평균비교
| else | independent | dependent | |
|---|---|---|---|
| 1s | t-test | ||
| 2s | ind. t-test | paired t-test | |
| 3s+ | ANOVA | repeated ANOVA | |
| Welch | Mauchly, Greenhouse |
| 분석 기법 | 사용 상황 | 예시 | 귀무가설 () | 대립가설 () | 귀무가설 서술 (Text ) | 대립가설 서술 (Text ) |
|---|---|---|---|---|---|---|
| One-sample t-test | 단일 집단 평균 vs 특정 기준값 | A 과자 공장의 봉지당 무게가 100g인지 검정 | 모집단의 평균은 특정 기준값과 같다. | 모집단의 평균은 특정 기준값과 다르다. | ||
| Independent t-test | 두 독립 집단의 평균 비교 | 남학생과 여학생의 수학 성적 차이 비교 | 두 독립 모집단의 평균은 같다. (차이가 없다.) | 두 독립 모집단의 평균은 다르다. (차이가 있다.) | ||
| Paired t-test | 동일 집단의 전/후 차이 비교 | 다이어트 약 복용 전과 후의 체중 변화 비교 | 짝지어진 측정값 차이의 평균은 0이다. (전후 차이가 없다.) | 짝지어진 측정값 차이의 평균은 0이 아니다. (전후 차이가 있다.) | ||
| One-way ANOVA | 세 개 이상 독립 집단 평균 비교 | 3가지 종류의 비료에 따른 식물 성장 높이 비교 | 비교하는 모든 집단의 모집단 평균은 동일하다. | 적어도 한 집단의 모집단 평균은 다른 집단의 평균과 다르다. | ||
| Two-way ANOVA | 두 개의 독립변수에 따른 평균 비교 | 성별과 교육수준에 따른 연봉 차이 및 상호작용 분석 | 주효과 및 상호작용 효과 없음 | 적어도 하나의 효과가 존재함 | 각 독립변수의 주효과가 없으며, 두 독립변수 간의 상호작용 효과도 없다. | 적어도 하나의 독립변수에 대한 주효과가 존재하거나, 상호작용 효과가 존재한다. |
| Repeated Measures ANOVA | 동일 집단 3회 이상 반복 측정 | 약물 투여 후 1시간, 3시간, 6시간 뒤의 혈당 변화 | 모든 반복 측정 시점의 모평균은 동일하다. | 적어도 한 측정 시점의 모평균은 다른 시점의 모평균과 다르다. |
t-test
- 데이터가 정규분포를 따른다고 가정함
- 집단의 평균 차이를 검정
ANOVA
- 데이터가 정규분포를 따른다고 가정함
- 집단의 평균 차이를 검정
- ANOVA는 집단 간 변동과 집단 내 변동을 비교하여 평균 차이를 검정하며, 집단의 수가 많을수록 유용
이원배치 분산분석 twoway ANOVA
-
데이터가 정규분포를 따른다고 가정함
-
집단의 평균 차이를 검정
-
정의: 두 개의 독립적인 범주형 변수가 있는 경우, 각 변수와 이들의 상호작용이 종속 변수에 미치는 영향을 분석하는 통계적 방법. 예를 들어, 교육 방법과 성별이 학생 성적에 미치는 영향을 분석할 때 사용. 각 변수의 주 효과 및 상호작용 효과를 동시에 검정
-
가정 2개 (체크 필요)
- 정규성: 각 그룹의 데이터가 정규분포를 따른다는 가정. # Shapiro-Wilk
- 등분산성: 모든 그룹의 분산이 동일하다는 가정. # Levene
Tukey’s HSD (Honestly Significant Difference)
-
데이터가 정규분포를 따른다고 가정함
-
집단의 평균 차이를 검정
-
ANOVA 의 p값이 0.05이하일 경우, 사후분석으로 Tukey’s HSD 진행
- ANOVA pval 이 낮다는건, 그룹 중 “적어도 한 그룹의 평균은 다른 그룹들과 통계적으로 차이가 있다”
- Tukey HSD 를 통해 “구체적으로 어느 집단끼리 서로 다른가?” 를 확인
reject가 True 인 row
-
Tukey HSD 검정은 기본적으로 하나의 집단 변수를 기준으로 여러 그룹 간의 평균 차이를 비교하는 도구
-
하지만 우리가 분석하려는 데이터에는 Cu(구리 함량)와 Evit(비타민 E 유무)라는 두 가지 요인이 섞여 있음
-
pairwise_tukeyhsd는 한 번에 하나의 열만 “그룹”으로 인식 -
그래서 두 가지 요인을 모두 고려한 모든 조합(예: ‘Cu 고농도 + Evit 있음’, ‘Cu 저농도 + Evit 없음’ 등)을 비교하고 싶을 때, 두 변수를 하나로 합쳐서 새로운 복합 변수를 만듬
-
사전검정
import statsmodels.api as sm
df = sm.datasets.get_rdataset("dietox", "geepack").data
df_time1 = df[df['Time']==1]if '사전검정':
if '정규성 검정':
df_time1 = df[df['Time'] == 1]
for g in df_time1['Cu'].unique():
group_data = df_time1[df_time1['Cu'] == g]['Weight']
stat, p = stats.shapiro(group_data)
# 모든 그룹의 모든 그룹의 pval이 0.05 이상이어야 각 그룹이 정규성을 만족하며 ANOVA 에 문제가 없다
print(f"Cu {g} 그룹 (Time 1) 정규성 p-value: {p:.4f}")
if '등분산성 검정':
groups = [df_time1[df_time1['Cu'] == g]['Weight'] for g in df_time1['Cu'].unique()]
levene_stat, levene_p = stats.levene(*groups) # Levene 검정t-test
import numpy as np
import pandas as pd
from scipy import stats
import pingouin as pg
# 2. T-test (등분산 가정, Student's t-test)
# Levene's test 등에서 p-value >= 0.05 일 때 사용
t_stat_std, p_val_std = stats.ttest_ind(group_A, group_B, equal_var=True)
print(f"Student's t-test: t={t_stat_std:.4f}, p={p_val_std:.4f}")
# 3. Welch's T-test (등분산 위배, 이분산 가정)
# Levene's test 등에서 p-value < 0.05 일 때 사용
t_stat_welch, p_val_welch = stats.ttest_ind(group_A, group_B, equal_var=False)
print(f"Welch's t-test: t={t_stat_welch:.4f}, p={p_val_welch:.4f}")ANOVA
- 구성
- : i번째 집단의 j번째 관측값
- : 모든 데이터의 공통적인 기초가 되는 전체 평균(Grand Mean)
- : i번째 집단만이 가지는 고유한 효과(Treatment Effect)
- 이 값이 0이면 집단 간 차이가 없다는 뜻
- : 모델이 설명하지 못하는 무작위적인 오차(Error)
| 값 | 통계적 결정 | 의미 | 기준 |
|---|---|---|---|
| True | 귀무가설 기각 | 집단 간 평균 차이가 통계적으로 유의미함 | |
| False | 귀무가설 채택 | 집단 간 평균 차이가 통계적으로 유의미하지 않음 |
# sm.formula.ols
# sm.stats.multicomp.pairwise_tukeyhsd
# sm.datasets.get_rdataset("ToothGrowth").data
df = sm.datasets.get_rdataset("dietox", "geepack").data
df_time1 = df[df['Time']==1]
if '사전검정':
'선행확인'
if 'ANOVA':
# 모델 적합
# C()는 범주형 변수로 지정
# Cu와 Evit의 상호작용 포함, Cu와 Evit에 따른 Weight의 차이를 분석
# one-way ANOVA
model = sm.formula.ols('Weight ~ C(Cu)', data=df_time1).fit()
# anova_table = sm.stats.anova_lm(model, typ=1)
# 1이든 2든
anova_table = sm.stats.anova_lm(model)
if 'Welch ANOVA':
import pingouin as pg
# welch_anova 함수 적용 (종속변수: dv, 독립변수(집단): between)
welch_anova_results = pg.welch_anova(dv='Weight', between='Cu', data=df_time1)
# pval
# # 등분산성 위배 상황에서도 "집단 간 평균 차이가 유의하다"는 대립가설을 채택할 수 있다.
welch_anova_results['p-unc']
if '2way ANOVA':
# two-way ANOVA, 교호작용 제외
# model = sm.formula.ols('Weight ~ C(Cu) + C(Evit)', data=df_time1).fit()
# two-way ANOVA, 교호작용 포함
model = sm.formula.ols('Weight ~ C(Cu) * C(Evit)', data=df_time1).fit()
anova_table = sm.stats.anova_lm(model, typ=2) # ANOVA 테이블 생성
# two-way ANOVA, 교호작용 포함, type3
model = sm.formula.ols('Weight ~ C(Cu,Sum) * C(Evit,Sum)', data=df_time1).fit()
anova_table = sm.stats.anova_lm(model, typ=3) # ANOVA 테이블 생성
anova_table
import pandas as pd
from statsmodels.stats.anova import AnovaRM
# 데이터 예시 (Long format 가정)
# 'subject': 피험자 ID, 'time': 측정 시점(조건), 'score': 종속변수
# df = pd.DataFrame({'subject': [...], 'time': [...], 'score': [...]})
# RM ANOVA 모형 적합 및 결과 출력
# depvar: 종속변수, subject: 개체 식별자, within: 반복측정 요인 리스트
rm_anova = AnovaRM(data=df, depvar='score', subject='subject', within=['time'])
res = rm_anova.fit()
print(res.summary())
# 출력된 p-value가 유의수준(0.05)보다 작으면 귀무가설을 기각하고 사후검정을 진행한다.| sum_sq | df | F | PR(>F) | |
|---|---|---|---|---|
| Intercept | 47296.607594 | 1.0 | 3440.413940 | 1.076741e-56 |
| C(Cu, Sum) | 8.344236 | 2.0 | 0.303485 | 7.393141e-01 |
| C(Evit, Sum) | 49.359946 | 2.0 | 1.795252 | 1.744777e-01 |
| C(Cu, Sum):C(Evit, Sum) | 17.106073 | 4.0 | 0.311079 | 8.695385e-01 |
| Residual | 866.083655 | 63.0 | NaN | NaN |
-
sum 명시 필수, 아래의 상황에는 typ=3과 함께 세트로 사용:
- 문제에서 “다중 요인 간의 교호작용 유의성을 확인하고 주효과를 검정하시오”라는 요구가 있으며,
- 각 셀(Cell)의 데이터 수가 다른 불균형 설계(Unbalanced design)일 때
-
C(Cu):C(Evit) 보고 교호작용 판단 가능. pval 이 0.86 이므로 귀무가설을 기각하지 못하며 유의수준 0.05 하에서는 상호작용 효과가 없다.
-
주효과 검정도 모두 0.05 하에서 유의하지 않으므로 각 변수의 종류에 따른 Weight 차이는 없다.
교호작용 (two-way)
| 구분 | 요인 (Factor) | 귀무가설 () | 대립가설 () |
|---|---|---|---|
| 주효과 1 | Cu Effect (구리 함량) | ||
| 주효과 2 | Evit Effect (비타민 E) | ||
| 교호작용 | Cu * Evit Effect |
-
구리/비타민 수준 간 평균 차이가 없다
- 적어도 하나의 구리/비타민 수준 간 평균 차이가 있다
-
두 요인 간 상호작용 효과가 없다
- 두 요인 간 상호작용 효과가 있다
'Weight~C(Evit)+C(Cu)+C(Evit:Cu)' 구성일 때
'Weight~C(Evit)*C(Cu)' 구성일 때
-
상호작용효과 검정:
- H0: Evit 과 Cu 간에는 상호작용 효과가 없다.
- H1: Evit 과 Cu 간에는 상호작용 효과가 있다.
-
주효과 검정:
- H0: Evit 종류에 따른 Weight 차이는 존재하지 않는다.
- H1: Evit 종류에 따른 Weight 차이는 존재한다.
- H0: Cu 종류에 따른 Weight 차이는 존재하지 않는다.
- H1: Cu 종류에 따른 Weight 차이는 존재한다.
from statsmodels.graphics.factorplots import interaction_plot
import matplotlib.pyplot as plt
fig, ax=plt.subplots(figsize=(6,3))
fig = interaction_plot(
df_time1['Cu'], df_time1['Evit'], df_time1['Weight']
, markers=['D','^','o']
, ms=10
, ax=ax)
plt.show()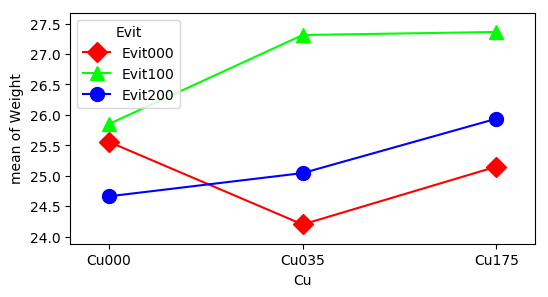
더 직관적으로 판단 위해 그래프로 해당 모델을 표현한다.
TYPE 1,2,3
| 분석 기법 | 독립변수 개수 | Type 1, 2, 3 구분 여부 | 통계적 근거 |
|---|---|---|---|
| 일원분산분석 (One-way) | 1개 | X (모두 동일) | 통제하거나 투입 순서를 나눌 다른 독립변수가 존재하지 않음 |
| 다원분산분석 (Multi-way) | 2개 이상 | O (결과 상이) | 불균형 데이터 조건에서 변수 간 비직교성(Non-orthogonality) 및 공유 분산 발생 |
| 항목 | Type I | Type II | Type III |
|---|---|---|---|
| 명칭 및 정의 | 순차적 제곱합 (Sequential SS) 모델에 변수가 입력된 순서대로 제곱합을 계산한다. 추가 후 를 추가할 때, 는 가 설명하고 남은 잔차만 설명한다. | 부분 제곱합 (Partial SS) 상호작용항(Interaction)을 무시하고, 다른 모든 주효과(Main Effect)가 포함된 상태에서 특정 주효과의 기여도를 평가한다. | 한계 제곱합 (Marginal SS) 상호작용항을 포함한 다른 모든 요인이 모델에 존재할 때 해당 요인의 순수 기여도를 평가한다. |
| 장점 | 변수의 계층적 구조나 인과적 순서가 명확할 때 논리적 타당성을 갖는다. | 주효과 검정 시 상호작용항의 간섭을 받지 않아 검정력(Power)이 높다. 순서에 영향을 받지 않는다. | 변수 입력 순서에 무관하며, 상호작용이 존재하는 불균형 데이터에서 각 효과를 독립적으로 평가할 수 있다. |
| 단점 | 변수 입력 순서에 따라 결과가 완전히 달라지므로, 순서에 대한 이론적 근거가 없으면 결과가 왜곡된다. | 상호작용항이 유의미하게 존재할 경우 주효과의 해석 자체가 무의미해질 수 있다. | 직교 대조(Orthogonal Contrast) 코딩을 사용하지 않으면 결과가 심각하게 왜곡될 수 있다. |
| 실무/ADP 적용 기준 | 다항 회귀(Polynomial)나 변수 간 우선순위가 명확히 존재할 때 사용한다. | 상호작용항이 없다고 확신하거나 유의하지 않을 때 주효과 분석용으로 주로 사용한다. | 불균형 데이터에서 상호작용항이 포함된 2원 이상의 분산분석을 수행할 때 기본값으로 사용해야 한다. |
| 특성 | Type I | Type II | Type III |
|---|---|---|---|
| 명칭 | 순차적 (Sequential) | 부분 (Partial) | 한계 (Marginal) |
| 변수 입력 순서 영향 | 받음 (O) | 안 받음 (X) | 안 받음 (X) |
| 교호작용 통제 여부 | 순차적 처리 | 통제 안 함 (교호작용 없음 가정) | 통제함 (교호작용 영향 제거) |
| 필수 코딩 방식 | 더미 코딩 무방 | 더미 코딩 무방 | 합 코딩 (Sum Contrast) 필수 |
| 필수 코딩 방식 | 다항 회귀 등 위계가 명확할 때 (거의 사용 X) | 교호작용 항의 p-value > 0.05 일 때 | 교호작용 항의 p-value < 0.05 일 때 (Sum 코딩 필수) |
Python에서 분산분석은 statsmodels.stats.anova.anova_lm을 사용한다.
주의할 점은 Type III를 계산할 때 반드시 범주형 변수의 코딩 방식을 직교 대조(Sum Contrast)로 변경해야 정확한 계산이 이루어진다는 것이다.
(기본값인 Treatment/Dummy 코딩 사용 시 오답 발생)
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
model_default = ols('Y ~ C(A) + C(B) + C(A):C(B)', data=data).fit()
# Type I (입력 순서 A -> B -> A:B에 종속됨)
anova_type1 = anova_lm(model_default, typ=1)
# Type II (상호작용항 무시하고 주효과 평가)
anova_type2 = anova_lm(model_default, typ=2)
# Type III ANOVA 실행 (ADP 핵심 포인트)
# 반드시 Sum Contrast (직교 대조 코딩)를 지정해야 Type III가 올바르게 작동함
model_type3 = ols('Y ~ C(A, Sum) + C(B, Sum) + C(A, Sum):C(B, Sum)', data=data).fit()
anova_type3 = anova_lm(model_type3, typ=3)영향을 미치는 요소가 호선, 월별의 2가지이므로 two-way.
interaction 효과 가설:
- line 과 total 사이에 교호작용이 없다.
- line 과 total 사이에 교호작용이 있다.
주효과 가설:
- line 에 따른 total 평균은 같다.
- line 에 따른 total 평균은 다르다.
- month 에 따른 total 평균은 같다.
- month 에 따른 total 평균은 다르다.
type3 검정이후)
교호작용, line, month 모두 pval 이 극히 작아 모두 H0가 기각된다.
따라서 교호작용은 존재하며, line과 month 모두 total 과 상관관계가 존재한다.
| 구분 | 수정 전 (네 서술) | 수정 후 (모범 답안) |
|---|---|---|
| 교호작용 가설 | line과 total 사이에 교호작용이 없다/있다. | line과 month 사이에 교호작용이 없다/있다. |
| 주효과 가설 | line(또는 month)에 따른 total 평균은 같다/다르다. | (수정 불필요. 단, 기호로 μ 1 =μ 2 =… 표현 시 더 전문가다움) |
| 결론 서술 (1) | 교호작용, line, month 모두 H0 기각. | 유의수준 0.05 하에서 주효과 및 교호작용의 p-value가 모두 0.05 미만이므로 귀무가설을 기각한다. |
| 결론 서술 (2) | 교호작용 존재, line과 month 모두 total과 상관관계 존재. | line과 month 간의 유의미한 교호작용이 존재하며, 두 변수 모두 total에 유의미한 주효과(평균 차이)를 미친다. |
| 결론 서술 (3) | (내용 없음) | 단, 교호작용이 존재하므로 line이 total에 미치는 영향은 month의 수준에 따라 달라진다고 해석해야 한다. |
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
from statsmodels.graphics.factorplots import interaction_plot
import matplotlib.pyplot as plt; plt.style.use('ggplot'); plt.clf()
fig, ax=plt.subplots(figsize=(6,3))
interaction_plot(df2_5_solve['month'], df2_5_solve['line'], df2_5_solve['total'], ms=10, ax=ax)
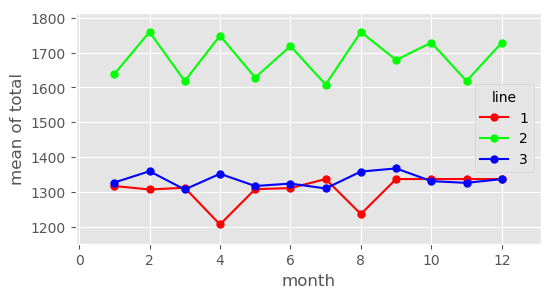
이원분산분석 플롯에서 가장 먼저, 그리고 중요하게 확인해야 할 것은 각 범주를 나타내는 선들이 평행(Parallel)한지 여부이다.
이는 월(month)이 total에 미치는 영향력의 크기와 방향이 호선(line)의 종류에 따라 달라짐을 명백히 보여준다. 따라서 앞서 서술했던 “line과 month 간에 유의미한 교호작용이 존재한다”는 통계적 가설 검정 결과를 시각적으로 완벽히 뒷받침한다.
line 2의 관측치 평균은 모든 월에 걸쳐 약 1600 ~ 1750 구간에 형성되어 있어, 1200 ~ 1400 구간에 형성된 line 1, 3과 수직적으로 뚜렷한 간격(Level shift)을 유지하고 있다. 따라서 line 변수는 total 평균에 유의미한 차이를 만드는 강력한 주효과를 가짐을 알 수 있다.
Month의 주효과 및 조건부 해석: x축(month)의 변화에 따라 y축 수치가 지속적으로 요동치고 있으므로 month 주효과 역시 유의미하게 나타났을 것이다. 단, 교호작용이 강하게 존재하므로 “몇 월에 전체 total이 높다”라고 일반화하여 해석해서는 안 되며, “line 1은 4월과 8월에 취약하지만, line 2는 동일한 월에 오히려 실적이 증가한다”와 같이 결합 조건부 해석(Conditional Interpretation) 을 수행해야 한다.
ANOVA 후속분석
-
단순한 t-test를 반복하지 않고 Tukey HSD를 사용하는 이유는 다중 비교(Multiple Comparison) 시 발생하는 제1종 오류의 누적 문제를 방지하기 위함이다.
-
Tukey 검정은 모든 가능한 쌍(Pairwise) 비교에 대해 전체 유의수준 α를 유지하도록 설계된 검정법으로, 검정 통계량 q(Studentized Range Statistic)를 사용한다.
-
meandiff + (Positive) group2의 평균이 group1보다 통계적으로 유의하게 높음
| 기법 / 개념 | 통계적 원리 및 핵심 수식 | 특성 및 적용 상황 | 장단점 및 검정력 |
|---|---|---|---|
| 다중비교의 문제점 (FWER 증가) | FWER = | 비교 횟수가 번일 때, 하나라도 1종 오류를 범할 확률(FWER)을 의미함. | 검정을 반복할수록 1종 오류 확률이 기하급수적으로 커지므로, 이를 통제하기 위한 아래의 사후검정 기법들이 필수적임. |
| Bonferroni 교정 | 가장 단순하고 범용적인 다중비교 보정법. 원래의 유의수준 를 총 비교 횟수 으로 나누어 새로운 기준을 만듦. 쌍대비교뿐만 아니라 어떤 형태의 다중검정에도 사용가능. 가장 무식하지만 확실한 방법. 원래의 유의수준 α(예: 0.05)를 총 비교 횟수 m으로 나누어 아주 엄격한 새로운 기준을 만듬. | 매우 보수적. 1종 오류는 완벽히 통제하지만, 검정력이 크게 떨어져 실제 차이를 못 찾아낼(2종 오류) 위험이 가장 큼. | |
| Holm (홀름-본페로니 절차) | -value를 오름차순 정렬() 후 순차적으로 기각 여부를 판단. k번째 검정의 유의수준을 왼쪽과 같이 유연하게 본다.기각에 실패하는 순간 검정을 멈추는 단계적(Step-down) 절차. 본페로니를 개선한 단계적(Step-down) 절차. -value를 오름차순 정렬 후 순차적으로 기각 여부 판단. | 본페로니보다 검정력이 높으면서도 1종 오류를 동일하게 잘 통제함. 최근 가장 널리 권장되는 방식. | |
| Tukey HSD | 스튜던트화 범위 분포의 기각값 를 사용해 두 집단 평균 차이의 임계치를 계산. 이 차이보다 크면 유의하다고 봄. 모든 가능한 쌍대비교(Pairwise)에 쓰이는 표준적인 사후검정 기법. | 각 집단의 표본 크기가 동일할 때 (Balanced) 최적의 검정력을 가짐. 본페로니보다는 덜 보수적이며 실무에서 가장 많이 쓰임. | |
| Scheffe (셰퍼) | 분산분석의 -분포 임계값을 조정하여 사용 | 단순 쌍대비교뿐만 아니라 복잡한 선형결합(예: A집단 vs B+C집단 평균)까지 모두 비교할 수 있는 포괄적인 방법. | 허용하는 비교 범위가 가장 넓은 만큼 가장 보수적(엄격함). 쌍대비교만 목적이라면 투키보다 검정력에서 불리함. |
import pandas as pd
if '사후분석 (Tukeys HSD)':
# sm.stats.multicomp.pairwise_tukeyhsd(종속 y, 그룹화할 독립변수 x)
# x 자체는 단독으로만 받으므로, Cu와 Evit의 조합으로 새로운 그룹화 변수를 만들어서 사용
tukey = sm.stats.multicomp.pairwise_tukeyhsd(
df_time1['Weight'], df_time1['Cu'] + ' ' + df_time1['Evit']
)
# 전체 사후분석 결과 요약표(SimpleTable)를 반환한다.
# 각 집단 쌍에 대한 평균 차이(meandiff),
# 다중비교에 의해 조정된 p-값(p-adj),
# 신뢰구간의 하한과 상한(lower, upper),
# 그리고 유의수준 α=0.05 하에서의 귀무가설 기각 여부(reject)를 보여준다.
colnames = tukey.summary().data[0]
data_rows = tukey.summary().data[1:]
if "Tukey HSD 결과":
with pd.option_context('display.max_rows', 6):
pd.DataFrame(data=data_rows, columns=colnames)
# 귀무가설 기각 여부 (True/False). True면 두 집단 간 평균 차이가 통계적으로 유의미함을 뜻한다.
tukey.reject
# FWER(Family-wise Error Rate)를 통제하기 위해 조정된 p-값.
tukey.pvalues
# 평균 차이에 대한 신뢰구간.
tukey.confint
# 두 집단 간 평균 차이의 점추정치.
tukey.meandiffs
# 각 집단의 평균과 신뢰구간을 시각화하는 메서드
# 그려진 그래프 상에서 서로의 신뢰구간(에러바)이
# 수직 선상에서 겹치지 않는 집단 간에는
# 통계적으로 유의미한 평균 차이가 있다고 직관적으로 해석할 수 있다.
tukey.plot_simultaneous()| group1 | group2 | meandiff | p-adj | lower | upper | reject | |
|---|---|---|---|---|---|---|---|
| 0 | Cu000 Evit000 | Cu000 Evit100 | 0.2929 | 1.0000 | -5.8708 | 6.4565 | False |
| 1 | Cu000 Evit000 | Cu000 Evit200 | -0.8946 | 0.9999 | -7.0583 | 5.2690 | False |
| 2 | Cu000 Evit000 | Cu035 Evit000 | -1.3571 | 0.9985 | -7.5208 | 4.8065 | False |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 33 | Cu175 Evit000 | Cu175 Evit100 | 2.2125 | 0.9550 | -3.7422 | 8.1672 | False |
| 34 | Cu175 Evit000 | Cu175 Evit200 | 0.7875 | 1.0000 | -5.1672 | 6.7422 | False |
| 35 | Cu175 Evit100 | Cu175 Evit200 | -1.4250 | 0.9973 | -7.3797 | 4.5297 | False |
36 rows × 7 columns