회귀 (로지스틱은 지도)
temp = model.summary().tables[1]
df_coef = pd.read_html(temp.as_html(), header=0)[0]
df_coef| 검정 대상 | 검정 방법 | 귀무가설 () | 대립가설 () | 귀무가설 서술 (Text ) | 대립가설 서술 (Text ) | 통계적 의미 |
|---|---|---|---|---|---|---|
| 모델 전체 (Overall Model) | F-검정 (F-test) | 적어도 하나의 회귀계수 | 모형에 포함된 모든 독립변수의 회귀계수는 0이다. (회귀모형이 통계적으로 유의하지 않다.) | 모형에 포함된 독립변수 중 적어도 하나의 회귀계수는 0이 아니다. (회귀모형이 통계적으로 유의하다.) | 추정된 회귀모형이 통계적으로 유의미한 설명력을 가지는지 평가 | |
| 개별 변수 (Individual Coefficient) | t-검정 (t-test) | 특정 | 특정 | 특정 독립변수의 회귀계수는 0이다. (해당 독립변수는 종속변수를 설명하는 데 기여하지 않는다.) | 특정 독립변수의 회귀계수는 0이 아니다. (해당 독립변수는 종속변수를 설명하는 데 유의미하게 기여한다.) | 특정 독립변수 가 종속변수 에 유의미한 영향을 미치는지 개별 평가 |
배열 기반 API(statsmodels.api.OLS)
- 절편 규칙: OLS, QuantReg, GLM, WLS 등 모든 통계 모형에서 기본적으로 절편을 포함하지 않는다. 절편 추정을 위해서는 반드시 모델 훈련 전에 사용자가 직접 sm.add_constant(X)를 통해 X 행렬의 좌측에 1로 가득 찬 상수항 열(column)을 수동으로 추가해야 한다.
포뮬러 기반 API(statsmodels.formula.api.quantreg)
- 절편 규칙: 내부적으로 patsy 패키지를 사용하여 독립변수 행렬을 파싱 및 구성하는데, 이때 R 언어의 기본 동작 방식과 동일하게 절편(상수항)이 자동으로 추가된다. 따라서 add_constant 과정이 필요 없다. 만약 강제로 절편을 빼고 원점을 지나는 회귀를 하려면 포뮬러에 - 1 또는 + 0을 명시해야 한다 (예: ‘y ~ x - 1’).
| API 모듈 | 대표적인 클래스 호출 | 절편(Intercept) 기본값 | 절편 제어 방법 |
|---|---|---|---|
statsmodels.api | sm.OLS(y, X)sm.QuantReg(y, X) | 미포함 | 포함하려면 sm.add_constant(X) 실행 |
statsmodels.formula.api | smf.ols('y ~ X', data)smf.quantreg('y ~ X', data) | 포함 | 제거하려면 포뮬러 문자열에 - 1 명시 |
import numpy as np; import pandas as pd
import sklearn
import sklearn.datasets
housing = sklearn.datasets.fetch_california_housing()
df = pd.DataFrame(housing.data, columns=housing.feature_names)
df['target'] = housing.target
y = df['target']; X = df.drop(['target'], axis=1)
# 예시 데이터 로드 및 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)OLS (단순, 다중, 다항회귀)
- 상호작용을 포함한 다중 회귀 모델의 기본 식
if '단순회귀 (OLS)':
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X, y)
display(pd.DataFrame({'회귀계수': [lr.coef_], '절편': [lr.intercept_]}).T)
# =========================================================================
# ↑ sklearn ↓ statsmodels, (X,y) 순서
# =========================================================================
import statsmodels.api as sm
X = sm.add_constant(X) # statsmodels의 OLS는 절편(β 0)을 자동으로 계산하지 않는다.
model = sm.OLS(y, X).fit()
# display(model.summary())
for each in model.summary().tables:
display(each)
display(pd.DataFrame({'결정계수': [model.rsquared], '수정된 결정계수': [model.rsquared_adj]}).T)정규화 선형회귀 (릿지, 라쏘)
| 기법 | 목적 및 특징 | 규제(Regularization) 방식 | 주요 활용 및 한계 |
|---|---|---|---|
| 일반 선형 회귀 (OLS) | 독립변수와 종속변수 간의 선형 관계 모델링 | 없음 | 다중공선성에 취약하며, 이상치에 매우 민감함. |
| 릿지 회귀 (Ridge) | 과적합 방지, 분산 감소를 통한 모델 안정성 확보 | L2 규제 (계수 제곱합) | 독립변수 간 상관관계가 높을 때 유용함. 변수 제거가 불가능함. |
| 라쏘 회귀 (Lasso) | 희소 모델(Sparse Model) 구축, 중요한 변수만 선택 | L1 규제 (계수 절대값 합) | 노이즈 변수가 많을 때 효과적. 상관성이 높은 변수 그룹 중 하나만 선택하는 경향이 있음. |
| 엘라스틱 넷 (Elastic Net) | Ridge와 Lasso의 장점을 결합하여 모델 강건성 확보 | L1 + L2 결합 | 변수 선택과 다중공선성 완화를 동시 수행함. 파라미터 튜닝 연산 비용이 큼. |
| 로지스틱 회귀 (Logistic) | 이진 분류 문제 해결 (오즈비(Odds Ratio) 해석 가능) | 필요시 L1/L2 적용 | 선형 결정 경계(Linear Decision Boundary)를 가지므로 복잡한 비선형 데이터 분류에 한계가 있음. |
if '패널티 회귀':
# 2. 데이터 스케일링 (필수 과정)
# Ridge, Lasso, Elastic Net과 같이 규제가 포함된 회귀 모델에서는 스케일링이 필수적입니다.
# 변수들의 스케일이 다르면 특정 변수의 계수에만 과도한 페널티가 적용될 수 있기 때문입니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 3. 모델 정의
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.metrics import mean_squared_error
# (alpha 파라미터는 패널티 강도)
alpha_val = 1.0
ridge_model = Ridge(alpha=alpha_val)
lasso_model = Lasso(alpha=alpha_val)
# l1_ratio: 0이면 Ridge와 동일, 1이면 Lasso와 동일
elastic_model = ElasticNet(alpha=alpha_val, l1_ratio=0.5)
# 4. 모델 학습
ridge_model.fit(X_train_scaled, y_train)
lasso_model.fit(X_train_scaled, y_train)
elastic_model.fit(X_train_scaled, y_train)
# 5. 예측 및 평가 (MSE)
models = {'Ridge': ridge_model, 'Lasso': lasso_model, 'ElasticNet': elastic_model}
print("--- 모델별 MSE 및 0이 아닌 회귀 계수 개수 ---")
for name, model in models.items():
pred = model.predict(X_test_scaled)
mse = mean_squared_error(y_test, pred)
# 회귀 계수가 0이 아닌 변수의 수 (Feature Selection 확인)
non_zero_coefs = np.sum(model.coef_ != 0)
print(f"{name:<10} | MSE: {mse:.4f} | 사용된 변수 개수: {non_zero_coefs}/{X.shape[1]}")
교호작용 유무에 다른 회귀모형
if 'interaction':
import statsmodels.api as sm
import statsmodels.formula.api as smf
spector_data = sm.datasets.spector.load_pandas().data; df=spector_data
# model = smf.ols('GRADE ~ GPA + PSI + GPA:PSI', data=df).fit()
# GPA:PSI는 GPA와 PSI의 교호작용
model = sm.formula.ols('GRADE ~ GPA + PSI + GPA:PSI', data=df).fit()
display(model.summary())다항 Polynomial
import numpy as np; import pandas as pd
m = 100
X = 6 * np.random.rand(m,1) - 3
y = 3 * X**3 + X**2 + 2*X + 2 + np.random.randn(m,1) #노이즈 포함
line = np.linspace(-3,3,100, endpoint=False).reshape(-1,1)
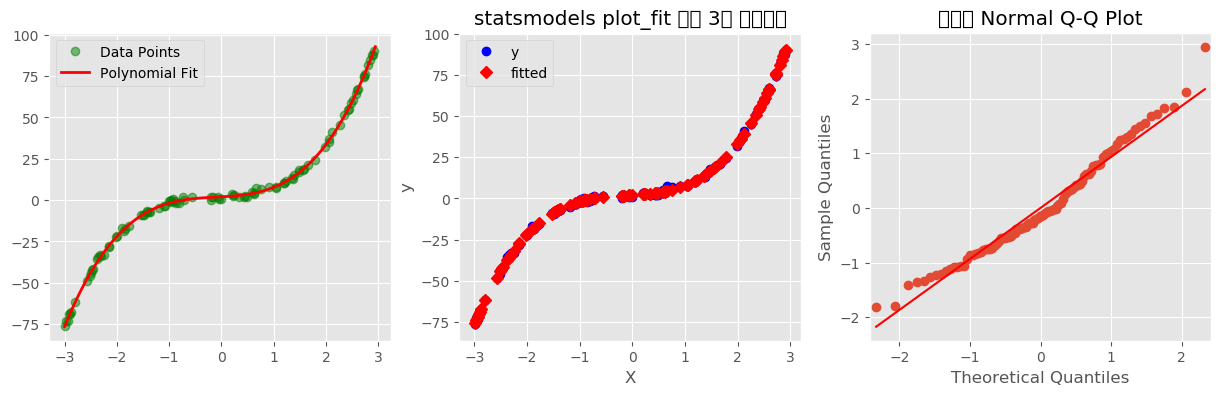
df = pd.DataFrame({'X': X.T[0], 'y': y.T[0]})if '다항회귀':
import matplotlib.pyplot as plt; plt.style.use('ggplot'); plt.clf()
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
axes = axes.flatten()
from sklearn.preprocessing import PolynomialFeatures
poly=PolynomialFeatures(degree=3, include_bias=False)
poly.fit(X)
X_poly = poly.transform(X)
line_poly=poly.transform(line)
from sklearn.linear_model import LinearRegression
reg=LinearRegression().fit(X_poly, y)
axes[0].plot(X, y, 'o', c='g', alpha=0.5, label='Data Points')
axes[0].plot(line, reg.predict(line_poly), label='Polynomial Fit', color='red', linewidth=2)
axes[0].legend()
# =========================================================================
# ↑ sklearn ↓ statsmodels, (X,y) 순서
# =========================================================================
# import matplotlib.pyplot as plt; plt.style.use('ggplot'); plt.clf()
# import statsmodels.formula.api as smf
import statsmodels.api as sm
# 1. 모형 적합
# model = smf.ols('y ~ X + I(X**2) + I(X**3)', data=df).fit()
# model = sm.formula.ols('y ~ X + I(X**2) + I(X**3)', data=df).fit()
model = sm.formula.ols('y ~ X + I(X**2) + I(X**3)', data=df).fit()
# 2. 내장 메서드를 이용한 회귀선 및 신뢰구간 시각화
# fig, ax = plt.subplots(figsize=(8, 6))
# plot_fit은 결과를 ax(축) 객체에 바로 그려준다.
# exog_idx에는 시각화할 기준이 되는 원본 독립변수의 이름('HouseAge')을 문자열로 입력한다.
# sm.graphics.plot_fit(model, exog_idx='X', ax=ax)
sm.graphics.plot_fit(model, exog_idx='X', ax=axes[1])
axes[1].set_title('statsmodels plot_fit 통한 3차 다항회귀')
axes[1].grid(True)
# plt.show()
# 3. 잔차 정규성 확인을 위한 Q-Q 플롯 시각화
fig_qq = sm.qqplot(model.resid, line='s', ax=axes[2])
axes[2].set_title('잔차의 Normal Q-Q Plot')
plt.show()
GLM (푸아송 / 음이항)
종속변수가 정규분포를 따르지 않는 범주형 데이터나 카운트 데이터인 경우, 기존 일반 선형 회귀의 한계를 극복하기 위해 사용된다.
GLM은 오차항의 분포를 정규분포에서 지수족(Exponential Family) 분포로 확장한 모델이다. 다음 세 가지 핵심 요소로 구성된다.
-
확률 요소 (Random Component): 종속변수 Y의 확률 분포를 정의한다. (예: 정규분포, 이항분포, 푸아송분포 등)
-
체계적 요소 (Systematic Component): 독립변수 X들의 선형 결합인 선형 예측자(Linear Predictor) 를 정의한다.
-
연결 함수 (Link Function): 종속변수의 기댓값 를 선형 예측자 η와 수학적으로 연결하는 함수 이다. 즉,
| 모델명 | 확률 요소 (분포) | 기본 연결 함수 (Link Function) | 주요 활용 및 특징 |
|---|---|---|---|
| 일반 선형 회귀 (Linear) | 정규분포 (Normal) | 항등 (Identity): | 연속형 종속변수 예측. 오차의 정규성 및 등분산성 가정 필요. |
| 로지스틱 회귀 (Logistic) | 이항분포 (Binomial) | 로짓 (Logit): | 이진 분류 문제. 결과값을 0~1 사이의 확률로 변환. |
| 푸아송 회귀 (Poisson) | 푸아송분포 (Poisson) | 로그 (Log): | 단위 시간/공간당 발생 횟수(Count) 예측. 평균과 분산이 같다는 가정 적용. 응답 변수가 카운트 데이터(예: 어떤 시간 동안 발생하는 이벤트의 횟수)일 때 사용되는 회귀 모델 |
| 음이항 회귀 (Negative Binomial) | 음이항분포 (Negative Binomial) | 로그 (Log): | 과산포(Overdispersion)가 존재하는 Count 데이터 예측. 푸아송 회귀의 대안. 과산포 상황에 대한 대응책 |
| 감마 회귀 (Gamma) | 감마분포 (Gamma) | 역수 (Inverse): | 우측으로 꼬리가 긴 양의 연속형 변수(보험 청구 금액 등) 모델링. |
푸아송회귀
import numpy as np; import pandas as pd
import sklearn
import statsmodels.api as sm
df = pd.DataFrame({
'store': ['A', 'B', 'C', 'D']
, 'sales': [30, 5, 25, 12]
, 'ad_hours': [10, 1, 8, 4] # 광고 노출 시간
, 'visitors': [500, 80, 450, 200]
})
y=df['sales'], X=df['visitors']
if '푸아송':
# formula = 'sales ~ visitors'
# model = sm.formula.glm(formula=formula, data=df
# , family=sm.families.Poisson()).fit()
model = sm.GLM(y, X, family=sm.families.Poisson()).fit()
# offset0 = np.log(df['ad_hours'])
# model_offset = sm.formula.glm(formula=formula, data=df
# , family=sm.families.Poisson(), offset=offset0).fit()
# model_offset = sm.GLM(y, X, family=sm.families.Poisson(), offset=offset0).fit()
display(model.summary())
# model.predict(pd.DataFrame({'visitors': [300]}))
# model.predict(pd.DataFrame({'visitors': [300]}), offset=np.log([10]))
# 모델 적합 후 (model = sm.GLM(...).fit())
print(f"Pearson Chi2: {model.pearson_chi2:.4f}")
print(f"자유도: {model.df_resid}")
print(f"과산포 지수: {model.pearson_chi2 / model.df_resid:.4f}")
| Dep. Variable: | affairs | No. Observations: | 6366 |
|---|---|---|---|
| Model: | GLM | Df Residuals: | 6359 |
| Model Family: | Poisson | Df Model: | 6 |
| Link Function: | Log | Scale: | 1.0000 |
| Method: | IRLS | Log-Likelihood: | -9111.2 |
| Date: | Tue, 10 Mar 2026 | Deviance: | 13763. |
| Time: | 23:33:41 | Pearson chi2: | 3.16e+04 |
| No. Iterations: | 6 | Pseudo R-squ. (CS): | 0.3021 |
| Covariance Type: | nonrobust |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 3.4642 | 0.142 | 24.326 | 0.000 | 3.185 | 3.743 |
| rate_marriage | -0.5055 | 0.013 | -37.873 | 0.000 | -0.532 | -0.479 |
| age | -0.0216 | 0.005 | -4.130 | 0.000 | -0.032 | -0.011 |
| yrs_married | -0.0270 | 0.006 | -4.662 | 0.000 | -0.038 | -0.016 |
| children | -0.0397 | 0.018 | -2.173 | 0.030 | -0.075 | -0.004 |
| religious | -0.3702 | 0.018 | -20.613 | 0.000 | -0.405 | -0.335 |
| educ | -0.0115 | 0.008 | -1.528 | 0.126 | -0.026 | 0.003 |
| 진단 기법 | 판단 지표 | 과산포 판정 기준 | 비고 |
|---|---|---|---|
| 기초 통계량 | 분산 > 평균 | 빠르고 직관적이나 엄밀하지 않음 | |
| 과산포 지수 | 수치가 1보다 클 때 | 실무/시험에서 가장 많이 사용 | |
| 보조 회귀 검정 | 의 유의성 (-value) | 학술적으로 가장 권장되는 방식 (Cameron & Trivedi의 회귀 기반 검정) |
| 모델/기법 | 특징 및 대처 방식 | 분산() 구조 |
|---|---|---|
| Negative Binomial (NB) | 과산포를 설명하기 위해 신축적인 파라미터()를 도입한 모델. 가장 일반적인 대안임. | |
| Quasi-Poisson | 회귀 계수 추정치는 푸아송과 동일하나, 분산 구조를 수정하여 표준오차를 조정함. | |
| Zero-Inflated Model | 과산포의 원인이 ‘0’의 과도한 발생(Excess Zeros)일 경우 ZIP 또는 ZINB 모델을 사용함. | 모델 구조에 따라 상이 |
| 샌드위치 추정량 | 강건한 표준오차(Robust Standard Errors)를 사용하여 분산 가정을 완화함. | 해당 없음 (추정 방식 변경) |
음이항
if '음이항':
# nb_model = sm.formula.glm('sales ~ visitors'
# , data=df, family=sm.families.NegativeBinomial(alpha=1.0)).fit()
nb_model_auto_alpha = sm.formula.negativebinomial('sales ~ visitors'
, data=df).fit()
# nb_model = sm.formula.glm('sales ~ visitors - 1'
# nb_model = sm.formula.glm('sales ~ 0 + visitors'
# , data=df, family=sm.families.NegativeBinomial(alpha=1.0)).fit()
# print(nb_model.summary())
print(nb_model_auto_alpha.summary())
GAM (스플라인)
| 구분 | GLM (Generalized Linear Model) | GAM (Generalized Additive Model) |
|---|---|---|
| 선형 예측자 | ||
| 연결 함수 | ||
| 가정 | 변수와 반응 변수 간 선형성 가정 | 선형성 가정 완화 (비선형 허용) |
| 특징 | 파라미터 기반 (Parametric) | 준모수적 (Semi-parametric) |
GAM(일반화 가법 모형) 은 예측 변수와 반응 변수 사이의 비선형 관계를 파악하기 위해 고안된 회귀 분석 기법이다.
선형 회귀의 확장판으로, 각 독립 변수 에 대해 유연한 매끄러운 함수(smoothing function) 를 적용하여 변수 간의 비선형 결합을 모델링한다.
- 유연성과 해석력의 트레이드오프: GLM은 해석이 매우 명확하지만 비선형 패턴을 놓칠 위험이 크다. GAM은 비선형 패턴을 잘 포착하면서도, 가법성(Additivity) 덕분에 여전히 각 변수의 기여도를 개별적으로 해석할 수 있다는 장점이 있다.
GAM의 핵심은 선형 회귀의 항을 유연한 유연한 평활 함수 로 대체하는데 있다. 평활 함수는 데이터의 국소적인 변동(noise)은 무시하면서 전체적인 추세(signal)를 부드러운 곡선 형태로 추출하는 역할을 수행한다.
| 기법 | 특징 | ADP 실기 적용 팁 |
|---|---|---|
| Cubic Splines | 구간별 3차 다항식을 연결하며 연결점에서 미분 가능함 | 가장 일반적인 선택 |
| Thin Plate Splines | 다변량 평활에 강점이 있으며 매듭(Knot) 위치 선정이 자유로움 | mgcv 패키지의 기본값 |
| P-splines | B-spline에 패널티를 부여하여 계산 효율성을 높임 | 대용량 데이터에 유리 |
| 비교 기준 | 스플라인 회귀 (Spline Regression) | 일반화 가법 모형 (GAM) |
|---|---|---|
| 개념적 위치 | 구체적인 평활(Smoothing) 기법 | 여러 평활 기법을 결합하는 구조적 프레임워크 |
| 적용 범위 | 주로 단일 혹은 소수의 변수에 대한 곡선 적합 | 다수의 변수가 종속 변수에 미치는 영향을 동시에 모델링 |
| 함수 형태 | B-spline, Natural Cubic Spline 등으로 한정됨 | Spline, LOESS, 다항식 등 제약 없이 사용 가능 |
| ADP 실기 적용 | 단일 변수의 비선형 파생 변수 생성 시 활용 | 전체 예측 파이프라인의 메인 회귀/분류 모델로 활용 |
GAM은 스플라인 회귀를 품는 더 큰 그릇이다. GAM의 평활 함수 로는 스플라인뿐만 아니라 국소 회귀(LOESS), 다항 회귀(Polynomial Regression), 스텝 함수(Step Function) 등 다양한 비선형 함수가 사용될 수 있다.
다만, 현대의 데이터 분석 및 mgcv, pyGAM과 같은 라이브러리에서는 계산 효율성과 평활도 제어(Penalized Splines)의 이점 때문에 스플라인을 GAM의 기본 평활 함수로 채택하고 있다. 이로 인해 실무에서는 두 개념이 혼용되어 쓰이는 경향이 있다.
스플라인
| 비교 항목 | 일반 선형 회귀 (OLS) | 스플라인 회귀 | 분위수 회귀 |
|---|---|---|---|
| 추정 대상 | 조건부 평균 | 조건부 평균 (일반적으로 OLS 기반 추정) | 특정 조건부 분위수 (예: 10%, 50%, 90%) |
| 비용 함수 | 오차 제곱합 (MSE) | 오차 제곱합 + 패널티 (평활 스플라인의 경우) | 핀볼 손실 (비대칭 절대 오차) |
| 주요 목적 | 선형 관계 파악 | 비선형 곡선의 매끄러운 적합 | 이상치에 대한 강건함, 데이터의 전체 분포 특성 파악 |
| 기존 모델 한계 극복 | - | 다항 회귀의 경계 진동(Runge’s phenomenon) 해결 | OLS의 이상치 민감도 및 등분산성 가정 한계 극복 |
스플라인 회귀와 분위수 회귀의 개념, 수학적 원리, 그리고 기존 회귀 모델과의 연결성을 통계학 및 머신러닝 관점에서 정리한다.
- 스플라인 회귀 (Spline Regression) 스플라인 회귀는 독립변수의 전체 구간을 여러 개의 소구간으로 나누고, 각 구간에 서로 다른 다항식을 적합시키는 비선형 모델링 기법이다. 구간을 나누는 지점을 매듭(Knot)이라고 하며, 매듭 지점들에서 함수값과 일정 차수의 미분값이 연속이 되도록 제약조건을 부여하여 곡선을 매끄럽게 연결한다.
대표적으로 사용되는 3차 스플라인(Cubic Spline) 회귀의 수식은 다음과 같다.
여기서 는 k번째 매듭을 의미하며, 함수 는 x>0일 때 x, 그렇지 않으면 0을 반환하는 절단 멱함수(Truncated power basis)이다.
기존 회귀와의 연결성:
-
선형 회귀의 비선형 확장: 일반적인 다중 선형 회귀는 변수 간의 선형성 가정을 전제로 하므로 비선형 패턴을 설명할 수 없다. 스플라인 회귀는 기저 함수(Basis function)를 추가함으로써 선형 모델의 틀을 유지하면서 비선형 관계를 유연하게 학습할 수 있도록 확장한 모델이다.
-
다항 회귀(Polynomial Regression)의 한계 극복: 전체 데이터에 단일 고차 다항식을 적합시킬 경우, 차수가 높아짐에 따라 양극단 경계에서 예측값이 크게 요동치는 룬게 현상(Runge’s phenomenon)이 발생한다. 스플라인은 지역적(Local) 구간에만 저차 다항식을 적용하여 과적합 및 경계 불안정성을 통제하는 개선된 방식이다.
np.random.seed(42)
X = np.sort(np.random.uniform(0, 10, 100)).reshape(-1, 1)
y = np.sin(X).ravel() + np.random.normal(0, 0.3, 100)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
if 'GAM':
if 'sm':
from statsmodels.gam.api import GLMGam, BSplines
# 기저 함수 생성
# 출력변수숫자는 5+5=10 (df)
bs = BSplines(X_train
, df=[5, 5] # 3~10 사이, AIC 로 체크
, degree=[3, 3] #x1의 차수, x2의 차수, …
)
# GLMGam 모델 정의 (Family는 분포에 따라 선택)
gam_model = GLMGam(endog=y_train
, exog=None # linear 관계로 모델에 포함됨
, smoother=bs # nonlinear 관계로 모델에 포함됨
, family=sm.families.Gaussian())
gam_model = gam_model.fit()
# print(gam_model.summary())
if 'sklearn':
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import SplineTransformer
from sklearn.linear_model import (
PoissonRegressor # y가 카운트 데이터일 경우
, LogisticRegression # y가 이진 데이터일 경우
, LinearRegression # y가 연속형 데이터일 경우
)
family = LinearRegression()
# 스플라인 pipeline (3차 스플라인, 매듭수 4개, 출력변수숫자 4+3-1=6)
spline_model = make_pipeline(
SplineTransformer(n_knots=4
, degree=3
, include_bias=False)
, family
)
# 3. 모델 학습 및 예측
spline_model.fit(X, y)
y_pred_spline = spline_model.predict(X)
# 변환된 B-스플라인 피처의 형태 확인 (참고용)
X_transformed = spline_model.named_steps['splinetransformer'].transform(X)
print(f"변환된 데이터 shape: {X_transformed.shape}")
분위수 회귀 (Quantile Regression)
분위수 회귀는 독립변수 X가 주어졌을 때 종속변수 Y의 조건부 평균을 추정하는 대신, 조건부 분위수(Quantile, 예를 들어 중앙값 혹은 상위 90% 등)를 추정하는 방법론이다. 특정 분위수 τ를 추정하기 위해 오차 제곱합 대신 비대칭 형태의 핀볼 손실 함수(Pinball loss function)를 최소화한다.
목적 함수(비용 함수)는 다음과 같다.
이때, 핀볼 손실 함수 는 다음과 같이 정의된다.
여기서 는 지시 함수(Indicator function)이다.
기존 회귀와의 연결성:
-
최소제곱법(OLS) 선형 회귀의 대안 및 확장: 기존 OLS는 조건부 평균인 를 추정하므로 이상치(Outlier)에 매우 민감하며, 오차항의 정규성 및 등분산성 가정을 엄격히 요구한다. 반면 분위수 회귀는 중앙값() 등을 타겟으로 할 수 있어 이상치에 대해 강건(Robust)하다.
-
이분산성(Heteroscedasticity) 분석: OLS는 평균만을 보여주지만, 분위수 회귀는 여러 τ값에 대한 추정을 통해 X의 변화에 따라 Y의 분산이 어떻게 변하는지, 분포의 양극단(Tail) 형태가 어떻게 다른지 전체적인 조건부 분포의 그림을 파악할 수 있게 해준다.
if '분위수':
import statsmodels.formula.api as smf
# 2. 분위수 회귀 모델 구축 및 학습 (단일 분위수: 중앙값 0.5)
# R-style formula를 사용하여 종속변수와 독립변수를 정의한다.
mod = smf.quantreg('y ~ X', df)
res_50 = mod.fit(q=0.5)
# 3. 통계적 결과 요약표 출력
print(res_50.summary())
# 여러 분위수(예: 10%, 50%, 90%)에 대한 예측을 수행할 경우
quantiles = [0.1, 0.5, 0.9]
predictions = {}
for q in quantiles:
res = mod.fit(q=q)
predictions[q] = res.predict(df['X'])베이지안
| 비교 항목 | 빈도주의 일반 선형 회귀 (OLS) | 베이지안 회귀 |
|---|---|---|
| 파라미터에 대한 관점 | 고정된 미지의 상수 | 확률 분포를 가지는 확률 변수 |
| 추정 방식 | 우도 최대화 (MLE: Maximum Likelihood Estimation) | 사후 확률 최대화 (MAP) 또는 사후 분포 샘플링 |
| 결과물 | 단일 점 추정치 (Point Estimate) | 파라미터의 확률 분포 (Posterior Distribution) |
| 정규화(Regularization) | 페널티 항을 수동으로 추가 (Ridge, Lasso) | 사전 확률(Prior) 부여를 통해 자연스럽게 정규화 수행 |
| 연산량 | 행렬 연산 기반으로 속도가 매우 빠름 | MCMC 등 복잡한 알고리즘 필요로 속도가 느림 |
1. 베이지안 회귀의 개념 및 수학적 원리
-
기존의 빈도주의(Frequentist) 기반 선형 회귀(OLS)는 모델의 가중치(파라미터)를 알 수 없는 고정된 상수로 취급하고, 주어진 데이터를 가장 잘 설명하는 단일 최적값을 점 추정(Point estimation)
-
반면, 베이지안 회귀는 가중치를 확률 변수로 취급하여 데이터가 주어졌을 때 가중치의 사후 분포(Posterior distribution)를 추정하는 기법
-
베이지안 회귀는 베이즈 정리(Bayes’ Theorem)를 기반으로 파라미터의 분포를 업데이트
-
P(β∣Y,X) : 사후 확률(Posterior). 주어진 데이터 X,Y를 바탕으로 업데이트된 가중치 β의 확률 분포.
-
P(Y∣X,β) : 우도(Likelihood). 주어진 가중치 β 하에서 관측 데이터가 나타날 확률.
-
P(β) : 사전 확률(Prior). 데이터를 관측하기 전에 가중치에 대해 연구자가 부여한 믿음(사전 지식).
-
P(Y∣X) : 증거(Evidence). 정규화 상수 역할을 하므로, 사후 확률은 우도와 사전 확률의 곱에 비례(∝)한다.
-
단일 최적해를 도출할 때는 사후 확률이 최대가 되는 지점을 찾는 MAP(Maximum A Posteriori) 추정을 수행한다.
2. 기존 회귀(정규화 모델)와의 연결성
-
머신러닝에서 과적합을 방지하기 위해 사용하는 L1, L2 정규화(Regularization)는 베이지안 관점에서 특정한 형태의 사전 확률 분포를 가정한 MAP 추정과 수학적으로 완벽히 동치
-
릿지 회귀 (Ridge Regression, L2 정규화): 가중치에 대한 사전 확률 가 평균이 0인 **정규 분포(Gaussian distribution)**를 따른다고 가정할 때의 사후 확률 최대화(MAP) 결과와 동일하다.
-
라쏘 회귀 (Lasso Regression, L1 정규화): 가중치에 대한 사전 확률 가 평균이 0인 **라플라스 분포(Laplace distribution)**를 따른다고 가정할 때의 사후 확률 최대화(MAP) 결과와 동일하다.
-
-
즉, 정규화 항(Penalty term)은 베이지안 회귀에서 가중치가 0 근처에 존재할 것이라는 통계적 믿음(사전 확률)을 수학적으로 제약조건화한 것이다.
3. 장단점 요약
-
장점:
-
예측값에 대한 단일 결과가 아닌 분포를 반환하므로 불확실성(Uncertainty)을 신뢰 구간(Credible Interval)의 형태로 명확히 정량화할 수 있다.
-
사전 지식을 반영하여 데이터가 적은 상황(Small data)에서도 과적합을 방지하고 안정적인 추정이 가능하다.
-
-
단점: 사후 분포를 해석적으로 구하기 힘든 경우가 많아 MCMC(Markov Chain Monte Carlo)나 변분 추론(Variational Inference) 같은 샘플링/근사 기법이 필요하며, 이는 높은 연산 비용을 요구한다.
if '베이지안':
from sklearn.linear_model import BayesianRidge
# 1. 베이지안 릿지 회귀 모델 인스턴스화
# 사전 확률의 하이퍼파라미터 초기값(alpha_1, lambda_1 등)을 설정할 수 있다.
bayesian_model = BayesianRidge(compute_score=True)
bayesian_model.fit(X, y)
# 3. 예측 및 예측의 표준편차(불확실성) 도출
# return_std=True를 설정하면 각 예측 지점에서의 표준편차를 반환한다.
# 이 구현의 가장 큰 장점은 예측값에 대한 표준편차(불확실성)를
# return_std=True 옵션으로 쉽게 추출할 수 있다는 점이다.
y_pred_bayes, y_std_bayes = bayesian_model.predict(X, return_std=True)
# 4. 베이즈 정리로 추정된 하이퍼파라미터 확인
print(f"추정된 alpha (노이즈 정밀도): {bayesian_model.alpha_:.4f}")
print(f"추정된 lambda (가중치 정밀도): {bayesian_model.lambda_:.4f}")import numpy as np; import pandas as pd
import statsmodels.api as sm
from scipy.stats import invgamma
if 'gibbs sampling':
VIF
-
해당 독립변수가 다른 1개 이상의 로부터 예측 가능할 때 발생
-
VIF 가 높을 경우 회귀모델의 계수 추정치가 불안정, 모델의 해석력과 예측력 하락
-
VIF 가 10 이상일 경우 보통 제거
-
한 번에 하나씩 제거하고 다시 VIF를 계산.
- VIF는 특정 변수가 ‘나머지 모든 변수’에 의해 얼마나 설명되는지를 나타내는 지표. 그래서 변수 하나를 제거하면 나머지 변수들 사이의 관계(상관관계)가 즉시 변한다. 만약 VIF가 높은 변수들을 한꺼번에 여러 개 지우면, 실제로는 남겨둬도 괜찮았던 유용한 변수까지 잃어버릴 위험
| 우선순위 | 판단 기준 | 통계적/비즈니스적 근거 |
|---|---|---|
| 1 | VIF 수치 | 공선성 유발 정도가 가장 큰 변수 우선 제거 |
| 2 | 도메인 중요도 | 분석 목적상 반드시 필요한 변수는 유지 고려 |
| 3 | 타겟 상관성 | 종속변수()와의 상관관계가 낮은 변수 우선 제거 |
선형 회귀 모델에서 상수항(Intercept)을 제외하고 원점을 지나는 회귀(RTO)를 수행할 때 발생하는 현상으로 옳은 것은?
- 잔차의 성질 변화 (선택지 C 관련)
일반적인 최소제곱법(OLS) 회귀 모델에서는 잔차의 합( )이 0이 되도록 하는 정규 방정식(Normal Equation)이 성립한다. 이는 비용 함수를 상수항()으로 미분했을 때 얻어지는 결과다.
하지만 상수항을 제외하면 이 조건이 사라지므로 잔차의 합이 0이 된다는 수학적 보장이 없 다. 즉, 인 경우가 일반적이다.
- 결정계수(R2) 산출 방식의 문제
상수항이 없는 모델에서는 전통적인 결정계수 정의식() 을 그대로 사용할 경우 R2 가 음수로 나올 수 있다. 이 때문에 많은 통계 소프트웨어는 RTO 모델에서 다른 방식의 R2 (Uncentered R2 )를 계산하며, 이는 종종 상수항이 있는 모델보다 겉보기에 더 높게 측정되기도 한다. 따라서 항상 작게 산출된다는 설명은 틀리다.
if 'VIF':
import sklearn.datasets
import pandas as pd
housing = sklearn.datasets.fetch_california_housing()
df = pd.DataFrame(housing.data, columns=housing.feature_names)
df['target'] = housing.target
# ===========================================================================================
#
# ===========================================================================================
import statsmodels.api as sm
# ===========================================================================================
# from statsmodels.stats.outliers_influence import variance_inflation_factor
# !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!VIF는반드시상수항필요!!!!!!!!!!!!!!!!!!!!!!!!!!
# ===========================================================================================
X = df.drop(columns=['target', 'Longitude', 'AveRooms', 'Latitude'])
# 1. 상수항 추가 (VIF 계산 시 필수)
X = sm.add_constant(X)
vif_data = pd.DataFrame()
vif_data["feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(len(X.columns))]
# vif_data = vif_data[vif_data['feature'] != 'const'].reset_index(drop=True)
vif_data = vif_data.sort_values(by='VIF', ascending=False).reset_index(drop=True)
vif_data
회귀모델 구축 시 독립변수 간 강한 상관관계로 인해 발생하는 다중공선성(Multicollinearity)을 줄이기 위한 3가지 주요 방법은 다음과 같다.
- VIF(분산팽창지수) 진단 및 변수 제거 (Variable Selection based on VIF)
다중공선성을 유발하는 변수를 식별하고 모델에서 직접 제거하는 방법이다. 일반적으로 VIF 값이 10 이상인 변수를 다중공선성이 심각한 것으로 간주하여 제거한다. i번째 독립변수의 VIF 산출 수식은 다음과 같다.
여기서 는 i번째 독립변수를 종속변수로 두고, 나머지 모든 독립변수들을 사용해 회귀분석을 수행했을 때 산출되는 결정계수(Coefficient of Determination)이다. 이 과정을 반복하며 VIF가 기준치 이하로 떨어질 때까지 변수를 순차적으로 제거한다.
- 정규화/규제화 회귀모델 적용 (Regularization: Ridge, Lasso, Elastic Net)
다중공선성이 존재하면 회귀계수(Coefficient)의 분산이 크게 팽창하여 모델의 신뢰성이 떨어진다. 이를 방지하기 위해 비용 함수에 페널티 항을 추가하여 회귀계수 크기를 축소하는 기법을 사용한다. 대표적으로 L2 페널티를 사용하는 릿지 회귀(Ridge Regression)가 다중공선성 완화에 효과적이다. 릿지 회귀의 목적 함수는 다음과 같다.
수식에서 λ는 규제의 강도를 조절하는 하이퍼파라미터이며, 이 값이 커질수록 다중공선성에 의한 계수 팽창이 억제된다. L1 페널티를 사용하는 라쏘(Lasso) 회귀는 상관성이 높은 변수 중 일부의 계수를 0으로 만들어 변수 선택의 효과를 동시에 제공한다.
- 주성분 분석(PCA)을 활용한 차원 축소 및 PCR (Principal Component Regression)
기존의 상관성이 높은 변수들을 선형 결합하여 분산을 최대로 보존하면서 서로 직교하는(독립적인) 새로운 변수인 주성분(Principal Components)을 추출하는 방법이다. 변환된 주성분 간에는 상관관계가 0이 되므로 다중공선성 문제가 구조적으로 발생하지 않는다. 추출된 주성분 중 설명력이 높은 상위 k개의 주성분만을 사용하여 회귀분석을 수행한다.