생존분석
| 층위 관계 | 분석 기법 | 산출물 및 특징 | 통계학적 역할 |
|---|---|---|---|
| 동일 층위 (비모수적 확률 추정) | Kaplan-Meier (KM) | 생존 함수 | 시간에 따른 집단의 생존 확률(잔존율)을 시계열 계단식 곡선으로 도출 |
| Nelson-Aalen (NA) | 누적 위험 함수 | 특정 시점까지 누적된 이탈의 총체적 위험 압력 도출 | |
| 생명표 (Life Tables) | 이산화된 구간별 이탈률 | 시간을 특정 구간 단위로 묶어 이탈률 계산 (코호트 분석과 유사) | |
| 확장 층위 (변수 영향력/회귀 모델링) | Cox 비례위험 (Cox PH) | 위험 비율 (Hazard Ratio) | 피처()가 사건 발생 위험(Hazard)에 미치는 상대적 배수 영향력 분석 (준모수적) |
| AFT 모형 (Weibull 등) | 가속 인자 (Acceleration Factor) | 피처()가 사건 발생 시간(Time) 자체를 얼마나 지연/단축시키는지 배수로 분석 (모수적) |
중도 절단
-
Censored, censoring
- ex) 최근 1주일 내에 가입한 신규 유저들은 아직 가입한 지 3일밖에 안 되어서 “3일 차 이탈 여부”는 알 수 있지만 “7일 차 이탈 여부”는 알 수 없음
-
단순 통계에서는 이 유저들을 7일 차 계산에서 어떻게 처리할지 애매
-
KM 추정량은 이 유저들이 관찰된 기간(3일)까지만 ‘생존’ 확률 계산에 기여하도록 통계적으로 보정
-
기간이 서로 다른 유저 데이터를 버리지 않고 모두 활용하여 시간에 따른 정확한 생존(잔존) 확률 곡선을 그림
| 구분 | 시계열 분석 (Time Series) | 생존 분석 (Survival Analysis) |
|---|---|---|
| 시간의 역할 | 독립 변수 또는 인덱스 (X) | 종속 변수 / 타겟 그 자체 (y) |
| 분석 대상 (Target) | 특정 시점의 수치 (매출, 온도, DAU 등) | 특정 사건이 발생하기까지 걸린 시간 |
| 데이터 형태 | 일정한 간격의 연속적인 관측값 | 시작점부터 사건 발생(또는 절단)까지의 기간 |
| 특이 사항 | 추세(Trend), 계절성(Seasonality) 존재 | 중도 절단(Censoring) 데이터 포함 |
| 주요 질문 | ”내일의 주가는 얼마인가?" | "이 부품이 고장 날 때까지 얼마나 걸릴까?” |
| 대표 수식 | ||
| 핵심 모델 | ARIMA, Prophet, LSTM, ETS | KM, Cox PH, Weibull Regression |
- 생존분석만의 강력한 무기: ‘중도절단(Censoring)’
시계열 기본 가정(AR(1)): 생존 함수: 위험 함수:
두 기법은 다르지만, 고도화된 분석에서는 융합되어 사용되기도 합니다.
예를 들어 생존분석의 대표적인 모델인 **Cox 비례위험모형(Cox Proportional-Hazards Model)**을 쓸 때, 유저의 상태가 시간에 따라 변하는 경우가 있습니다. (예: 유저의 월별 결제 금액이 계속 바뀜).
이때는 시계열 데이터의 개념을 차용하여 **‘시간 가변 공변량(Time-varying Covariates)‘**이라는 형태로 생존분석 모델 안에 시계열적인 변화를 집어넣어 “결제 금액이 떨어지는 추세가 이탈 시점을 얼마나 앞당기는가?”를 분석할 수도 있습니다.
KM 그래프를 자세히 보시면 선 중간중간에 작은 십자가(+) 모양의 틱(Tick) 마크가 찍혀 있는 것을 볼 수 있습니다.
이 마크가 바로 앞서 말씀드린 생존 분석만의 고유한 특징인 **‘중도절단(Censored)‘**을 표시한 것입니다.
“이 시점(예: 가입 후 50일 차)에 어떤 유저의 관찰이 종료되었는데, 이탈해서 끝난 게 아니라 관찰 기간이 다 끝나서(또는 데이터를 유실해서) 살아있는 상태로 끝났다”는 것을 수학적으로 그래프에 반영한 흔적입니다.
시계열 분석 그래프에는 이런 개념 자체가 존재하지 않습니다.
기초
- 사건이 발생하기까지 경과하는 시간을 분석
- 시간의 경과에 따른 사건 발생의 위험도를 평가
- 시간의 경과에 따른 생존 확률을 추정
- 주로 생명 생존, 의학 연구, 고객 이탈 분석 등에 사용
| 단계 | 역할 | 역할2 | 관계의 핵심 1 | 관계의 핵심2 |
|---|---|---|---|---|
| 1. 탐색 (EDA) | KM 추정량 | NA 추정량 | 데이터를 통해 실제 생존 곡선을 그린다. (예: “우리 데이터는 처음에 확 떨어지다가 완만해지는구나.”) | 데이터를 통해 실제 누적 위험(H(t))이 어떻게 쌓이는지 본다. (예: “시간이 갈수록 위험이 급격히 증가하는가, 일정한가?“) |
| 2. 가설 설정 | AFT 분포 선택 | Cox PH 모델 | KM 곡선의 모양을 보고 적절한 수학적 분포(Weibull, Log-normal 등)를 가진 AFT 프레임워크를 선택한다. | 위험률이 공변량(X)에 의해 비례적으로 변한다는 가정을 세우고, 위험비(Hazard Ratio)를 계산한다. |
| 3. 피팅 (Fitting) | AFT 파라미터 추정 | 선택한 AFT 모델이 데이터에 가장 잘 맞도록 기울기(β)와 가속 계수(σ)를 계산한다. | ||
| 4. 검증 (Validation) | KM - AFT 비교 | NA - Cox 비교 | 모델로 도출된 AFT 곡선이 실제 데이터인 KM 곡선 위에 잘 포개지는지 확인한다. | Cox 모델이 예측한 누적 위험 곡선이 실제 데이터인 NA 곡선과 잘 일치하는지 확인한다. |
| 5. 가정 확인 | Log-log Plot | NA 추정량을 로그 변환하여 그린 그래프가 평행한지 보고, Cox 모델의 핵심인 비례위험(PH) 가정을 검증한다. |
생존 분석은 비모수 / 준모수 접근이 모수접근보다 압도적으로 메이저
유저 데이터나 의료 데이터를 다루는 일반적인 데이터 분석 환경에서는
- 분포 가정의 위험을 피하기 위해 카플란-마이어(비모수)로 시각화 및 단순 비교
- 인과관계나 변수 중요도를 볼 때는 **Cox 모형(준모수)**을 사용
가장 큰 이유:
“현실의 데이터는 예쁘고 완벽한 수학적 분포를 따르지 않기 때문”
-
모수적(Parametric) 접근의 한계:
- 특정 분포(예: 지수 분포, 와이불 분포 등)를 가정하고 시작해야 합니다.
- “우리 유저들의 이탈 패턴은 정규분포나 와이불 분포를 완벽하게 따를 거야!”라고 가정해야 하는데, 현실의 유저 행동 데이터나 환자의 생존 데이터는 훨씬 복잡하고 불규칙해서 이 가정이 틀릴 위험(Model Misspecification)이 매우 큽니다.
-
비모수적(Non-parametric) 접근의 장점:
- 카플란-마이어(KM) 분석처럼 특정 분포를 아예 가정하지 않고 “데이터가 생긴 그대로(Let the data speak for itself)” 추정합니다.
- 가정이 틀릴 위험이 없으므로 훨씬 안전하고 범용적으로 쓰입니다.
그렇다면 모수(Parametric) 접근은 언제 쓸까?
비모수가 메이저함에도 불구하고 모수적 생존 분석이 꼭 필요한 특수한 상황들이 있습니다.
-
미래 예측 (Extrapolation, 외삽):
- 비모수(KM) 곡선은 ‘관측된 데이터의 끝’까지만 그릴 수 있습니다. (예: 30일 치 데이터만 있으면 31일째 확률은 모름)
- 하지만 모수적 접근은 수식을 도출하므로, 관측되지 않은 먼 미래의 LTV(고객 생애 가치)를 예측하거나 잔존율을 길게 추정할 때 사용합니다.
-
기계/설비의 고장 분석 (신뢰성 공학):
- 사람이나 유저의 행동은 불규칙하지만, 기계 부품의 마모나 서버의 고장 시간은 특정 물리적/수학적 분포(특히 Weibull 분포)를 매우 잘 따르는 경우가 많습니다. 제조업에서는 모수적 생존 분석이 메이저합니다.
| 구분 | KM | NA | Cox (NA와 연관) | AFT (KM과 연관) |
|---|---|---|---|---|
| 본질 | 관측된 데이터의 통계적 요약 | 데이터를 설명하는 수학적 함수(모델) | ||
| 역할 | 기준점 (Benchmark) | 예측 및 요인 분석 (Prediction) | ||
| 요약 | ”현실이 이러하다" | "어떤 요인(변수) 이 생존에 영향을 미치는가?" | "이 공식(AFT)으로 그 현실(KM)을 재현할 수 있는가?" | |
| "시간에 따라 생존할 확률은?" | "시간에 따라 위험이 얼마나 누적되는가?" | "A 약물 투여 시 사망 위험이 0.5배로 감소한다." | "A 약물 투여 시 생존 시간이 2배로 연장된다.” | |
| 관측된 시점에서의 계단식 변화 | 위험 (Hazard) 중심 | 생존 시간 (Time) 중심 | ||
| 주요 산출물 | 계단식 생존 곡선 그래프, Log-rank 검정 -value | 각 변수별 위험비(HR), 회귀 계수() | 가속 인자 (AF) | |
| 모델 유형 | 비모수적 | 비모수적 | 준모수적 | 모수적 |
| 핵심 가정 | 특정 분포를 가정하지 않음 | 특정 분포를 가정하지 않음 | 기저 위험을 가정하지 않음 | 특정 수명 (확률) 분포를 가정 |
| 비례위험 가정 충족 필수 | 가속수명 가정 | |||
| 추정 대상 | 생존 함수 | 누적 위험 함수 | 위험비 (Hazard Ratio, HR) | |
| 핵심 수식 | ||||
| 주요 목적 | 시점별 생존 확률 추정 및 군간 비교 | 위험의 누적 속도 및 패턴 파악 (특정 시점에 누적된 위험의 총량) | 공변량(Covariates)의 영향력 분석 | |
| 분석 차원 | 단일 변수 분석 (Univariate) | 다중 변수 분석 (Multivariate) | ||
| 범주형 변수 1개만 가능 (성별, 투약군 등) | 연속형, 범주형 모두 동시 투입 가능, 편상관 (나이, 혈압 등) | |||
| 단일/그룹 변수 비교 (Log-rank test 사용) | 위험률의 시간적 변화 관찰에 유리 | 다변량 분석 가능, 기저 위험 가정 불필요 | ||
| 상호 관계 | (to NA) | Cox 모델의 기저 위험 추정 시 활용됨 | KM으로 차이 확인 후 Cox로 요인 분석 수행 | |
| 분석 목적 | 특정 그룹의 시간에 따른 생존 확률 추정 및 직관적 시각화 | 다중 변수가 사건 발생 위험(Hazard)에 미치는 영향력 수치화 | ||
| 실무 분석 단계 | 탐색적 데이터 분석 (EDA) 및 전반적 트렌드 파악 | 본격적인 통계 모델링 및 핵심 변수의 순수 영향도 검증 | ||
| 검증 방법 | 없음 (데이터 그 자체) | KM 곡선과 겹쳐 그리기, AIC, 잔차 분석 |
-
(및 추정량 및 위험함수)
-
non-parameteric
-
카플란-마이어 (Kaplan-Meier)
- 카플란-마이어 (Kaplan-Meier) 생존 확률 추정량
- 생존함수 추정량:
- 교란변수 통제 불가능
- 다른 요인의 영향을 분리할 수 없음
- 연속형 변수 불가: ‘나이’, ‘체중’, ‘혈압’ 같은 연속형 변수는 그대로 넣을 수 없습니다. 분석하려면 “60세 이상/미만”처럼 억지로 범주화를 해야 합니다.
- 교란 변수 통제 불가: 예를 들어 A약을 먹은 그룹이 B약을 먹은 그룹보다 생존율이 높게 나왔더라도, A약 그룹에 젊은 사람이 더 많아서 그런 것인지(교란 변수) KM 분석만으로는 알 수 없습니다.
-
넬슨-알렌 (Nelson-Aalen)
- 넬슨-알렌 (Nelson-Aalen) 누적 위험 추정량
- 누적위험함수 추정량
-
semi-parameteric
-
콕스 비례위험 모델 (Cox PH)
- 위험비 (Hazard Ratio)
- 단일 Cox 회귀 모델
- 비례위험 위험 함수 =
- 비례위험 가정 (Proportional Hazards Assumption, 위험을 특정 배수로 증가/감소시킴) 충족 필수
- 교란변수 통제 가능
- 다른 요인 통제 하의 순수 영향력 파악
-
parameteric
-
AFT (Accelerated Failure Time)
-
Weibull, Log-normal, Log-logistic AFT 모델
-
-
가속 수명 가정 (생존 시간을 특정 배수로 연장/단축시킴)
-
주의점 (가정): 시간의 흐름에 상관없이 두 그룹 간의 위험비율이 일정해야 한다는 ‘비례위험 가정(Proportional Hazards Assumption)‘을 충족해야만 정확한 결과가 나옵니다. (이전 질문에서 언급하셨던 특정 시간 이후 양성률 증가 현상이 나타나면 이 가정이 깨지게 됩니다.)
-
AFT 모델에서 KM 곡선은 모델의 ‘재료’로 사용되는 것이 아니라, 모델의 가정이 타당한지를 평가하는 ‘정답지’ 또는 ‘기준선(Baseline)’ 역할
-
비모수적 추정치가 모수적 모델의 가정을 검증하는 독립적인 벤치마크가 되는 것
-
-
카플란-마이어: “시간이 지남에 따라 살아남을 확률이 어떻게 되는가?”에 대한 직접적인 답
-
시간에 따라 생존율이 계단식으로 떨어지는 ‘생존 곡선’으로 시각화
- 로그-순위 검정: 카플란-마이어 곡선 간의 ‘차이’를 검정
-
비모수적(Non-parametric): 데이터의 분포에 대한 가정이 필요 없습니다.
-
시각화: 생존 양상을 직관적으로 이해하기 좋습니다.
-
한계: 다른 변수(나이, 성별 등)의 영향을 동시에 고려하기 어려움 (그룹을 나누어 비교는 가능)
-
-
넬슨-알렌: “시간이 지남에 따라 사건이 발생할 위험이 얼마나 쌓이는가?”
- 시간에 따라 누적 위험이 계단식으로 증가하는 곡선으로 시각화
- 비모수적(Non-parametric): KM과 마찬가지로 분포에 대한 가정이 없습니다.
- KM과의 관계: 넬슨-알렌과 카플란-마이어는 동전의 양면과 같다.
- 하나를 알면 다른 하나를 근사적으로 계산 가능
- 생존율 관점에서 보느냐, 누적된 위험 관점에서 보느냐의 차이일 뿐
- 데이터의 동일한 생존 양상을 다른 척도로 표현
- KM이 ‘생존’이라는 긍정적 측면
- NA는 ‘위험’이라는 부정적 측면
-
Cox: 여러 예측 변수(Covariates) 들(예: 나이, 치료법, 혈액 수치 등)이 생존 시간(위험) 에 어떤 영향을 미치는지 분석하는 회귀 분석
-
각 변수에 대한 위험 비율(Hazard Ratio, HR) 을 결과로 제시
- HR = 1: 해당 변수는 생존에 영향 없음
- HR > 1: 해당 변수는 사건 발생 위험을 높임 (생존에 부정적)
- HR < 1: 해당 변수는 사건 발생 위험을 낮춤 (생존에 긍정적)
-
준모수적(Semi-parametric): 모델의 일부(변수의 영향)는 모수적 가정을 따르지만, 일부(기저 위험 함수)는 가정이 없는 비모수적 형태
-
다변수 분석: 여러 변수의 영향을 동시에 통제하고 각 변수의 순수한 영향력을 평가
-
-
즉:
-
KM 등을 통해 그룹 간 생존율 차이가 관찰된다면, “그 차이가 단순히 그룹 효과 때문일까, 아니면 다른 변수(나이, 성별 등)의 영향도 있을까?” 에 대한 의문
- 이때 COX 를 사용하여 여러 변수를 동시에 고려하고, 각 변수가 생존에 미치는 독립적인 영향을 정량적으로 분석
-
cox 모델의 핵심 구성 요소 중 하나인 ‘기저 위험 함수(baseline hazard function)‘는 넬슨-알렌 추정량과 개념적으로 매우 유사함
- NA 는 cox 의 이론적 기반
-
Cox-NA / AFT-KM
Q. KM과 NA 는 비모수적으로 추출된다. 그런데 왜 semi-모수적인 cox 와 완전모수적인 aft 에 저 둘이 사용될 수 있는가?
A. 비모수적 추정량(KM, NA)은 모수/준모수적 모델의 ‘입력 데이터’가 아니라, 모델의 구조적 뼈대를 이루거나 가정을 검증하는 독립적인 벤치마크(정답지) 역할을 수행한다.
| 구분 | Cox 모형 (준모수적) + 넬슨-알렌(NA) | AFT 모형 (완전모수적) + 카플란-마이어(KM) |
|---|---|---|
| 활용 목적 | 모델의 구조적 뼈대(기저 위험) 형성 | 모델의 분포 가정 타당성 검증 (Goodness-of-fit) |
| 모델 성격 | 준모수적 (비례 관계만 가정) | 모수적 (특정 분포 가정) |
| 현실 데이터 | NA (누적되는 위험 곡선) | KM (계단식 생존 곡선) |
| 중점 지표 | 누적 위험 () | 생존 확률 () |
| 수식적 근거 | ||
| 비모수 지표의 역할 | 기저 위험 함수 의 형태를 가정하지 않고 데이터로부터 비모수적으로 직접 추정 (NA 개념) | AFT 추정 곡선과 KM 경험적 곡선을 겹쳐 그려, 에 대한 특정 분포(Weibull 등) 가정이 맞는지 평가 |
| 파라미터 추정 | 변수 효과 부분만 모수적으로 추정 | 분포의 모수와 회귀 계수 모두를 모수적으로 추정 |
| 핵심 요약 | NA는 Cox 모델 내에서 **‘비모수적 절반’**을 담당함 | KM은 AFT 모델을 외부에서 검증하는 **‘채점 기준표’**임 |
| 관계의 요체 | ”이 위험비(Cox)가 실제 위험(NA)의 흐름을 반영하는가?" | "이 수식(AFT)이 실제 생존(KM)을 재현하는가?” |
AFT 모델은 Cox 모델과 달리 **완전모수적(Fully Parametric)**입니다. 이는 Cox 모델의 h₀(t)에 해당하는 부분, 즉 기저 생존 시간 분포까지 특정 확률 분포(예: Weibull, Log-normal)를 따른다고 가정하기 때문입니다.
여기서 ε (오차항)의 분포를 Weibull, Log-normal 등으로 가정합니다. 그렇다면 비모수적인 KM은 여기서 어떤 역할을 할까요?
-
모델 선택의 근거 (Model Selection)
- AFT 모델을 적용하기 전에, 먼저 KM 곡선을 그려 데이터의 생존 패턴을 시각적으로 확인합니다.
- KM 곡선의 모양이 특정 확률 분포(예: Weibull 분포의 생존 곡선)와 유사해 보인다면, “이 데이터는 Weibull AFT 모델로 분석하는 것이 적절하겠다”라고 판단하는 근거가 됩니다.
-
모델 적합도 검증 (Goodness-of-fit)
- 이것이 가장 중요한 역할입니다. Weibull AFT 모델을 사용하여 분석을 완료하면, 모델은 예측된 모수적 생존 곡선을 그려낼 수 있습니다.
- 이때, 아무런 가정이 없는 순수한 데이터 기반의 비모수적 KM 곡선을 같은 그림에 겹쳐 그립니다.
- 만약 두 곡선이 매우 유사하다면? -> “내가 가정한 Weibull 분포가 데이터를 잘 설명하고 있구나!” 라고 모델의 적합성을 확인할 수 있습니다.
- 만약 두 곡선이 크게 다르다면? -> “Weibull 분포 가정은 잘못되었구나, 다른 분포(예: Log-normal)를 고려해야겠다” 라고 판단할 수 있습니다.
| 구분 | 모델링 이전 (단변량 비교) | 콕스 모형 검증 (통계적) | 콕스 모형 검증 (시각적) |
|---|---|---|---|
| 핵심 철학 (연관 추정량) | 시간 (카플란-마이어, KM) | 위험 (넬슨-알렌, NA) | 위험 (넬슨-알렌, NA) |
| 검증 대상 및 목적 | 집단 간 생존 곡선(잔존율)의 차이 유무 | 비례 위험(PH) 가정 (변수의 효과가 시간에 따라 일정한가) | 비례 위험(PH) 가정 (통계적 검증의 보완) |
| 주요 검증 방법 | 로그-순위 검정 (Log-rank Test) | 쉔펠트 잔차 (Schoenfeld Residuals) 검정 | 로그-로그 플롯 (Log-log Plot) |
| 판단 기준 및 해석 | 두 그룹의 관측치와 기대치 비교 ( 시 집단 간 유의한 차이 존재) | : 비례 위험 가정 만족. 이어야 모델 사용 타당함 | 그룹 간 변환된 생존 곡선이 서로 평행하면 가정을 만족하는 것으로 간주 |
import pandas as pd; import numpy as np; import matplotlib.pyplot as plt; plt.clf()
import seaborn as sns
import lifelines
import lifelines.datasets
rossi = lifelines.datasets.load_rossi(); df=rossi
# ============================================================================
# 한글 폰트 및 시각화 스타일 설정 (선택 사항)
# ============================================================================
# plt.style.use('seaborn-v0_8-whitegrid')
# plt.rcParams['font.family'] = 'Malgun Gothic' # 윈도우 폰트 설정 (맥: AppleGothic)
# plt.rcParams['axes.unicode_minus'] = FalseKM
- durations: 관찰이 시작된 시점(가입일)부터 종료(이탈일 또는 데이터 추출일)까지 걸린 시간(기간) 입니다.
- event_observed: 해당 기간의 끝에 유저가 실제로 **이탈(1)**했는지, 아니면 아직 활성 상태라서 관찰이 중단된 Censored(0) 상태인지를 나타내는 이진 지표입니다.
AFT 모델 외 KM 의 또 다른 역할
-
모수적 모델의 적합도 검정 (Goodness-of-fit):
- Weibull이나 Log-normal 같은 모수적 생존 모델을 데이터에 적합시킨 후, 이 모델이 예측하는 생존 곡선과 비모수적인 KM 생존 곡선을 비교합니다.
- 두 곡선이 시각적으로 유사하다면, 우리가 가정한 분포가 데이터에 잘 맞는다고 판단할 수 있습니다. 즉, KM 곡선이 모델의 적절성을 평가하는 ‘기준선’ 역할을 하는 것입니다.
-
의사결정나무 기반 생존 분석 (Survival Trees):
- rpart와 같은 패키지에서 생존 분석을 수행할 때, 노드를 분기하는 기준(splitting rule)으로 그룹 간의 생존 곡선 차이를 이용합니다. 이 과정에서 내부적으로 카플란-마이어의 개념이 활용됩니다.
- 결론적으로, 콕스 모델이 NA와 ‘위험’이라는 개념으로 짝을 이룬다면, AFT 모델은 KM과 ‘생존 시간/확률’이라는 개념으로 짝을 이룬다고 볼 수 있습니다. KM은 또한 다른 여러 모델의 결과를 검증하거나 기반을 이루는 핵심적인 도구로 폭넓게 활용됩니다.
logrank 검정:
-
이름의 유래는, 각 시점에서의 ‘위험도(Hazard)의 비율(Log-hazard ratio)‘을 기반으로 랭크 스코어를 매기는 방식과 동일하게 유도될 수 있기 때문
- 실제 계산 과정에서 로그나 순위를 직접 씌우지는 않음
-
본질적으로 로그랭크 검정은 시간을 쪼개서 반복하는 카이제곱 검정과 동일 (관측치 vs 기대치)
- 유저가 이탈(사건 발생)하는 매 순간(Time )마다 정지
- 그 시점에 살아남아 있는 남성과 여성의 비율 확인
- “두 집단의 이탈률이 같다면 이 시점에서 남성과 여성이 각각 몇 명씩 이탈했어야 정상인가?(기대빈도, Expected)“를 체크
- “실제로 몇 명이 이탈했는가?(관측빈도, Observed)“와 비교
- 모든 시점에서의 (관측치 - 기대치) 차이를 누적 합산하여 최종 pval 도출
| 구분 | 순위 검정 (Rank Test, e.g., Mann-Whitney) | 로그랭크 검정 (Log-rank Test) |
|---|---|---|
| 데이터 유형 | 연속형 또는 순서형 수치 데이터 | 시간(Time) + 사건 발생 여부(Event/Censoring) |
| 분석 대상 | 데이터의 분포 또는 중앙값(Median) | 생존 함수(Survival Function)의 궤적 |
| 핵심 기제 | 전체 데이터를 순위로 변환하여 순위 합 비교 | 각 사건 발생 시점에서의 관측값과 기대값 비교 |
| 주요 가정 | 독립성, 분포의 상사성 (정규성 불필요) | 비례 위험 가정 (Proportional Hazards Assumption) |
| 통계량 수식 | ||
| 사용 시점 | 정규성 가정이 깨진 두 집단의 평균/순위 비교 | 두 집단의 잔존율(Survival Rate) 차이 검정 |
-
KM 추정: 데이터에서 실제 생존 곡선을 그려 전체적인 생존 양상을 파악한다.
-
분포 가설 설정: KM 곡선의 형태를 보고 “이 데이터는 Weibull 분포를 따르는 AFT 모델이 적합할 것이다”라고 가설을 세운다.
-
모델 학습: MLE(최대우도추정)를 통해 AFT 모델의 파라미터를 추정한다.
-
적합도 검정: AIC를 비교하거나 Cox-Snell 잔차 플롯을 그려 모델의 타당성을 최종 판정한다. (로그순위 검정은 이 단계에서 사용하지 않는다.)
| 판정 도구 | 방법 및 의미 |
|---|---|
| AIC / BIC | 여러 분포(Weibull, Log-normal 등)를 사용한 AFT 모델 중 어떤 것이 최적인지 비교. 수치가 작을수록 적합도가 높음. |
| Cox-Snell 잔차 | 모델이 정확하다면 잔차의 누적위험함수는 원점을 지나는 기울기 1인 직선()을 따라야 함. 이를 시각적으로 확인. |
| 우도비 검정 (LRT) | 중첩된(Nested) 모델 간의 유의성을 비교하여 변수 추가나 모델 확장이 타당한지 검정. |
| P-P Plot / Q-Q Plot | 데이터의 실제 분포와 모델이 가정한 확률 분포가 일치하는지 확인. |
# 1. 타겟 변수 분리 (T: Time, E: Event, X: 모델에 들어갈 독립변수, 특성)
# T = df['week']; E = df['arrest']; X = df.drop(['week', 'arrest'], axis=1)
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(5, 3))
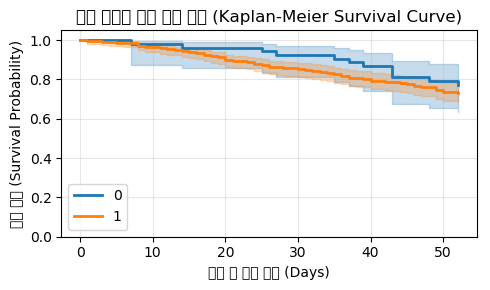
target = 'race'
if 'KM':
for curr_elm in sorted(df[target].unique()):
curr_df = df[df[target]==curr_elm]
# 1. 타겟 변수 분리 (T: Time, E: Event, X: 모델에 들어갈 독립변수, 특성)
T = curr_df['week']; E = curr_df['arrest']; X = curr_df.drop(['week', 'arrest'], axis=1)
from lifelines import KaplanMeierFitter
kmf = lifelines.KaplanMeierFitter()
# kmf.fit(T, E)
kmf.fit(durations=T, event_observed=E, label=curr_elm)
if '생존곡선':
# kmf.plot_survival_function(ax=ax, ci_show=True, linewidth=2)
ax = kmf.plot_survival_function(ci_show=True, linewidth=2)
# print("\n--- Cox 모형 분석 결과 ---")
# cph.print_summary()
if '시각화':
ax.set(title='유저 성별에 따른 잔존 확률 (Kaplan-Meier Survival Curve)' # , fontsize=15
, xlabel='가입 후 경과 일수 (Days)' # , fontsize=12
, ylabel='잔존 확률 (Survival Probability)' # , fontsize=12
, ylim=[0.0, 1.05]
)
ax.legend(loc='lower left')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
[Log-Rank Test 결과]
검정 통계량 (Test Statistic): 0.5761
P-value: 0.4478
결론: pval 0.45 은 0.05보다 작음.
>> cat 간 생존(잔존) 곡선의 통계적 차이는 유의하다고 판단됨.
결론: pval 0.45 은 0.05보다 큼.
>> cat 간 생존(잔존) 곡선의 통계적 차이는 유의하지 않다고 판단됨.
log-rank
| 항목 | 내용 |
|---|---|
| 귀무가설 ( ) | 모든 집단의 생존 함수는 동일하다. () |
| 대립가설 ( ) | 적어도 한 집단의 생존 함수는 다르다. |
| 검정 방식 | 비모수적(Non-parametric) 검정 (데이터의 특정 분포를 가정하지 않음) |
| 주요 특징 | 사건(사망 등)이 발생한 모든 시점에서 **관측값(Observed)**과 **기댓값(Expected)**의 차이를 합산하여 계산함. |
로그순위 검정(Log-rank Test) 의 유일하고 명확한 용도는 **“두 개 이상의 집단 간의 생존 곡선(Survival Curve)이 통계적으로 서로 다른지 비교”**하는 것이다.
쉽게 말해, 카플란-마이어(KM) 플롯으로 그린 두 선이 “우연히 갈라진 것인지, 아니면 정말 집단 간의 생존율에 차이가 있는 것인지” 를 p-value로 판정해주는 도구다.
| 구분 | 로그순위 검정 (Log-rank) | Cox 비례위험 모델 |
|---|---|---|
| 성격 | 단순 집단 간 비교 (검정) | 변수의 영향력을 분석하는 회귀 모델 |
| 독립 변수 | 범주형 변수 (그룹 A vs B) | 범주형 + 연속형 변수 모두 가능 |
| 결과물 | p-value (차이가 있다/없다) | 위험비(Hazard Ratio), 회귀 계수(β) |
| 용도 | 단순한 집단 간 생존율 비교 | 여러 요인(나이, 혈압 등)을 동시에 통제한 분석 |
이제 로그순위 검정에서 곡선이 교차할 때 발생하는 문제점과, 이를 해결하기 위한 **가중 로그순위 검정(Weighted Log-rank Test)**의 종류에 대해 알아볼까?
ADP 실기에서 AFT 모델을 구현할 때, Weibull 분포를 선택했다면 이 모델이 Cox 비례위험(PH) 가정도 동시에 만족한다는 사실을 알고 있는가? 이 수리적 특성은 AFT와 Cox를 연결하는 중요한 지점인데, 이 부분에 대한 보충 설명이 필요한가?
if 'logrank 테스트':
# 통계적 유의성 검정 (Log-Rank Test)
# 두 집단의 생존 곡선이 전체적으로 유의미한 차이가 있는지 검정
T_name = 'week'; E_name = 'arrest'
from lifelines.statistics import logrank_test
results = logrank_test(
durations_A=df[df[target]==sorted(df[target].unique())[0]][T_name]
, durations_B=df[df[target]==sorted(df[target].unique())[1]][T_name]
, event_observed_A=df[df[target]==sorted(df[target].unique())[0]][E_name]
, event_observed_B=df[df[target]==sorted(df[target].unique())[1]][E_name]
)
print(f"\n[Log-Rank Test 결과]")
print(f"검정 통계량 (Test Statistic): {results.test_statistic:.4f}")
print(f"P-value: {results.p_value:.4f}")
# 해석
alpha = 0.05
print(f"""결론: pval {results.p_value:.2f} 은 {alpha}보다 작음.
>> cat 간 생존(잔존) 곡선의 통계적 차이는 유의하다고 판단됨.""")
print(f"""결론: pval {results.p_value:.2f} 은 {alpha}보다 큼.
>> cat 간 생존(잔존) 곡선의 통계적 차이는 유의하지 않다고 판단됨.""")
NA
from lifelines import NelsonAalenFitter
# E: 이벤트 발생 여부 (1: 발생, 0: 중도 절단/censored)
T = curr_df['week']; E = curr_df['arrest']; X = curr_df.drop(['week', 'arrest'], axis=1)
if 'NA 추정량':
naf = lifelines.NelsonAalenFitter()
naf.fit(durations=T, event_observed=E)
# print("--- Nelson-Aalen 누적 위험 추정치 ---")
# display(naf.cumulative_hazard_.head())
if '누적 위험 곡선':
fig, ax = plt.subplots(figsize=(10, 6))
naf.plot_cumulative_hazard(label="Nelson-Aalen 추정치")
ax.set(title = "Nelson-Aalen 누적 위험 곡선", xlabel = "타임라인 (시간)"
, ylabel = "누적 위험 (Cumulative Hazard)")
ax.grid(True, alpha=0.3)
plt.show()Cox
Cox 모델은
-
변수의 효과(β)는 모수적으로 추정
-
시간의 흐름에 따른 기저 위험()은 비모수적으로 남긴다
- 이것이 semi-모수적인 이유
- NA는 이 비모수적 부분을 구성하는 핵심 아이디어
-
: 모수적 (Parametric) 부분
- 이 부분은 변수 X가 위험(Hazard)에 미치는 영향(exp(β))이 특정 형태(지수 함수)를 따른다고 가정
- 명확한 파라미터 β를 추정하므로 모수적
- X는 예측 변수(나이, 성별 등)
- β는 우리가 추정해야 할 회귀 계수(파라미터)
- 예를 들어, “나이가 1살 증가할 때마다 위험이 exp(β)배 증가한다”고 명확히 정의
- 이 부분은 변수 X가 위험(Hazard)에 미치는 영향(exp(β))이 특정 형태(지수 함수)를 따른다고 가정
-
: 비모수적 (Non-parametric) 부분
- 이것이 바로 기저 위험 함수(Baseline Hazard Function)
- 모든 예측 변수 X의 값이 0일 때의 순수한 위험 함수를 의미
- Cox 모델의 가장 큰 특징은 이 h₀(t)의 형태에 대해 아무것도 가정하지 않는다는 것
- 즉, “시간에 따른 기저 위험이 Weibull 분포를 따른다” 또는 “지수 분포를 따른다”와 같은 가정을 전혀 하지 않음
- h₀(t)는 데이터로부터 형태를 자유롭게 추정
- 이 방식이 바로 넬슨-알렌(NA) 추정량과 개념적으로 동일
- 모델은 h₀(t)의 구체적인 모양을 몰라도, 비례 위험 가정만 만족하면 β를 추정할 수 있음
- 분석이 끝난 후, 원한다면 추정된 β와 데이터를 이용해 h₀(t)를 비모수적으로 그려볼 수 있음
- 이것이 바로 기저 위험 함수(Baseline Hazard Function)
# =======================================================================
# Cox PH
# =======================================================================
if 'Cox PH':
# from linfelines import CoxPHFitter
cph = lifelines.CoxPHFitter()
cph.fit(df, duration_col='week', event_col='arrest')
# print("\n--- Cox 모형 분석 결과 ---")
# cph.print_summary()
if '누적 위험 곡선':
fig, ax = plt.subplots(figsize=(10, 6))
cph.plot_partial_effects_on_outcome(covariates='prio', values=[0, 2, 4, 6, 8, 10], ax=ax)
ax.set(title="과거 체포 횟수(prio)에 따른 생존 곡선 변화"
, xlabel="시간 (주)", ylabel="생존 확률")
ax.grid(True, alpha=0.3)
plt.show()
log-log
로그-로그 플롯(Log-log plot)이 평행선을 그려야 하는 수학적 근거는 다음과 같다.
콕스 모형의 생존 함수는 이다. 양변에 −log를 취하고 다시 log를 취하면 다음 수식이 도출된다.
이 수식에서 βX는 시간에 독립적인 상수이므로, 서로 다른 공변량 X1, X2 를 가진 두 그룹의 그래프는 만큼의 일정한 간격을 유지하며 평행해야 한다.
만약 곡선이 교차한다면 β가 시간 t에 따라 변한다는 뜻이므로 비례 위험 가정이 위배된 것이다.
- 쉔펠트 잔차의 귀무가설: (회귀 계수가 시간에 독립적임)
마팅게일
| 카테고리 | 관련 방법론 | 마팅게일(Martingale) 연관성 및 활용 |
|---|---|---|
| 생존 분석 | Nelson-Aalen / KM 추정량 | 관측된 사건 수와 누적 위험(Compensator)의 차이가 마팅게일 과정을 이룸. 추정량의 점근적 성질(일치성, 분산) 증명에 사용. |
| 생존 분석 | Cox 비례위험 모형 | Cox 모형을 학습시킨 후, 모델이 데이터에 잘 맞는지(Goodness-of-fit) 확인하기 위해 **마팅게일 잔차(Martingale Residuals)**를 산출하여, 연속형 공변량()과 로그 위험도 간의 선형성 가정 및 모형 적합도(Goodness-of-fit) 검증. |
| 전통적 시계열 | ARIMA (랜덤 워크) | 차분 모형인 ARIMA(0,1,0)은 이산 시간(Discrete-time) 마팅게일의 대표적 예시. 효율적 시장 가설 및 정상성 검정의 기반. |
| 상태/시퀀스 | 마르코프 체인 (Markov Chain) | 마르코프 체인(조건부 확률 의존성)에 보상 함수를 결합하여 조건부 기댓값 제약을 걸면 마팅게일로 확장됨. |
-
마팅게일의 기본 정의 (조건부 기댓값):
-
Cox 모형에서의 마팅게일 잔차 (i번째 관측치):
- 여기서 는 실제 사건 발생 여부, 뒤의 항은 모형이 예측한 누적 위험이다.
- 완벽한 모형이라면 잔차의 기댓값은 0이 된다.
-
NA / KM:
- 특정 시점까지 사건(이탈 등)이 발생한 횟수에서, 발생할 것으로 ‘기대’되는 누적 위험(Compensator)을 뺀 차이가 바로 마팅게일 과정을 이룸.
- 즉, 시간에 따른 관측값과 기댓값의 차이가 평균적으로 0이 되는(predictable하지 않은) 마팅게일의 성질을 이용하여 KM과 Nelson-Aalen 추정량의 분산(Variance)과 일치성(Consistency)을 수학적으로 증명합니다.
-
Cox:
- 마팅게일 잔차(Martingale Residuals) 는 관측된 이탈 여부(0 또는 1)에서 모형이 예측한 누적 위험을 뺀 값
- 이 잔차 플롯을 그려서 특정 연속형 변수(예: 유저의 레벨, 과금액)가 로그-위험도와 ‘선형 관계’를 가지는지 검증하고 변환(Transformation) 여부를 결정
-
ARIMA 모형(특히 Random Walk)
-
마팅게일이 ‘효율적 시장 가설(과거의 정보로 미래의 가격 변화를 예측할 수 없다)‘을 설명하는 핵심 수학적 모델로 사용
-
ARIMA 모형 중 차분(d=1)을 수행하는 가장 단순한 형태인 ARIMA(0,1,0), 즉 랜덤 워크(Random Walk) 모형이 이산 시간(Discrete-time) 마팅게일의 가장 대표적인 예시
-
현재 시점()까지의 모든 정보가 주어졌을 때, 내일()의 주가 기댓값이 정확히 오늘()의 주가와 같다고 가정하는 구조
-
-
마르코프 체인(Markov Chain)
- 마팅게일이 ‘효율적 시장 가설(과거의 정보로 미래의 가격 변화를 예측할 수 없다)‘을 설명하는 핵심 수학적 모델로 사용
- 마팅게일과 마르코프 체인은 밀접한 사촌 관계
- 마르코프 체인은 ‘내일의 상태는 오직 오늘의 상태에만 의존한다’는 조건부 확률의 성질을 의미하고, 마팅게일은 ‘내일의 기댓값이 오늘의 값과 같다’는 조건부 기댓값의 성질을 의미
- 특정 조건을 만족하는 마르코프 체인은 마팅게일이 되기도 함
실무 데이터 분석 관점에서 마팅게일이라는 용어는 보통 두 가지 상황에서 마주치게 됨:
- 시계열/금융 데이터 예측: 데이터가 랜덤 워크(마팅게일)를 따르는지 검정하여 예측 모델(ARIMA 등)의 차분 필요성을 판단할 때.
- 이탈률/생존 분석: Cox 회귀 모형을 적합한 후, **마팅게일 잔차(Martingale Residuals)**를 분석하여 피처(Feature)의 비선형성을 체크하고 모형을 튜닝할 때.
특정 duration 이후, 양성률 증가하는 경우
생존 분석에서 특정 시점(Duration) 이후 위험률(Hazard Rate, 양성률)의 변화를 포착하는 것은 콕스 모형의 핵심 전제인 ‘비례위험 가정(Proportional Hazards Assumption)‘이 위배되는 상황을 다루는 고급 분석 기법.
| 구분 | 시간 가변 Cox 모형 (Time-Varying Cox) | 쉔펠트 잔차 검정 (Schoenfeld Residuals) | 변곡점 탐지 (Change-Point Detection) |
|---|---|---|---|
| 핵심 분석 논리 | 기준 시점(Duration) 전후로 데이터를 분할(Episode split)하여, 시점 이후의 위험비(HR) 증가 여부 확인 | 잔차 산점도를 통해 특정 시점 이후 잔차가 우상향하는지 시각적/통계적 검정 | 위험률이 급변하는 전환점(Change-point)을 데이터로부터 역추정 (MLE, 최소제곱법 활용) |
| 주요 활용 툴 및 함수 | Python lifelines: CoxTimeVaryingFitterR survival: survSplit(), coxph() | Python lifelines: proportional_hazard_testR survival: cox.zph() | Python ruptures (누적 위험 함수 응용)R segmented |
| 통계적 목적 및 산출물 | 구간별 회귀계수()를 직접 추정하여 양성률 증가의 통계적 유의성 확정 | 비례위험 가정 위배 여부 진단 ( 시 시간에 따른 위험률 변동 인정) | 양성률이 급증하는 정확한 ‘특정 시점(Duration)’ 자체를 수학적으로 탐색 |
Cox
- Episode split 이후, 특정 duration 이후 구간에 적용되는 ‘시간 가변 공변량(Time-varying covariate)‘을 생성하여 회귀계수가 유의미하게 커지는지(양성률 증가) 확인
쉔펠트
- 시간에 따른 위험비가 일정하다는 비례위험 가정이 깨졌는지(즉, 시간에 따라 양성률이 변동하는지)를 통계적으로 검정
- 특정 duration 이후 잔차가 우상향하는 패턴을 보인다면 해당 시점부터 양성률이 상승하고 있음을 직관적으로 증명
변곡점
-
만약 양성률이 급증하는 “특정 duration”을 분석가가 미리 지정하는 것이 아니라, 데이터로부터 양성률이 변하는 전환점(Change-point)을 추정하고 싶을 때 사용
-
초기에는 낮은 위험률을 유지하다가 특정 시점을 지나면서 위험률이 높아지는 두 가지 상태(Two-phase hazard)를 가정
- 최대우도추정(MLE)이나 Kaplan-Meier 추정법과 최소제곱법을 결합하여 위험률이 급변하는 변곡점의 위치(시간)를 탐색