용 시 히스토그램 활용 제약
- 균등분포 가정 등 비현실적인 가정/규칙
- 최적화 시간 제약(온라인 옵티마이저는 제한된 시간 내에 빠르게 결정해야 함)
참고로 오라클에서는 자동 튜닝(오프라인 성격)의 최적화가 더 많은 기법(동적 샘플링 등)을 사용할 수 있어 더 “완벽한” 계획을 찾기도 한다.
라이브러리 캐시 크기와 실행계획의 관계
라이브러리 캐시 공간의 크기는 옵티마이저가 어떤 실행계획을 ‘생성’하는지 자체에는 직접 영향이 없다. 다만 공간이 부족하면 실행계획이 캐시에서 자주 밀려나 파싱/최적화가 반복되어 부하가 증가한다.
SQL은 “이름이 없다” → 텍스트가 곧 이름(공유/재사용)
프로시저/함수/패키지 등은 이름을 가지며 컴파일된 상태로 딕셔너리에 저장되어 재사용된다. 반면 SQL은 별도 이름이 없고, SQL 텍스트 자체가 식별자 역할을 한다.
동일 텍스트 SQL은 라이브러리 캐시에서 공유되어 하드 파싱이 줄어든다.
상수 값을 바꿔가며 실행하면 텍스트가 달라져 공유가 깨질 수 있으나, 애플리케이션 커서 캐시나 환경에 따라 “겉보기” 트레이스만으로는 단정하기 어려운 경우도 있다.
Static SQL vs Dynamic SQL (개발 관점 구분)
Static(Embedded) SQL: 코드에 직접 박아 넣는 형태(언어/도구가 지원해야 함)
Dynamic SQL: 문자열(String)에 담아 구성/실행하는 SQL
이 구분은 애플리케이션 개발 관점의 구분이며, DBMS 입장에서는 전달받은 SQL 텍스트만 인식한다. 예: Java는 일반적으로 Embedded SQL을 지원하지 않으므로 DB 관점에서는 전달되는 형태가 사실상 Dynamic SQL로 동작한다는 취지.
CURSOR_SHARING=FORCE의 부작용
CURSOR_SHARING 파라미터를 FORCE로 설정하면, “상수 값만 다른 동일 SQL”을 강제로 바인드 변수 형태로 바꿔 공유하게 만든다. 하드 파싱(하드 파스) 부하를 줄이는 효과를 기대할 수 있어 편리해 보이지만, 부작용이 크기 때문에 운영 환경에서 함부로 적용하는 것은 금물이다.
대표적인 부작용은 다음과 같다.
-
불필요한 바인드 변수 처리 비용 증가
상수 조건을 바인드 변수로 강제 변환하면 실행 때마다 바인드 변수 처리(값 대입/검사/최적화 경로 결정 등)가 수반된다. 그 결과 실제 수행 시간은 오히려 더 오래 걸리는 경우가 있다. -
히스토그램 기반 최적화가 깨져 비효율적인 실행계획이 수립될 수 있음
바인드 변수를 사용하면(또는 FORCE로 강제 변환되면) 컬럼 히스토그램 정보를 충분히 활용하기 어렵거나, 선택도 추정이 단순화되어 비효율적인 실행계획이 나올 수 있다. 특히 값 분포가 치우친 컬럼에서 문제가 두드러진다. -
함수기반 인덱스(FBI)가 있어도 인덱스를 못 타는 문제
상수를 바인드로 강제 변환하면서, 조건절 표현이 바뀌거나 데이터 타입/표현식 매칭이 어긋나면 함수기반 인덱스를 생성해두고도 사용하지 못하는 상황이 발생할 수 있다.
예를 들어 다음과 같이 FBI를 만들었다고 하자.
CREATE INDEX emp_x7 ON emp( TO_CHAR(hiredate, 'YYYYMMDD') );
그런데 아래처럼 상수 비교를 하는 SQL이 있고,
SELECT ... FROM emp e WHERE TO_CHAR(hiredate, 'YYYYMMDD') > '19870107';
여기에서 CURSOR_SHARING=FORCE가 작동해 상수 '19870107'이 바인드로 강제 변환되거나, 내부적으로 비교 방식이 달라지면(특히 타입/길이/암시적 변환 문제가 끼면) 기대와 달리 인덱스를 사용하지 못하는 실행계획이 나올 수 있다.
(정확한 현상은 트레이스/실행계획으로 확인해야 한다.)
결론적으로, 하드 파싱 부하가 우려된다는 이유만으로 CURSOR_SHARING=FORCE를 선택하기보다, 정상적인 방법으로 애플리케이션에서 바인드 변수를 사용하도록 구현하는 것이 올바른 접근이다.
쿼리 변환(Query Transformation)의 개념
쿼리 변환(Query Transformation) 이란, 결과집합은 동일하게 유지하면서도 더 나은 성능을 기대할 수 있도록 SQL을 내부적으로 다른 형태로 바꾸는 것을 말한다.
여기서 중요한 점은:
-
쿼리 변환은 “무조건 성능이 좋아지는 마법”이 아니다.
-
일반적으로 옵티마이저는 변환 전/후의 후보 실행계획들을 모두 평가하고, 그중 비용(Cost)이 가장 낮다고 판단되는 실행계획을 선택한다.
-
즉 “변환 후 SQL이 항상 더 낫다”가 아니라, “변환 후 SQL도 후보군에 올려서 비교하고 선택한다”가 원칙이다.
(일부 특수한 경우를 제외하면, 대부분 이런 비용 비교 모델로 동작한다.)
또한, 문맥상 “EXACT”는 보통 “의미적으로 동일(semantic equivalence)”을 강조하는 표현으로 쓰인다. 즉 “형태는 달라져도 결과는 같아야 한다”는 뜻이다.
서브쿼리 Unnesting
서브쿼리는 하나의 SQL 문장 안에서 괄호로 묶인 별도의 쿼리 블록을 말하며, 인라인 뷰/중첩 서브쿼리/스칼라 서브쿼리 등이 포함된다.
서브쿼리를 그대로 두면(unnesting 하지 않으면), 옵티마이저가 최적화할 수 있는 범위가 제한되고, 특히 필터(Filter) 방식으로 서브쿼리가 반복 실행되는 형태가 되기 쉽다. 이는 NL 조인과 유사한 방식이므로 대량 데이터 처리에 불리하다.
다만 서브쿼리 캐시(캐싱) 같은 메커니즘이 동작해, 서브쿼리에서 반환되는 값 종류가 매우 적을 때는 체감 성능이 크게 나쁘지 않을 수 있다.
반대로 서브쿼리를 Unnesting 하면, 옵티마이저가 조인으로 풀어내어:
-
조인 순서를 더 자유롭게 결정할 수 있고
-
NL 조인뿐 아니라 해시 조인, 소트 머지 조인 등 다양한 조인 방식으로 처리할 수 있어
-
성능 최적화에 큰 도움이 된다.
또한 고객을 먼저 드라이빙하는 경우는 세미 조인(Semi Join) 으로 처리하거나, 거래를 먼저 드라이빙하는 경우는 고객 키를 SORT UNIQUE 로 유니크 집합으로 만든 뒤 고객과 조인하는 방식이 흔하다.
View Merging과 조인 조건 Pushdown
옵티마이저의 최적화 단위는 기본적으로 쿼리 블록이다. 따라서 뷰(인라인 뷰)가 변환(merge)되지 않으면, 뷰 내부는 독립적으로 최적화된다.
문제 상황의 핵심은 보통 이런 형태다.
-
인라인 뷰 안에서는 “당월 거래”를 집계(고객번호로 GROUP BY)해야 한다.
-
그런데 메인 쿼리 바깥에 “전월 이후 가입 고객만”이라는 조건이 붙어 있다.
-
전월 이후 가입 고객이 극소수라면, 인라인 뷰에서 “당월 거래 전체”를 읽고 집계한 다음 밖에서 필터링하는 것은 매우 비효율적이다.
이때 선택지는 크게 두 가지다.
-
View Merging(뷰 머징)
뷰를 머지해 고객을 기준으로 거래와 조인한 후 그룹바이를 수행하면, “전월 이후 가입 고객”이 실제로 거래한 데이터만 읽도록 유도할 수 있어 효과적이다.
단, GROUP BY 이후에 결과를 만들어야 하므로 부분범위 처리(Stopkey)가 어렵다. -
조인 조건 Pushdown(PUSH_PRED)
뷰를 머지하지 않은 상태에서 고객을 기준으로 NL 조인을 하면서, 고객번호 조건을 인라인 뷰 안쪽으로 “밀어 넣어” 각 고객별 당월 거래만 읽고 집계하게 만들 수 있다.
이 방식은 NL 조인을 수행하다가 필요한 만큼만 읽고 멈출 수 있어서(부분범위 처리 가능) 온라인 응답 속도 최적화에 유리하다.
오라클 11g 이후부터 이런 변환/동작이 본격화되었다.
(실행계획에서 VIEW 오퍼레이션이 보이느냐/안 보이느냐는 뷰 머징 여부를 판단하는 단서가 된다. 또한 NO_MERGE, PUSH_PRED 같은 힌트로 제어할 수 있다.)
조건절 이행(Transitive Predicate Generation)
조인 조건을 바탕으로 반대편 테이블에 추론 가능한 조건절을 생성하는 쿼리 변환을 말한다.
예를 들어:
-
C.고객번호 = 1234 -
O.고객번호 = C.고객번호
라면, 내부적으로 O.고객번호 = 1234를 추론해 추가할 수 있다.
이런 변환이 적용되면, 원래 주문 쪽 WHERE에 고객번호 조건이 없어도 주문_X1(고객번호 선두) 인덱스를 타는 형태가 가능해진다.
단, NL 조인에서는 조인 과정에서 고객번호 값을 전달할 수 있어 주문 인덱스 사용이 가능하지만, 해시 조인에서는 상황이 달라질 수 있으므로 “이행 조건절 생성 여부”가 실행계획에 영향을 준다.
OR Expansion
OR Expansion은 OR 조건을 분해해 UNION ALL 형태로 변환하는 기능이다.
-
유도 힌트:
USE_CONCAT -
방지 힌트:
NO_EXPAND -
12cR2에서는
OR_EXPAND/NO_OR_EXPAND힌트가 추가되어 브랜치별 경로 제어가 더 정교해졌다.
실행계획에서 CONCATENATION 오퍼레이션이 보이면, OR Expansion이 작동한 단서다.
또한 OR 조건이 여러 곳에서 동일한 표현식을 반복하면, 옵티마이저가 공통 표현식 제거(Common Subexpression Elimination) 를 수행해 “각 로우당 한 번만 평가”하도록 줄이기도 한다.