시계열
import numpy as np; import pandas as pd
import matplotlib.pyplot as plt; plt.clf()
import statsmodels.api as sm
df = sm.datasets.macrodata.load_pandas().data
df['date'] = pd.PeriodIndex(df['year'].astype(int).astype(str)+'-Q'+df['quarter'].astype(int).astype(str), freq='Q').to_timestamp()
# co2 Mauna Loa 화산의 대기 중 이산화탄소 농도 주간(Weekly), 강한 계절성과 추세
# df = sm.datasets.co2.load_pandas().data
# sunspots 연간 태양 흑점 활동 수 (1700~2008) 연간(Yearly), 주기적 패턴
# df = sm.datasets.sunspots.load_pandas().data
# macrodata 미국 거시경제 지표 (GDP, 실업률, 소비자물가 등) 분기별(Quarterly), 다변량 시계열
# df = sm.datasets.macrodata.load_pandas().data
# nile 나일강의 연간 유량 데이터 (1871~1970) 연간(Yearly), 변화점 탐색에 용이
# df = sm.datasets.nile.load_pandas().data
# elnino 엘니뇨 관련 해수면 온도 데이터 월별(Monthly), 계절성 분석
# df = sm.datasets.elnino.load_pandas().data
# from ucimlrepo import fetch_ucirepo
# bike_sharing = fetch_ucirepo(id=275)
# y = bike_sharing.data.targets; X = bike_sharing.data.features
# series = pd.concat([X,y], axis=1).groupby(['dteday'], as_index=False)['cnt'].sum().set_index('dteday')평활법:시계열 데이터에서 노이즈를 줄이고 추세나 패턴을 더 명확하게 파악하기 위해 사용되는 기법입니다
- 불규칙 요인(노이즈)을 제거하여 시계열의 기본 패턴을 파악하기 위한 기법.
| 평활법 종류 | 특징 및 적용 환경 | 사용 데이터 | 가법 모형 가능 여부 | 승법 모형 가능 여부 |
|---|---|---|---|---|
| 단순 이동평균법 (Simple MA) | 뚜렷한 추세나 계절성이 없을 때 사용 | 최근 개의 데이터 | 해당 없음 (X) | 해당 없음 (X) |
| 이중 이동평균법 (Double MA) | 선형 추세가 존재할 때 사용 (이동평균의 평균) | 최근 개의 데이터 | 가능 (O, 선형 추세) | 불가 (X) |
| 단순 지수평활법 (SES) | 뚜렷한 추세나 계절성이 없을 때 사용 | 모든 과거 데이터 | 해당 없음 (X) | 해당 없음 (X) |
| 홀트 모형 (Holt) | 선형 또는 지수 추세가 존재할 때 사용 | 모든 과거 데이터 | 가능 (O, 가법 추세) | 가능 (O, 승법 추세) |
| 윈터스 모형 (Holt-Winters) | 추세와 계절성이 모두 존재할 때 사용 | 모든 과거 데이터 | 가능 (O) | 가능 (O) |
-
단순 이동평균법 & 단순 지수평활법(SES): 이 두 기법은 데이터의 수준(Level)만을 평활화할 뿐, 추세나 계절성 요인을 분리하여 모델링하지 않는다. 따라서 요인들을 더할 것인지 곱할 것인지 결정하는 ‘가법/승법 모형’의 개념 자체가 적용되지 않는다.
-
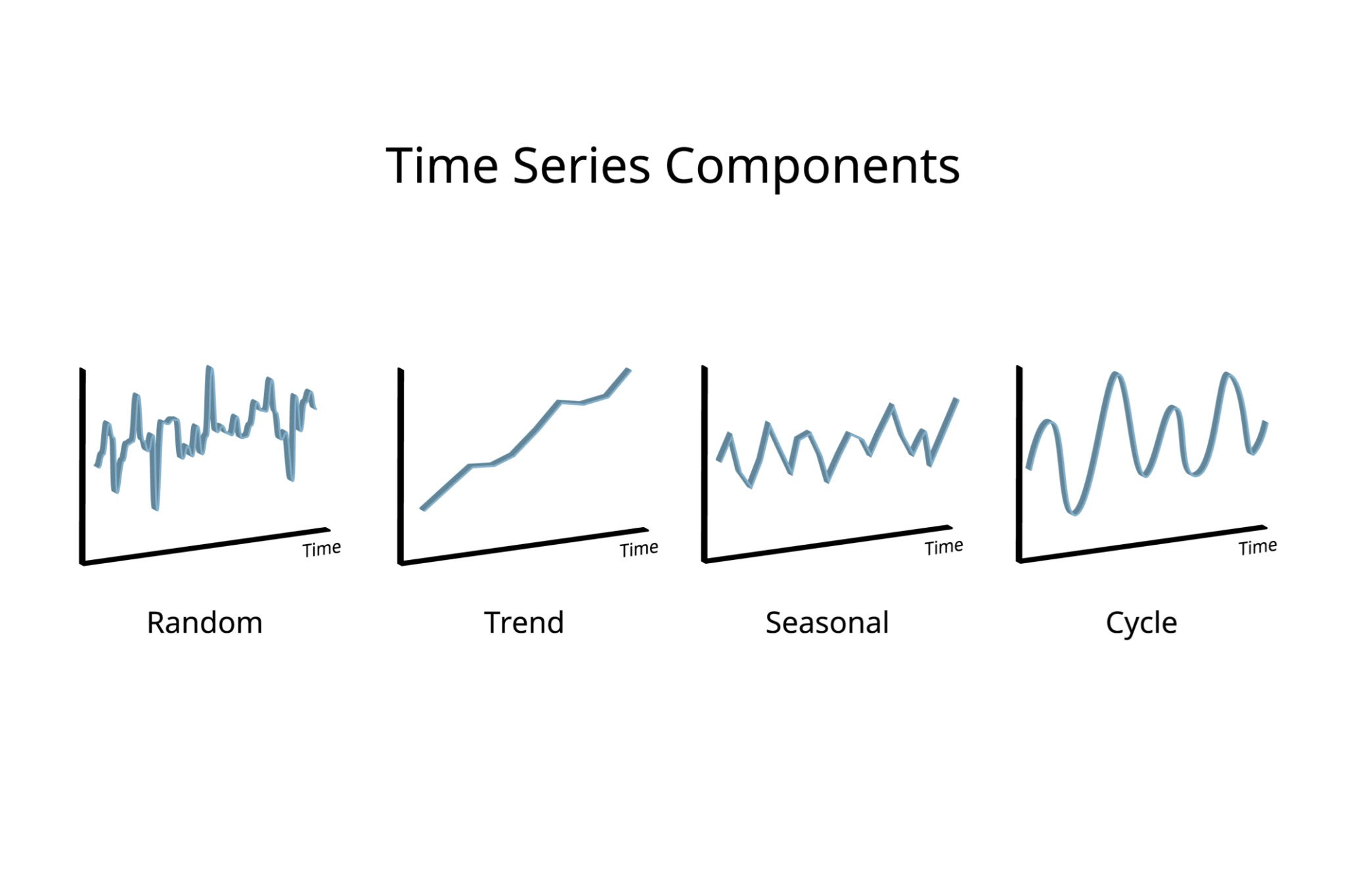
시계열의 구성 요소
- 추세 요인 (Trend): 데이터가 장기적으로 증가하거나 감소하는 전반적인 방향성.
- 계절 요인 (Seasonal): 1년, 1분기, 1주일 등 고정된 빈도로 발생하는 반복적인 패턴.
- 순환 요인 (Cycle): 고정된 빈도가 아닌, 장기적인 주기로 발생하는 증가 및 감소 형태 (예: 경기 변동).
- 불규칙 요인 (Irregular/Random): 위의 세 가지 요인으로 설명되지 않는 무작위적인 오차 변동.
| 1 Depth (분석 목적 및 데이터 형태) | 2 Depth (접근 방식 및 모델링 기법) | 3 Depth (최하단: 구체적 분석 알고리즘) |
|---|---|---|
| 1. 연속형 지표 예측 (Time Series Forecasting) 연속적 수치(매출, DAU 등)의 미래 값 예측 | 통계적 모형 (Statistical) | ARIMA, SARIMA, 지수평활법(Holt-Winters), VAR |
| 기계학습 & 딥러닝 모형 (ML/DL) | Prophet, LSTM, GRU, TFT | |
| 시계열 분해 (Decomposition) | STL, X-11 | |
| 2. 상태 변화 및 시퀀스 분석 (State/Sequence) 시간 흐름에 따른 상태 변화나 행동 순서 파악 | 상태 전이 확률 모형 | 마르코프 체인 (Markov Chain), 은닉 마르코프 모형 (HMM) |
| 순차 패턴 마이닝 | AprioriAll, PrefixSpan, DTW | |
| 3. 사건 발생 시간 분석 (Survival Analysis) 특정 사건(이탈, 결제 등) 발생까지 걸린 시간 추정 | 비모수적 모형 (Non-parametric) | Kaplan-Meier (KM), Nelson-Aalen (NA), 생명표 (Life Tables) |
| 준모수적 모형 (Semi-parametric) | Cox 비례위험 모형 (Cox PH Model) | |
| 모수적 모형 (Parametric) | 가속 실패 시간 (AFT) 모형 (Weibull, Lognormal 등) |
MA/ES
| 구분 | MA 평활법 (Moving Average Smoothing) | ES 평활법 (Exponential Smoothing) | MA 모형 (Moving Average Model) |
|---|---|---|---|
| 목적 | 데이터 노이즈 제거 및 과거 추세 파악 | 최근 변동에 민감하게 반응하여 노이즈 제거 및 단기 예측 | 오차 구조를 파악하여 데이터의 미래 값 확률적 예측 |
| 선형 결합 대상 | 과거의 실제 관측값 () | 과거의 실제 관측값 () 및 이전 예측값 | 과거의 백색잡음/오차항 () |
| 가중치 부여 방식 | 설정된 윈도우 기간 내 모든 값에 동일한 산술적 가중치 | 최근 관측값일수록 높은 가중치, 과거로 갈수록 지수적 감소 | 데이터로부터 통계적으로 추정된 파라미터() 가중치 |
| 접근 방식 | 기술적(Descriptive) 분석, 단순 데이터 필터링 | 기술적 분석, 최신 트렌드 반영 필터링 | 확률적(Stochastic) 데이터 생성 과정 추정 |
| 정상성(Stationarity) | 불필요 | 불필요 (추세/계절성이 있어도 Holt-Winters로 확장 적용 가능) | 필수 (오차항의 평균과 분산이 일정해야 함) |
| 분류 | 기반 기법 | 주요 모델 및 알고리즘 | 특징 |
|---|---|---|---|
| MA 기반 모델 | 이동평균 | MA 모형, ARMA, ARIMA, SARIMA (내부의 MA(q) 프로세스) | 과거의 예측 오차(Error Term, 백색잡음)들의 선형 결합으로 현재 값을 예측한다. 데이터의 정상성(Stationarity) 만족이 필수적이다. |
| ES 기반 모델 | 지수평활 | 단순 지수평활(SES), Holt 선형 모델(이중 지수평활), Holt-Winters 모델(삼중 지수평활) | 수준(Level), 추세(Trend), 계절성(Seasonality)에 각각 평활 방정식을 적용하여 예측한다. 비정상 시계열에도 바로 적용 가능하다. |
from statsmodels.tsa.holtwinters import SimpleExpSmoothing
from statsmodels.tsa.arima.model import ARIMA
# 가. 단순 이동평균 (Window=5), min_periods=1을 주면 초기 결측치 발생을 방지함
ma_smoothed = df['realgdp'].rolling(window=5).mean()
ma_smoothed = df['realgdp'].rolling(window=5, min_periods=1).mean()
ma_grouped_ma = df.groupby('year')['realgdp'].transform(
lambda x: x.rolling(window=3, min_periods=1).mean()
)
# 나. 단순 지수평활 (alpha=0.2)
# adjust=False는 전통적인 S_t = a*y_t + (1-a)*S_{t-1} 공식을 사용하기 위함
usealpha=0.2
# 아래는 모두 동일한 결과를 반환
es_smoothed = df['realgdp'].ewm(alpha=usealpha, adjust=False).mean()
es_smoothed = df['realgdp'].ewm(span=(2/usealpha)-1, adjust=False).mean()
es_smoothed = df['realgdp'].ewm(com=(1/usealpha)-1, adjust=False).mean() # 질량중심
es_smoothed = df['realgdp'].ewm(halflife=(np.log(2)/np.log(1-usealpha)), adjust=False).mean()
# ==========================================
# 3. Statsmodels를 활용한 예측 모델링
# ==========================================
# 가. MA 기반 예측 모델 (ARIMA에서 AR(p)=0, 차분 d=0, MA(q)=2 인 MA(2) 모델)
# 과거 2 시점의 오차(Error)를 기반으로 예측
ma_model = ARIMA(df['realgdp'], order=(0, 0, 2))
ma_model_fit = ma_model.fit()
ma_forecast = ma_model_fit.predict(start=0, end=len(df['realgdp'])-1)
# 나. ES 기반 예측 모델 (Simple Exponential Smoothing)
# alpha 값을 모델이 최적화하여 찾아줌 (smoothing_level)
es_model = SimpleExpSmoothing(df['realgdp'], initialization_method="estimated")
es_model_fit = es_model.fit()
es_forecast = es_model_fit.fittedvalues
print(ma_model_fit.summary())기초
-
시계열 분해 / EDA 진행
- STL 분해 = 추세, 계절성, 잔차 분리
-
station 확인
- KPSS, ADF 사용
- 정상성을 만족하지 않는다면 조치
- 분산이 일정하지 않다면 box-cox, log변환 (먼저)
- 차분 후에는 음수가 생길 수 있어 분산 안정화 기법을 적용할 수 없음
- 평균이 일정하지 않다면 차분, 로그차분
- 분산이 일정하지 않다면 box-cox, log변환 (먼저)
-
모형 선정
- 기본 ARIMA
- 계절성이 있다면 SARIMA
-
모형 fit
- ACF/PACF 상황에 따라 모형 detail 선정
- ACF가 절단이면 MA
- PACF가 절단이면 AR
- AutoARIMA 등의 알고리즘 사용
- ACF/PACF 상황에 따라 모형 detail 선정
-
생성된 모형 타당성 검정
- Ljung-Box 검정
| 비교 항목 | pd.DataFrame.diff | statsmodels.tsa.statespace.tools.diff |
|---|---|---|
| 설계 목적 | 범용적인 행 간 차이 계산 | ARIMA/SARIMA 모델링을 위한 전처리 |
결측치(NaN) 처리 | 발생한 NaN을 보존함 | 발생한 NaN을 자동 제거(Drop)함 |
| 반환 데이터 길이 | 원본 데이터 길이와 동일함 | 차분 횟수 및 주기에 비례하여 짧아짐 |
| 복합 계절 차분 | 지원하지 않음 (다중 호출 필요) | 단일 파라미터 입력으로 즉시 지원 |
데이터에 추세와 계절성이 동시에 존재할 경우, 일반 차분과 계절 차분을 복합적으로 수행해야 한다. 계절 주기 에 대한 계절 차분 수식은 아래와 같다.
-
pd.DataFrame.diff(): 일반 차분과 계절 차분을 동시에 수행하는 기능이 없다. 두 가지를 모두 적용하려면df.diff(1).diff(12)와 같이 메서드 체이닝(Chaining)을 수동으로 구성해야 한다. -
statsmodels.tsa.statespace.tools.diff:k_diff(일반 차분 횟수),k_seasonal_diff(계절 차분 횟수),seasonal_periods(계절성 주기 m) 파라미터를 명시적으로 제공한다. 단 한 번의 함수 호출로 일반 차분과 계절 차분을 결합하여 연산할 수 있다.
시계열 분해 (STL)
- 복잡하게 얽혀 있는 시계열 신호(Signal)를 통계적으로 해석 가능한 개별 성분(추세, 계절성, 잔차)으로 분리
- 데이터의 기저 메커니즘을 파악하고 분석 및 예측 모델의 성능을 극대화
원데이터를 추세(Trend), 계절성(Seasonality), 불규칙/잔차(Irregular/Residual) 성분으로 분리
데이터의 구조적 특성을 직관적으로 파악 (정상성 등)
- 추세: 데이터의 이동평균 또는 경향성, 장기간에 걸쳐서 나타남
- 계절성: 데이터에의 반복적, 규칙적 변동
- 순환변동 (Cyclical Component): 장기간에 걸친 경제적 / 기타 사이클로 인한 변동 (계절성보다 긴 기간에 걸쳐 발생)
- 잔차: 불규칙한 변동, 노이즈 (모델로 설명되지 않음)
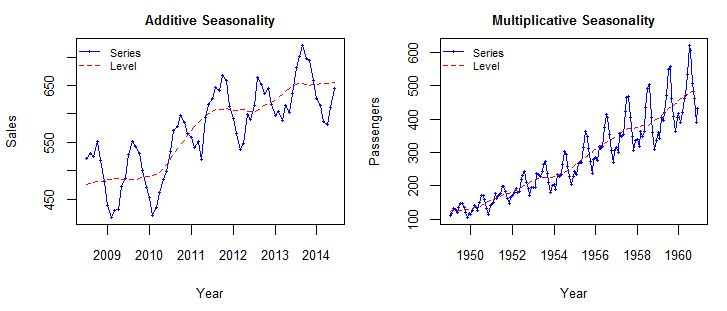
| 비교 항목 | 가법 모형 (Additive) | 승법 모형 (Multiplicative) |
|---|---|---|
| 수식 구조 | ||
| 계절성 진폭 | 추세 변화와 무관하게 일정함 | 추세의 수준에 비례하여 증감함 |
| 잔차 분산 | 시간에 따라 일정함 (동분산성 가정에 가까움) | 시간에 따라 변동함 (이분산성 띰) |
| 적합한 데이터 | 온도 등 자연과학 데이터, 증가 폭이 일정한 데이터 | 매출, 여객 수 등 경제/비즈니스 지수 데이터 |
| STL 적용 방법 | 원본 데이터에 바로 적용 | 로그 변환(np.log) 후 STL 적용 |
| 비교 항목 | Classical (고전적 분해) | X-11 | SEATS | STL |
|---|---|---|---|---|
| 최초 등장 시점 | 1920년대 | 1965년 | 1990년대 초 | 1990년 |
| 기반 알고리즘 | 단순 이동평균 (MA) | 반복적 MA 및 Henderson 필터 | ARIMA 모형 기반 신호 추출 | 국소 회귀 (LOESS) 반복 연산 |
| 계절성 가정 | 시간에 따라 불변 (고정) | 시간에 따른 서서히 변화 허용 | ARIMA 기반 확률적 변화 | 하이퍼파라미터 조절로 동적 변화 허용 (윈도우 조절) |
| 이상치 강건성 | 취약함 | 강건함 (이상치 가중치 조절) | 매우 강건함 (내부 이상치 탐지) | 매우 강건함 (robust=True 옵션) |
| 양끝단/결측치 처리 | 양 끝단 데이터 손실 (NaN 발생) | 양 끝단 추정 가능(ARIMA 연장 활용) | ARIMA 예측 사용, 양 끝단 완벽 추정 | 양 끝단 모두 추정 (NaN 없음) |
| 가법/승법 지원 | 가법, 승법 모두 지원 | 가법, 승법, 유사-가법 지원 | 가법, 승법 지원 | 가법 모형만 지원 (승법은 log 변환 필요) |
| Full Module Path | statsmodels.tsa.seasonal | statsmodels.tsa.x13 | statsmodels.tsa.x13 | statsmodels.tsa.seasonal |
| Class / Method | seasonal_decompose | x13_arima_analysis | x13_arima_analysis | STL |
| 비고 | .dropna(), .bfill(), .ffill() | 외부 바이너리 필요 | 외부 바이너리 필요 |
- MA 는 Moving Average
- 신호 추출 (Signal Extraction)
period=7일 때, 특정 시점 t의 추세 는 해당 시점을 중심으로 앞뒤 3개씩, 총 7개의 데이터를 평균낸다.
이때 head 3개, tail 3개는 각각 과거/미래 데이터가 3개 미만이라 평균을 구할 수 없다. 따라서 이 구간들이 NaN으로 처리된다.
고전적 시계열 분해 알고리즘에서 주기가 짝수일 때는 중심을 맞추기 위해 단순 이동평균이 아닌 2×p 중심 이동평균 (Centered MA of order 2×p) 을 사용한다.
따라서 period=6 일 경우에도 앞뒤 3개씩 유실된다.
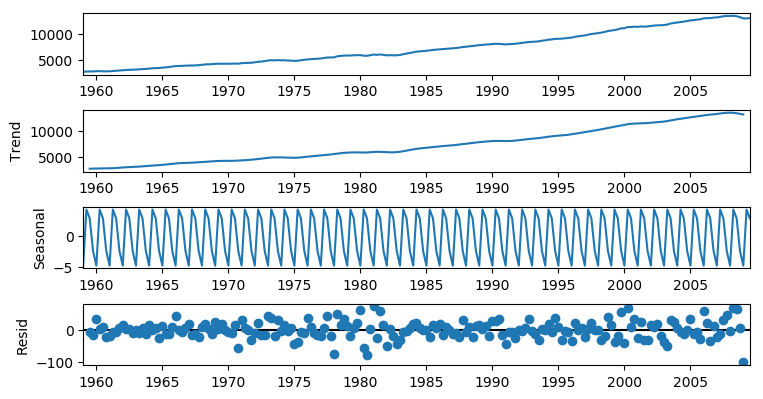
# 시계열 분해
series = df[['date', 'realgdp']].set_index('date')
# model='additive' 구성요소들이 덧셈으로 연결됨을 가정
# model='multiplicative' 구성요소들이 곱셈으로 연결됨을 가정
# period=4 는 주기를 4로 하는 데이터임을 의미
# df는 분기별 데이터이므로 4분기를 주기로 계절성 패턴이 반복된다고 가정했기 때문
result = sm.tsa.seasonal_decompose(series, model='additive', period=4)
result = sm.tsa.seasonal_decompose(series, model='multiplicative', period=4)
display(pd.DataFrame([result.trend, result.seasonal, result.resid, result.observed]
, index=['추세', '계절성', '잔차', '원본 시계열 데이터']).T.head(3))
if 'STL 분해':
from statsmodels.tsa.seasonal import STL
result = STL(df3_solve1).fit()
result.plot()
if '분해 결과 시각화':
# fig = plt.figure(figsize = (10, 3))
fig = result.plot() # 원본데이터, 추세, 계절, 잔차에 대한 정보
# result.plot(ax=axes[0])
fig.set_size_inches(8, 4) # 여기서 크기 조절 (가로, 세로)
plt.tight_layout()
plt.show()
| 추세 | 계절성 | 잔차 | 원본 시계열 데이터 | |
|---|---|---|---|---|
| date | ||||
| 1959-01-01 | NaN | -4.706352 | NaN | 2710.349 |
| 1959-04-01 | NaN | 4.237946 | NaN | 2778.801 |
| 1959-07-01 | 2779.62925 | 2.828948 | -6.970198 | 2775.488 |
series = df[['date', 'realgdp']].set_index('date')
# model='additive' 구성요소들이 덧셈으로 연결됨을 가정
# model='multiplicative' 구성요소들이 곱셈으로 연결됨을 가정
# period=4 는 주기를 4로 하는 데이터임을 의미
# df는 분기별 데이터이므로 4분기를 주기로 계절성 패턴이 반복된다고 가정했기 때문
result = sm.tsa.seasonal_decompose(series, model='additive', period=4)
result = sm.tsa.seasonal_decompose(series, model='multiplicative', period=4)
display(pd.DataFrame([result.trend, result.seasonal, result.resid, result.observed]
, index=['추세', '계절성', '잔차', '원본 시계열 데이터']).T.head(3))
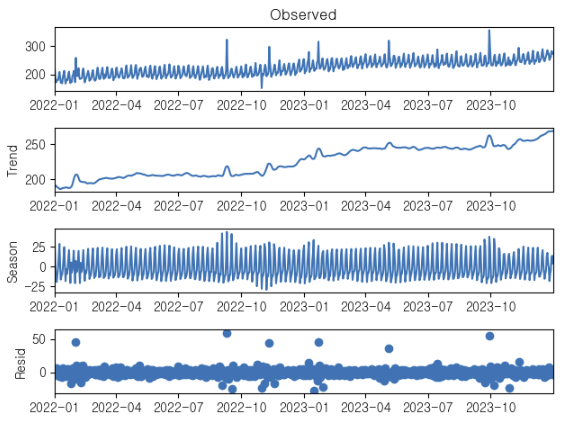
| col1 | 설명 |
|---|---|
| Observed (관측 데이터) | 전반적으로 우상향하는 장기 추세와 매우 촘촘하고 규칙적인 단기 변동(계절성)이 결합된 형태다. 평균과 분산이 시간에 따라 변하므로 정상성(Stationarity)을 만족하지 않는 전형적인 비정상(Non-stationary) 시계열이다. 또한 간헐적으로 튀는 극단값들이 존재한다. |
| Trend (추세 요인) | 2022년 1월부터 2023년 말까지 전체적으로 꾸준히 상승하는 선형 및 부분적 비선형 증가 추세가 확인된다. 전통적인 통계 모델(예: ARIMA)을 구축하기 위해서는 평균의 정상화를 위해 데이터에 1차 차분(Regular Differencing)을 적용해야 한다. |
| Season (계절성 요인) | 짧은 주기로 매우 일정한 진폭의 패턴이 반복되고 있다. 시간 흐름이나 추세의 상승과 무관하게 계절성의 진폭이 비교적 일정하므로, 승법 모형(Multiplicative)보다는 가법 모형(Additive) 가정하에 분해된 것이 타당하다. 예측 모델링을 수행할 경우, 통계적 접근으로는 계절성 차분(Seasonal Differencing)이 포함된 SARIMA 모델이 적합하다. 머신러닝 접근(Random Forest, XGBoost 등) 시에는 날짜 기반의 파생 변수(예: 요일, 주차, 월 등)를 반드시 피처로 추가하여 모델이 이 주기성을 학습하도록 해야 한다. |
| Resid, remainder (불규칙/잔차 요인) | 이상적인 모델 분해 후의 잔차는 평균 0, 일정한 분산을 가지는 백색 잡음(White Noise) 형태여야 한다. 그래프의 잔차는 대체로 0 부근에 분포하고 있으나, 2022년 말과 2023년 상/하반기에 정규분포 가정을 심하게 벗어나는 양/음의 이상치(Outliers)가 명확하게 존재한다. 이는 추세와 계절성만으로는 설명되지 않는 외부 충격(Event, 프로모션, 시스템 오류 등)이 작용했음을 의미한다. ADP 실기 관점에서는, 예측 성능 저하를 막기 위해 잔차 검정(Ljung-Box test 등)을 수행하고 이 이상치들을 제거 및 보간(Interpolation)하거나, 지시 변수(Dummy Variable)를 활용한 개입 분석(Intervention Analysis)을 수행하는 것이 필수적이다. |
해당 분해는 시계열의 가법 모형을 바탕으로 이루어졌으며 기본 수식은 다음과 같다.
일반적으로 종속변수에 자연로그(Natural Logarithm)를 취해 승법 모형을 가법 모형의 형태로 변환한 뒤 STL 분해를 수행해.
정상성 체크 (station) / 검정
시계열 데이터의 동계적 특성이 시간에 따라 일정하게 유지되는 성질
- 모든 시간 t에 평균이 상수다.
- 모든 시간 t에 분산이 상수다.
- 모든 시간 t와 시차 k 에 대해, 공분산은 k에만 의존하고 t에는 의존하지 않는다.
위의 조건을 만족하면 정상성을 가진다.
| 모형 / 데이터 상태 | 적용 상황 (통계학적/머신러닝 관점) | ACF 패턴 | PACF 패턴 |
|---|---|---|---|
| AR(p) (자기회귀) | 현재 값이 과거 시점까지의 자신의 과거 관측치에 직접적으로 의존할 때. 모멘텀이나 회귀 성향이 강한 데이터에 적합. | 지수적으로 점차 감소 (Tails off) 하거나 사인 함수 형태로 감쇠 | 시차 이후 절단 (Cuts off, 0으로 수렴) |
| MA(q) (이동평균) | 현재 값이 과거 시점까지의 **백색잡음(외부 충격)**들의 선형 결합으로 설명될 때. 충격이 일정 기간() 동안만 영향을 미칠 때 적합. | 시차 이후 절단 (Cuts off, 0으로 수렴) | 지수적으로 점차 감소 (Tails off) 하거나 사인 함수 형태로 감쇠 |
| ARMA(p, q) | 현재 값이 자신의 과거 관측치와 과거의 오차 양쪽 모두에 영향을 받을 때. AR이나 MA 단일 모형만으로 잔차의 백색잡음 특성을 확보하기 어려울 때 적용. | 지수적으로 점차 감소 (Tails off) | 지수적으로 점차 감소 (Tails off) |
| 백색잡음 (White Noise) | 데이터 간 자기상관성이 전혀 없는 순수 무작위 상태. 시계열 모형화할 패턴이 없으므로 예측 모델(AR/MA)을 적용할 필요 없음. (모형 적합 후 잔차가 이 상태가 되어야 함) | 시차 0(자기 자신) 제외하고 모든 시차에서 즉시 절단 (0에 수렴) | 시차 0 제외하고 모든 시차에서 즉시 절단 (0에 수렴) |
| 비정상 시계열 (Non-stationary) | 데이터에 강한 추세가 존재하거나 랜덤워크(Random Walk) 특성을 띠는 상태. 이 상태로는 AR/MA/ARMA 적용이 불가능하므로, **차분(Differencing)**을 거쳐야 함(ARIMA 적용의 근거). | 선형적으로 매우 느리게 감소 | 시차 1에서 1에 매우 가까운 큰 값을 가지고 이후 급격히 감소 |
- 추세나 계절적 요인이 관찰되면 차분(differencing)을 통해 정상적 시계열로 반환
- 변동폭이 일정하지 않으면 함수변환(ex. 로그 변환)을 통하여 분산 안정화
- 분해법으로 추세 및 계절성 제거
아래 검정 둘은 체크하는 대상은 동일하지만, 검정방향이 정반대
- Augmented Dickey-Fuller (ADF) 검정
- 단위근 존재 여부를 체크한다.
- 단위근이 존재한다면 비정상 시계열이다.
- 단위근이 존재한다 = 과거의 충격이 사라지지 않고 미래에 계속 영향을 주고 있다.
- Kwiatkowski-Phillips-Schmidt-Shin (KPSS) 검정
- 정상성 여부를 체크한다.
| 비교 항목 | ADF 검정 (Augmented Dickey-Fuller, 단위근 검정) | KPSS 검정 (Kwiatkowski-Phillips-Schmidt-Shin, 정상성 검정) |
|---|---|---|
| 귀무가설 () | 데이터에 단위근이 존재한다. (비정상 시계열) | 데이터가 정상성을 만족한다. (정상 시계열) |
| 대립가설 () | 데이터가 정상성을 만족한다. (정상 시계열) | 데이터에 단위근이 존재한다. (비정상 시계열) |
| 검정 목적 | 확률적 추세 (단위근) 존재 여부 확인 | 결정론적 추세 주변의 정상성 여부 확인 |
| p-value < 0.05 해석 | 정상 시계열로 판단 (귀무가설 기각) | 비정상 시계열로 판단 (귀무가설 기각) |
| p-value > 0.05 해석 | 비정상 시계열로 판단 (귀무가설 채택) | 정상 시계열로 판단 (귀무가설 채택) |
| 파이썬 라이브러리 | statsmodels.tsa.stattools.adfuller | statsmodels.tsa.stattools.kpss |
| KPSS Stationary () | KPSS Non-stationary () | |
|---|---|---|
| ADF 정상 () | 엄격한 정상 시계열 (Strict) > 상태: 엄격한 정상성 > 조치: 변환 불필요. 즉시 모델 적합 진행 | 구조적 변화/분산 불안정 (Structural Break) > 상태: 구조적 변화 또는 분산 불안정 > 조치: 구조적 변화 탐지 또는 로그 변환 (분산 안정화) 후 차분 |
| ADF 비정상 () | 추세 정상 시계열 (Trend) > 상태: 추세 정상성 > 조치: 결정론적 추세 제거 진행 (Detrending) | 차분 정상 시계열 (Difference) > 상태: 단위근 존재 (차분 정상성) > 조치: 1차 또는 2차 차분 진행 (Differencing) |
# 정상성 검정
result = sm.tsa.adfuller(df['realgdp'])
result[0] # ADF Statistic
result[1] # p-value
result[2] # n of Lags Used
result[3] # Number of Observations Used
result[4] # Critical Values
result[5] # IC Best
if result[1] < 0.05:
print('H_0 기각, 정상 - 정상 시계열 여부')
else:
print('H_0 채택, 비정상 - 정상 시계열 여부')| 0 | |
|---|---|
| ADF Statistic | 1.75046 |
| p-value | 0.998246 |
| #Lags Used | 12 |
| Number of Observations Used | 190 |
| Critical Values | {'1%': -3.4652439354133255, '5%': -2.876875228... |
| IC Best | 2034.52 |
| 정상성 여부 | H_0 채택, 비정상 - 정상 시계열 여부 |
ACF-PACF 확인, 모형선정
- Autocorrelation Function 자기상관함수 : 정상시계열이면 빠르게 0 으로 수렴해야함
- Partial Autocorrelation Function : 부분자기 상관함수
그래프 그렸을 때 파란 영역 (신뢰구간, 95%) 내에 들어오는 x축의 값을 차수로 차용
| 항목 | ACF (자기상관함수) | PACF (편자기상관함수) |
|---|---|---|
| 통계적 의미 | 시점 와 간의 중간 관측치 영향을 모두 포함한 전체적인 선형 상관관계 | 시점 와 사이의 중간 관측치 영향을 통제(제거)한 순수한 조건부 선형 상관관계 |
| 수학적 수식 | ||
| 시계열 모형 식별 | MA(q) 모형의 차수 판별 (절단점 확인) | AR(p) 모형의 차수 판별 (절단점 확인) |
| 측정 대상 | 두 시점 간의 전체 상관관계 (직간접 영향 모두 포함) | 두 시점 간의 순수 상관관계 (중간 시점 영향 제거) |
| 수학적 도출 방식 | 자기공분산 / 자기분산 | 조건부 상관계수 (또는 AR 모형의 마지막 회귀계수) |
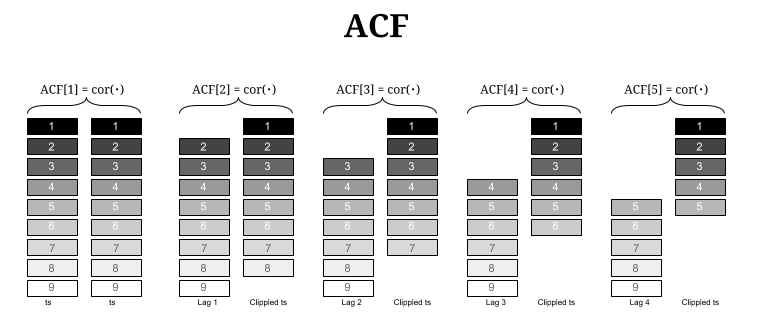
- ACF (자기상관함수)
특정 시점 t의 관측치 와 시차 k만큼 떨어진 과거 관측치 간의 전체적인 선형 상관관계를 측정한다. 여기서 ‘전체적인’이라는 뜻은, t와 t−k 사이에 존재하는 다른 관측치들 ()이 미치는 간접적인 영향까지 모두 포함하여 결합된 상관성을 보여준다는 것을 의미한다. 시계열 데이터의 전반적인 기억(Memory) 현상을 파악하고, 주로 MA(q) 모형의 차수를 판별할 때 사용된다.
모집단의 자기상관계수 는 시차 k의 자기공분산을 자기 자신의 분산(시차 0의 자기공분산)으로 나눈 값이다. 실제 데이터에서 구하는 표본 자기상관계수 (시계열 길이가 T일 때)의 수식은 다음과 같다.
- PACF (편자기상관함수)
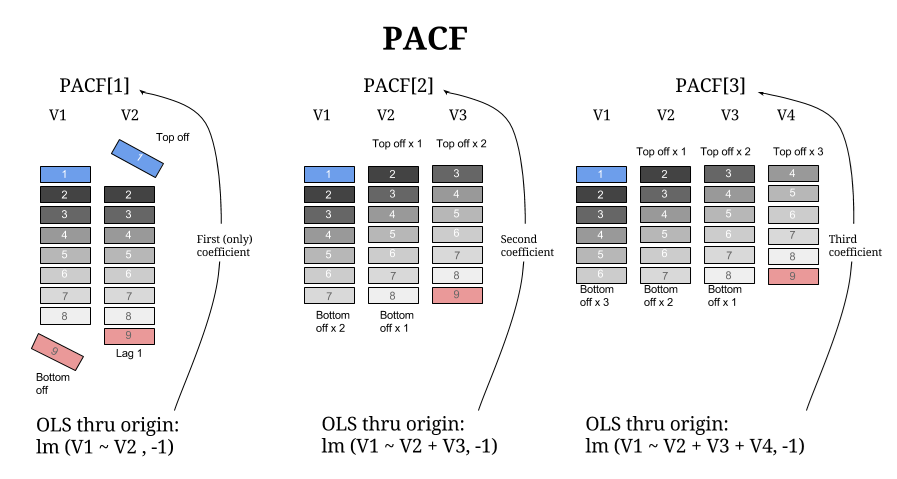
특정 시점 t의 관측치와 시차 k만큼 떨어진 과거 관측치 간의 ‘순수한’ 선형 상관관계를 측정한다. 즉, 두 시점 사이에 존재하는 중간 관측치들()이 미치는 선형적인 영향을 수학적으로 완전히 회귀시켜 통제(제거)한 상태에서의 조건부 상관계수다. 이를 통해 과거의 특정 시점 데이터가 현재에 미치는 직접적인(Direct) 영향력만을 분리해낼 수 있으며, 주로 AR(p) 모형의 차수를 판별할 때 필수적이다.
시차 k에서의 PACF 값, 즉 편자기상관계수 는 k차 자기회귀(AR) 모형을 적합했을 때 마지막 시차 k에 해당하는 회귀계수로 정의된다.
위의 다중 회귀 모형(또는 Yule-Walker 방정식을 통한 추정)에서 산출된 마지막 계수 가 시차 k의 PACF 값이다. 이를 조건부 상관계수 형태의 수식으로 표현하면 다음과 같다.
from statsmodels.tsa.stattools import acf, pacf
# 결측치가 존재할 경우 ACF/PACF 연산이 불가하므로 제거 필수
# 차분(Differencing)을 통해 정상성 확보 후 분석하는 것이 원칙이다.
# 이는 1차 차분
realgdp_diff = df['realgdp'].diff().dropna()
# 이는 2차 차분
realgdp_diff2 = realgdp_diff.diff().dropna()
# …
# 2. 통계량(수치) 직접 추출
# nlags: 계산할 최대 시차 지정
# 기본적으로 'unbiased' 방법이 사용되며, 시차가 커질수록 표본 수가 줄어들어 편향이 발생할 수 있음
acf_values = acf(ts_data, nlags=20) # 이러면 21개가 나온다. 20개가 아니다.
# fft: Fast Fourier Transform을 사용하여 계산 속도 향상
acf_values = acf(ts_data, nlags=20, fft=True)
pacf_values = pacf(ts_data, nlags=20, method='ywm') # ywm: Yule-Walker 방정식 사용
print("ACF Values (Lag 0~5):", acf_values[:6])
print("PACF Values (Lag 0~5):", pacf_values[:6])단, 통계학적 및 머신러닝 관점에서 주의할 점이 있다.
누적합(cum_cases) 변수에 직접 ACF를 적용하는 것은 모델링 측면에서 유효한 정보를 제공하지 않는다.
누적합 데이터는 강한 양의 추세(Trend)를 가지는 전형적인 비정상(Non-stationary) 시계열이므로, ACF 값은 1에 가깝게 시작하여 시차(Lag)가 길어져도 매우 서서히 감소하는 형태만을 띠게 된다.
시계열 모델의 파라미터(AR, MA 차수)를 식별하려면 정상성이 확보된 원본 데이터인 new_cases (즉, cum_cases의 1차 차분 데이터)에 ACF를 적용하는 것이 원칙이다.
# 정상성 검정
import statsmodels.api as sm
import statsmodels.tsa.api as tsa
# acf와 pacf의 값을 원본데이터와 1차 차분 결과로 구분해서 확인
series = df['realgdp']
plt.close('all')
fig, ax = plt.subplots(2,2,figsize=(10,4))
if True:
tsa.graphics.plot_acf(series,ax= ax[0,0])
tsa.graphics.plot_pacf(series,ax= ax[0,1])
fig.tight_layout()
plt.show()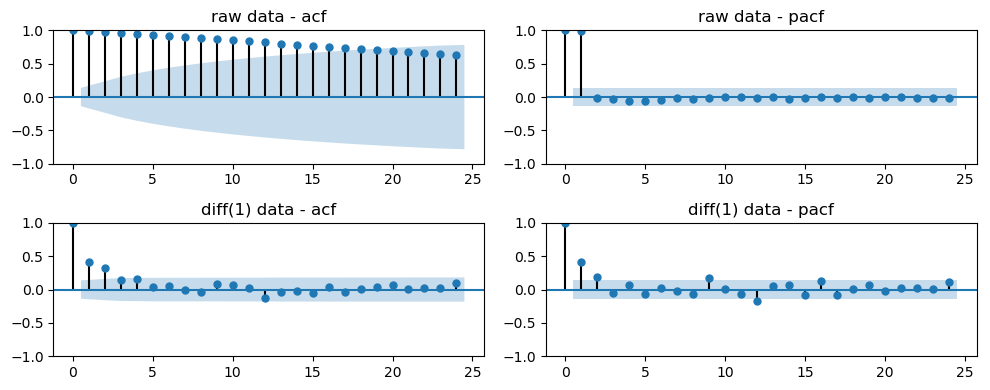
선정되는 모형 - ARIMA, SARIMA 및 fit
슬라이딩 윈도우 기법은 시계열 데이터의 국소적(local) 특성을 파악하고 노이즈를 제어하기 위해 다양한 분석 및 모델링 개념의 핵심 원리로 사용된다. 주요 연관 개념은 다음과 같다.
- 이동 평균 (Moving Average) 일정 크기의 윈도우 내 데이터 평균을 연속적으로 계산하는 기법이다. 단기적인 무작위 변동(노이즈)을 평활화(Smoothing)하여 시계열 데이터의 장기적인 추세(Trend)를 시각적으로 파악하거나 모델링하는 데 사용된다.
종류: 단순 이동 평균(SMA), 지수 이동 평균(EMA), 가중 이동 평균(WMA).
# 만약 데이터 중간에 이빨이 빠진(결측) 구간이 있다면 asfreq를 사용하여 빈 공간을 채워야 함
# 모델 적합을 수행하기 전에 인덱스 주기 명시적 할당
series = df[['date', 'realgdp']].set_index('date')
# series = series.asfreq('QS-OCT')
series.index.freq = 'QS-OCT'
# 비계절성 패러미터. ARIMA / SARIMA 모델의 차수 설정
# 실제 데이터에 따라 p, d, q 값을 조정한다.
# p-plot_acf로 확인, q-plot_pacf, d-차분 그래프
p, d, q = 2, 1, 2
if 'ARIMA':
model = tsa.arima.ARIMA(series, order=(p, d, q))
model_fit = model.fit()
if 'SARIMA':
# 계절성 패러미터. SARIMA 모델의 계절성 설정
# P, D, Q는 계절성 자기회귀, 계절성 차분, 계절성 이동평균 요소의 차수를 나타내며,
# S는 계절 주기를 나타냅니다.
# S는 몇개월 주기의 데이터인지 확인 후 해당 개월수를 넣는다.
P, D, Q, S = 1, 1, 1, 12
model = tsa.statespace.SARIMAX(series, order=(p, d, q), seasonal_order=(P, D, Q, S))
model_fit = model.fit(disp=False)
# 모델 요약 정보 출력
display(model_fit.summary()[0])
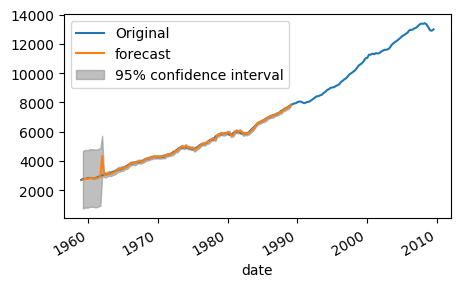
# 예측 결과 시각화
plt.figure(figsize=(5, 3))
if True:
plt.plot(series, label='Original')
tsa.graphics.plot_predict(
model_fit, start=1, end=120, dynamic=False, plot_insample=False, ax=plt.gca()
)
plt.legend()
plt.show()
# 미래 값 예측
forecast = model_fit.forecast(steps=100) # 다음 100개 데이터 포인트 예측
| Dep. Variable: | realgdp | No. Observations: | 203 |
|---|---|---|---|
| Model: | SARIMAX(2, 1, 2)x(1, 1, [1], 12) | Log Likelihood | -1043.165 |
| Date: | Sat, 28 Mar 2026 | AIC | 2100.331 |
| Time: | 23:40:18 | BIC | 2123.060 |
| Sample: | 01-01-1959 | HQIC | 2109.538 |
| - 07-01-2009 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.L1 | 1.6459 | 0.297 | 5.544 | 0.000 | 1.064 | 2.228 |
| ar.L2 | -0.6504 | 0.267 | -2.434 | 0.015 | -1.174 | -0.127 |
| ma.L1 | -1.2852 | 0.296 | -4.343 | 0.000 | -1.865 | -0.705 |
| ma.L2 | 0.3103 | 0.217 | 1.430 | 0.153 | -0.115 | 0.736 |
| ar.S.L12 | -0.2061 | 0.079 | -2.608 | 0.009 | -0.361 | -0.051 |
| ma.S.L12 | -0.9896 | 0.628 | -1.576 | 0.115 | -2.220 | 0.241 |
| sigma2 | 2849.1254 | 1672.654 | 1.703 | 0.089 | -429.217 | 6127.468 |
| Ljung-Box (L1) (Q): | 0.13 | Jarque-Bera (JB): | 12.16 |
|---|---|---|---|
| Prob(Q): | 0.72 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 2.87 | Skew: | -0.23 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 4.15 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
통계학 및 시계열 분석(특히 Python의 statsmodels 라이브러리를 활용하는 ADP 실기 환경)에서 predict와 forecast는 적용 대상과 목적에 따라 엄격하게 구분된다.
두 용어의 핵심적인 차이는 예측을 수행하는 대상 데이터가 학습 데이터 구간 내부(In-sample)인지, 외부(Out-of-sample)인지에 있다.
-
Predict (추정, 예측)
-
Forecast (전망, 미래 예측)
series = df[['date', 'realgdp']].set_index('date')
series.index.freq = 'QS-OCT'
import pmdarima as pm
# from pmdarima import auto_arima
from statsmodels.datasets import macrodata
y = df['realgdp']
# # 수정 1: 시계열 인덱스가 포함된 데이터를 y로 지정
# y = series['realgdp']
'''
# auto_arima 실행 (최적의 p, d, q를 자동으로 탐색)
if 'ARIMA':
# ARIMA 최적화 실행
model_arima = pm.auto_arima(
# y=data,
y=y,
low_order_only=False, # 고차원 모델 허용 여부
seasonal=False, # 계절성 비활성화
stepwise=True, # Stepwise 알고리즘 사용 (속도 향상)
trace=True, # 최적화 과정 출력
error_action='ignore',
suppress_warnings=True
)
# 3. 최적의 모델 요약 정보 출력
print(model_arima.summary())
'''
if 'SARIMA':
# SARIMA 최적화 실행
model_sarima = pm.auto_arima(
# y=data,
y=y,
seasonal=True, # 계절성 활성화, 계절성 ARIMA(SARIMA) 고려
# 계절 주기 (예: 월간 데이터면 12, 주간이면 52, 분기별 데이터이므로 계절성 주기 4 설정)
m=4,
start_P=0, max_P=2, # 계절성 AR 차원 탐색 범위
start_Q=0, max_Q=2, # 계절성 MA 차원 탐색 범위
D=None, # 계절성 차분 (None 설정 시 자동 결정)
# trace=True, # 진행 과정 출력
trace=True, # 진행 과정 출력
error_action='ignore',
suppress_warnings=True
)
# 3. 최적의 모델 요약 정보 출력
display(model_sarima.summary())
# p, d, q = model.order
# P, D, Q, m = model.seasonal_order
# intercept_str = " intercept" if model.with_intercept else ""
# # 3. 요구하는 문자열 형태로 포맷팅하여 출력
# print(f"Best model: ARIMA({p},{d},{q})({P},{D},{Q})[{m}]{intercept_str}")
# 4. 미래 예측 (12분기)
# forecast = model_sarima.forecast(n_periods=12)
forecast = model_sarima.predict(n_periods=12)
print(forecast)
if 'plot':
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(5, 3))
# ax.plot(series, label='Original')
# ax.plot(model_sarima.predict_in_sample(), label='Fitted')
# ax.plot(
# pd.date_range(series.index[-1], periods=24, freq='M')
# , model_sarima.predict(n_periods=24), label='Forecast'
# )
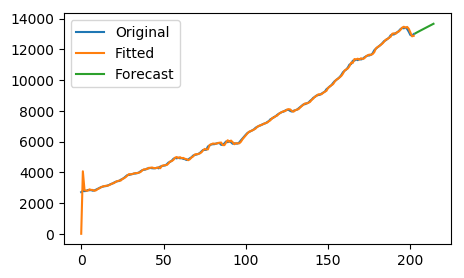
ax.plot(y, label='Original')
ax.plot(model_sarima.predict_in_sample(), label='Fitted')
# 수정 3: 예측 반환값에 올바른 DatetimeIndex가 이미 포함되어 있으므로 그대로 플롯
ax.plot(forecast, label='Forecast')
ax.legend()
plt.show()
Performing stepwise search to minimize aic
ARIMA(2,2,2)(0,0,0)[4] : AIC=2184.227, Time=0.13 sec
ARIMA(0,2,0)(0,0,0)[4] : AIC=2250.987, Time=0.01 sec
ARIMA(1,2,0)(1,0,0)[4] : AIC=2215.282, Time=0.03 sec
ARIMA(0,2,1)(0,0,1)[4] : AIC=2198.402, Time=0.04 sec
ARIMA(2,2,2)(1,0,0)[4] : AIC=2185.706, Time=0.22 sec
ARIMA(2,2,2)(0,0,1)[4] : AIC=2185.471, Time=0.20 sec
ARIMA(2,2,2)(1,0,1)[4] : AIC=2187.017, Time=0.27 sec
ARIMA(1,2,2)(0,0,0)[4] : AIC=2200.302, Time=0.11 sec
ARIMA(2,2,1)(0,0,0)[4] : AIC=2184.005, Time=0.10 sec
ARIMA(2,2,1)(1,0,0)[4] : AIC=inf, Time=0.13 sec
ARIMA(2,2,1)(0,0,1)[4] : AIC=2184.476, Time=0.22 sec
ARIMA(2,2,1)(1,0,1)[4] : AIC=2187.823, Time=0.31 sec
ARIMA(1,2,1)(0,0,0)[4] : AIC=2188.305, Time=0.05 sec
ARIMA(2,2,0)(0,0,0)[4] : AIC=2211.742, Time=0.03 sec
ARIMA(3,2,1)(0,0,0)[4] : AIC=2185.240, Time=0.13 sec
ARIMA(1,2,0)(0,0,0)[4] : AIC=2213.323, Time=0.02 sec
ARIMA(3,2,0)(0,0,0)[4] : AIC=2202.488, Time=0.03 sec
ARIMA(3,2,2)(0,0,0)[4] : AIC=2186.212, Time=0.23 sec
ARIMA(2,2,1)(0,0,0)[4] intercept : AIC=inf, Time=0.11 sec
Best model: ARIMA(2,2,1)(0,0,0)[4]
Total fit time: 2.383 seconds
| Dep. Variable: | y | No. Observations: | 203 |
|---|---|---|---|
| Model: | SARIMAX(2, 2, 1) | Log Likelihood | -1088.002 |
| Date: | Sun, 29 Mar 2026 | AIC | 2184.005 |
| Time: | 18:15:40 | BIC | 2197.218 |
| Sample: | 0 | HQIC | 2189.351 |
| - 203 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.L1 | 0.3288 | 0.053 | 6.147 | 0.000 | 0.224 | 0.434 |
| ar.L2 | 0.1813 | 0.055 | 3.306 | 0.001 | 0.074 | 0.289 |
| ma.L1 | -0.9850 | 0.014 | -70.394 | 0.000 | -1.012 | -0.958 |
| sigma2 | 2908.5733 | 238.498 | 12.195 | 0.000 | 2441.126 | 3376.020 |
| Ljung-Box (L1) (Q): | 0.01 | Jarque-Bera (JB): | 22.16 |
|---|---|---|---|
| Prob(Q): | 0.93 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 2.77 | Skew: | -0.30 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 4.51 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
203 13042.434253
204 13102.891844
205 13159.436310
206 13216.211018
207 13272.351815
208 13328.325948
209 13384.130330
210 13439.848679
211 13495.507960
212 13551.132218
213 13606.734251
214 13662.322625
dtype: float64
생성된 모형 타당성 검정 (Ljung-Box)
| 통계적 가설 | 내용 | p-value 해석 및 실무 적용 |
|---|---|---|
| 귀무가설 () | 특정 시차 까지 잔차들 간에 자기상관이 없다. (잔차는 독립적이며 백색잡음이다) | p-value 0.05: 귀무가설 채택. 모델이 데이터를 잘 설명하였으며 잔차에 남은 패턴이 없음. (모델 적합 통과) |
| 대립가설 () | 특정 시차 까지 잔차들 간에 자기상관이 존재한다. | p-value 0.05: 귀무가설 기각. 잔차에 아직 모델링되지 않은 패턴이 남아있음. (모델 개선, 시차 추가 등 필요) |
-
특정 시차(Lag) h까지의 모든 자기상관계수가 동시에 0인지 검정하는 포트맨토 검정(Portmanteau test)의 일종
- 주로 ARIMA 등의 시계열 모델을 적합시킨 후, 잔차(Residuals)에 패턴(정보)이 남아있는지, 즉 잔차가 완전한 백색잡음(White Noise) 상태인지 확인하는 잔차 진단(Residual Diagnostic) 목적으로 사용
-
용도
- 모델의 적합성을 평가
- 데이터의 자기상관(Autocorrelation) 여부 판단
-
검정 통계량 :
- n : 표본의 크기 (시계열 데이터의 길이)
- h : 검정하고자 하는 최대 시차 (Lag)
- : 시차 k에서의 표본 자기상관계수(Sample Autocorrelation)
이 검정 통계량 는 귀무가설 하에서 자유도가 h인 카이제곱(χ2) 분포를 근사적으로 따른다.
시계열 모델의 잔차를 검정할 경우 자유도는 h−p−q (ARIMA의 p, q 파라미터 수)로 조정된다.
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.stats.diagnostic import acorr_ljungbox
# 1. 임의의 백색잡음(White Noise) 데이터 생성 (실제 시험에서는 모델의 잔차인 model.resid를 사용함)
np.random.seed(42)
residuals = np.random.normal(0, 1, 100)
# 2. Ljung-Box 검정 실행
# lags: 검정할 시차 리스트 또는 최대 시차 정수값
# return_df=True: 결과를 pandas DataFrame 형태로 반환하여 가독성을 높임
lb_test_results = acorr_ljungbox(residuals, lags=[5, 10, 15], return_df=True)
# 3. 결과 출력
print("Ljung-Box Test Results:")
print(lb_test_results)
# 4. 결과 해석 자동화 로직 예시 (Lag 10 기준)
p_val_lag10 = lb_test_results.loc[10, 'lb_pvalue']
if p_val_lag10 >= 0.05:
print(f"\nLag 10에서의 p-value는 {p_val_lag10:.4f}로 0.05 이상이다. 귀무가설을 채택한다.")
print("결론: 잔차에 자기상관성이 존재하지 않으며 백색잡음으로 볼 수 있다.")
else:
print(f"\nLag 10에서의 p-value는 {p_val_lag10:.4f}로 0.05 미만이다. 귀무가설을 기각한다.")
print("결론: 잔차에 자기상관성이 존재하므로 시계열 모델의 개선이 필요하다.")ARCH / GARCH
| 비교 항목 | 일반 시계열 (ARIMA) | ARCH (q) | GARCH (p, q) |
|---|---|---|---|
| 분산에 대한 가정 | 등분산성 (시간에 따라 분산이 일정함) | 조건부 이분산성 (분산이 변함) | 조건부 이분산성 (분산이 변함) |
| 변동성 모델링 요소 | 오차항 자체의 패턴 (평균 모델링) | 과거의 잔차 제곱 (최근의 충격) | 과거의 잔차 제곱 + 과거의 조건부 분산 |
| 장점 | 데이터의 거시적 추세 및 평균 예측 | 변동성 군집 현상 수학적 포착 | 적은 파라미터로 장기 변동성 지속성 모델링 |
| 단점 및 한계 | 이상치 및 급격한 변동성 변화 설명 불가 | 파라미터()가 과도하게 많아질 수 있음 | 양/음의 충격 비대칭성 미반영 (EGARCH 등으로 보완 필요) |
시계열 데이터, 특히 금융 데이터에서 빈번하게 관찰되는 변동성 군집 현상(Volatility Clustering)을 모델링하기 위한 통계적 방법론인 ARCH와 GARCH 모델을 설명한다. 기존의 선형 시계열 모델(ARIMA 등)이 오차항의 등분산성(Homoscedasticity)을 가정하는 반면, 이 모델들은 조건부 이분산성(Conditional Heteroskedasticity)을 직접 모델링하여 예측의 정확도를 높인다.
- ARCH (Autoregressive Conditional Heteroskedasticity) ARCH 모델은 1982년 Robert Engle이 제안한 모델로, 특정 시점의 오차항의 분산(조건부 분산)이 과거 오차항들의 크기(제곱)에 의존한다고 가정하는 자기회귀 조건부 이분산성 모델이다.
통계적 근거: 큰 변동성 뒤에는 큰 변동성이, 작은 변동성 뒤에는 작은 변동성이 따르는 시계열의 특징을 포착한다. 변동성이 시간에 따라 변화함을 인정하고 이를 과거의 정보로 회귀 분석한다.
ARCH(q) 모델의 조건부 분산 수식은 다음과 같다.
- : t 시점의 조건부 분산
- : 상수항 ()
- : 과거 i 시점의 오차항(백색잡음으로부터 도출된 충격)의 제곱
- : 과거 오차항의 제곱이 현재 분산에 미치는 영향을 나타내는 가중치 ()
ARCH 모델의 한계: 과거의 충격이 현재의 변동성에 미치는 영향을 충분히 설명하기 위해서는 시차 를 매우 크게 설정해야 할 때가 많으며, 이는 추정해야 할 파라미터 수의 증가로 이어져 과적합(Overfitting) 위험과 모델의 비효율성을 초래한다.
- GARCH (Generalized Autoregressive Conditional Heteroskedasticity)
GARCH 모델은 1986년 Tim Bollerslev가 ARCH 모델을 일반화한 것이다. ARCH 모델에 과거의 조건부 분산 자체를 설명변수로 추가하여, ARMA 모델이 AR 모델을 보완하듯 ARCH 모델의 파라미터 과다 문제를 해결했다.
통계적/ML 근거: GARCH 모델은 무한한 차수의 ARCH 모델을 적은 수의 파라미터로 근사(Approximation)할 수 있어 모델의 파시모니(Parsimony, 간결성)를 확보한다. 대부분의 금융 시계열 데이터에서는 GARCH(1,1) 모델만으로도 충분한 변동성 설명력을 가진다.
GARCH(p, q) 모델의 조건부 분산 수식은 다음과 같다.
-
: 과거 j 시점의 조건부 분산 항목. 과거의 변동성 수준이 현재 변동성에 지속적으로 미치는 영향(지속성, Persistence)을 포착한다.
-
모수 제약 조건: 분산은 항상 양수여야 하므로 , , 이어야 하며, 시계열의 안정성(Stationarity)을 위해 이어야 한다.
VAR
| 모형 | 대상 변수 개수 | 내생성 가정 | 데이터 정상성 요구 | 핵심 사용 목적 |
|---|---|---|---|---|
| AR / ARIMA | 1개 (일변량) | 해당 없음 | 정상성 필수 (ARIMA는 내부 차분 포함) | 단일 변수의 과거 패턴을 통한 미래 예측 |
| VAR | 2개 이상 (다변량) | 모든 변수가 내생변수 | 정상성 필수 | 다변량 변수 간의 동적 상호작용 분석 및 예측 |
| VECM | 2개 이상 (다변량) | 모든 변수가 내생변수 | 비정상 시계열 중 공적분 존재 시 | 공적분 관계를 활용한 장단기 균형 조정 과정 모델링 |
다변량 시계열 분석의 핵심 방법론인 VAR(Vector Autoregression, 벡터 자기회귀) 모형의 개념, 수학적 원리, 그리고 통계적 모델링 절차를 정리한다.
- VAR 모형의 개념 및 수학적 원리
단일 변수의 과거 값만으로 미래를 예측하는 일변량 자기회귀(AR) 모형과 달리, VAR 모형은 서로 영향을 주고받는 여러 다변량 시계열 변수들의 동적인 관계를 동시에 모델링하는 기법이다. 경제학 및 머신러닝 시계열 예측에서 다수의 종속변수가 서로 내생성(Endogeneity)을 가질 때 독립변수와 종속변수의 사전적 구분 없이 모든 변수를 내생변수로 취급하여 시스템 단위로 추정한다.
k개의 변수와 시차 p를 가지는 VAR(p) 모형의 수학적 형태는 다음과 같다.
- : t 시점의 k×1 내생변수 벡터
- : k×1 상수항(절편) 벡터
- : i번째 시차의 k×k 회귀계수 행렬 (i=1,…,p)
- : t 시점의 k×1 오차 벡터 (백색잡음 과정, 오차항 간에는 서로 상관성이 없어야 함)
- 통계학적 전제 조건 및 모델링 절차
VAR 모형을 적합시키기 위해서는 통계적 엄밀성을 요구하는 다음의 절차를 따라야 한다.
정상성(Stationarity) 검정: VAR 모형을 구성하는 모든 시계열 변수는 통계적 정상성을 만족해야 한다. 주로 ADF(Augmented Dickey-Fuller) 검정을 통해 단위근 존재 여부를 확인하며, 비정상 시계열일 경우 차분(Differencing)을 수행해야 한다.
공적분(Cointegration) 검정: 차분한 데이터가 아닌 원본 비정상 데이터들 간에 장기적인 균형 관계(공적분)가 존재하는지 Johansen 검정 등으로 확인한다. 공적분이 존재한다면 VAR 대신 오차수정모형(VECM)을 사용해야 한다.
최적 시차(p) 선정: 모델의 설명력과 파라미터 수의 페널티를 동시에 고려하는 정보 기준(Information Criterion)을 사용한다. 일반적으로 AIC(Akaike Information Criterion), BIC(Bayesian Information Criterion), HQIC 지표가 최소가 되는 시차 p를 선택한다.
그레인저 인과관계(Granger Causality) 검정: 특정 변수 X의 과거 값이 다른 변수 Y의 현재 값을 예측하는 데 통계적으로 유의미한 정보를 제공하는지 검정하여, 모델 내 변수 간의 방향성을 파악한다.
충격반응함수(IRF) 및 분산분해(VD): 모형 추정 후, 한 변수의 오차항에 1 표준편차 크기의 충격(Shock)이 가해졌을 때 다른 변수들이 시간에 따라 어떻게 반응하는지 추적(IRF)하고, 예측 오차의 분산이 각 변수들의 충격에 의해 어떻게 설명되는지 분해(VD)하여 변수 간의 영향력을 정량화한다.