ddf
DDD
ANOVA 가 근본적으로 LINEAR REGRESSION 인가? 왜 STATSMODEL 에서 ANOVA 을 OLS 에서 실행하지?
ANOVA와 선형 회귀(Linear Regression)는 본질적으로 동일한 수학적 기반인 **일반 선형 모델(General Linear Model, GLM)**을 공유한다.
ANOVA는 독립변수가 범주형(Categorical)일 때 집단 간 평균 차이를 검정하는 것에 특화되어 보이지만, 내부적으로는 이 범주들을 숫자로 변환하여 회귀 분석을 수행하는 것과 같다.
statsmodels에서 ols(Ordinary Least Squares)를 먼저 실행하는 이유는 회귀 엔진을 통해 모델의 파라미터를 추정하고 오차 제곱합을 계산한 뒤, 이를 바탕으로 분산 분석표를 구성하기 때문이다.
이 관계를 더 명확히 이해하기 위해 다음 세 가지 경로를 제안한다. 함께 단계별로 파악해보자.
-
수학적 변환 원리: 범주형 데이터가 더미 변수(Dummy coding)를 통해 어떻게 회귀식으로 표현되는지 확인.
-
분산 분할의 일치성: 회귀 분석의 결정계수(R2)와 ANOVA의 F-통계량이 공유하는 전체 변동(SST) 분할 원리 비교.
-
statsmodels의 설계 방식: 왜 anova_lm 함수가 독립적인 계산기가 아니라 ols 모델 객체를 입력값으로 받는지에 대한 구현 논리.
오해에 대한 정정
네가 착각하고 있는 부분이 있다. statsmodels에서 QuantReg(분위수 회귀)라고 해서 기본적으로 절편(intercept)이 추가되는 특혜가 있는 것이 아니다. OLS와 QuantReg는 절편 추가에 대해 완전히 동일한 규칙을 따른다.
결론부터 말하자면, 네가 OLS 모형은 **배열 기반 API(statsmodels.api.OLS)**로 작성했고, QuantReg 모형은 **포뮬러 기반 API(statsmodels.formula.api.quantreg)**로 작성하여 두 API 간의 기본 설정 차이를 모형 자체의 특성 차이로 오인했을 가능성이 매우 높다.
statsmodels의 두 가지 API와 절편(Intercept) 처리 방식
statsmodels는 R 스타일의 포뮬러를 사용하는 방식과, NumPy 또는 Pandas 배열을 직접 입력하는 두 가지 API를 제공한다. 이 둘은 독립변수 행렬(Design Matrix)을 구성할 때 절편 처리 기본값이 다르다.
- 배열 기반 API (statsmodels.api)
특징: 모형에 넣을 독립변수 행렬 X를 있는 그대로 받아들인다.
절편 규칙: OLS, QuantReg, GLM, WLS 등 모든 통계 모형에서 기본적으로 절편을 포함하지 않는다. 절편 추정을 위해서는 반드시 모델 훈련 전에 사용자가 직접 sm.add_constant(X)를 통해 X 행렬의 좌측에 1로 가득 찬 상수항 열(column)을 수동으로 추가해야 한다.
- 포뮬러 기반 API (statsmodels.formula.api)
특징: 데이터프레임과 함께 ‘y ~ x’ 형태의 문자열 포뮬러를 입력받는다.
절편 규칙: 내부적으로 patsy 패키지를 사용하여 독립변수 행렬을 파싱 및 구성하는데, 이때 R 언어의 기본 동작 방식과 동일하게 절편(상수항)이 자동으로 추가된다. 따라서 add_constant 과정이 필요 없다. 만약 강제로 절편을 빼고 원점을 지나는 회귀를 하려면 포뮬러에 - 1 또는 + 0을 명시해야 한다 (예: ‘y ~ x - 1’).
Q. A 샘플의 다항분포 비율이 모비율을 따르고 있는지 확인
A. 특정 샘플(A 샘플)이 여러 개의 범주(3개 이상)로 나뉘는 다항분포(Multinomial Distribution) 데이터를 가지고 있을 때, 이 샘플의 범주별 비율이 우리가 알고 있는(혹은 가정한) 전체 모비율(Population Proportion)과 일치하는지 확인하려면 **‘카이제곱 적합도 검정(Chi-Square Goodness-of-Fit Test)‘**을 사용
-
귀무가설 (): A 샘플의 범주별 비율은 전체 모비율과 같다. (기대했던 비율을 잘 따르고 있다)
-
대립가설 (): A 샘플의 범주별 비율은 전체 모비율과 다르다. (적어도 하나의 범주에서는 비율이 어긋난다)
검정에 사용하는 데이터는 반드시 비율(0.5, 0.3…)이나 백분율(50%, 30%…)이 아닌 **절대적인 빈도수(Count, 명/건수)**여야 합니다.
모든 범주의 ‘기대 빈도’는 최소 5 이상이어야 검정 결과가 신뢰성을 가집니다. 기대 빈도가 5 미만인 범주가 많다면, 비슷한 범주끼리 묶어주는 전처리가 필요합니다.
💡 추가: 왜 자유도가 (범주 수 - 1) 인가요?
범주가 개인 다항분포로 확장해도 원리는 똑같습니다. 단지 처럼 확장될 뿐입니다.
그런데 왜 자유도(Degree of Freedom)는 가 아니라 일까요?
총 데이터 개수()가 정해져 있기 때문에, 마지막 1개 범주의 빈도는 우리가 계산하지 않아도 자동으로 결정되기 때문입니다. (예: 100명 중 A가 30명, B가 50명이면 C는 무조건 20명).
Q. sum[(o-e)^2/e] 가 왜 카이제곱 분포를 따르지?
대답 생성 완료
Gemini가 대답함
A. 이 질문은 통계학의 근본적인 원리를 파고드는 아주 훌륭한 질문입니다!
라는 공식이 갑자기 하늘에서 뚝 떨어진 것 같지만, 사실 이 공식은 통계학의 가장 아름다운 연결 고리 중 하나인 **“정규분포(Normal Distribution)와의 관계”**를 증명한 결과물입니다. (1900년 칼 피어슨이 증명했습니다.)
**카이제곱 분포는 사실 “표준정규분포()를 제곱해서 더한 것”**입니다.
즉, 우리가 증명해야 할 것은 라는 식이 결국 과 똑같다는 것을 보여주는 것입니다.
어떤 사건이 범주 1(예: 앞면)과 범주 2(예: 뒷면)로 나뉜다고 해봅시다. 총 번을 던졌습니다.
자, 이제 질문하신 카이제곱 공식을 범주 1과 범주 2에 대해 써보겠습니다.
범주 2의 분자 부분인 를 변형해 봅시다.
관측값에서 평균을 빼고 분산으로 나누는 것(표준편차로 나눈 후 제곱하는 것). 바로 데이터를 표준정규분포(Z)로 바꾸는 ‘표준화(Standardization)’ 공식의 제곱입니다!
2항분포에서 3항분포(범주가 3개)로 넘어가면, 단순한 을 넘어 통계학과 선형대수학이 만나는 진짜 마법, 즉 **‘공분산(Covariance)‘과 ‘다변량 정규분포’**의 개념이 등장합니다.
3항분포에서 유도된 피어슨의 공식 이 카이제곱 분포를 따르는 진짜 이유는 이렇습니다.
공식 자체만 보면 3개의 분수가 얽혀 있는 것 같지만,
실제로는 그 안에 “서로 영향을 주지 않는(독립적인) 2개의 순차적 사건()“에 대한 확률 계산이 완벽하게 숨어 있기 때문입니다.
피어슨의 위대한 업적은, 복잡한 조건부 정규분포()를 일일이 계산할 필요 없이, 관측치()와 기대치()만 알면 초등학생도 덧셈 뺄셈으로 계산할 수 있도록 식을 극도로 단순화(약분)해 낸 것입니다.
카이 분포는 분명히 존재하며, **“정규분포 오차들이 만들어내는 실제 직선 거리”**를 의미합니다. 차원에 따라 레일리 분포, 맥스웰-볼츠만 분포라는 멋진 이름으로 물리학과 공학을 지배하고 있지만, 계산의 편의를 추구하는 통계학자들의 취향(?) 때문에 통계학에서는 루트를 벗어던진 ‘카이제곱’에게 스포트라이트를 양보한 셈입니다.
chaper 01 마케팅과학을 위한 통계분석 1.1 마케팅의 변화 1.2 마케팅과 통계 1.3 마케팅을 위한 통계분석 기법 [1] 기초 통계분석 기법 [2] 인과관계 분석기법 [3] 기타 다변량 통계분석 기법 1.4 통계분석을 활용한 문제해결 과정 [1] 문제파악 및 가설 수립 [2] 유의수준 및 임계치 설정 [3] 분석 및 검정 통계량 산출 [4] 결과 해석 및 가설 검증
chapter 02 확률통계개론 2.1 확률기초이론 [1] 확률 [2] 확률변수와 확률분포 2.2 통계기초이론 [1] 통계학 [2] 추정 [3] 가설검정
chapter 03 파이썬 기초 3.1 파이썬 소개 [1] 왜 파이썬인가? [2] Anaconda python 실습 환경 구축 3.2 파이썬 프로그램 기초 [1] 파이썬의 자료형 [2] 파이썬 제어문 3.3 데이터 분석을 위한 파이썬 라이브러리 [1] 통계분석을 위한 라이브러리 [2] Numpy [3] Pandas
chapter 04 데이터 전처리 및 기초분석 4.1 분석을 위한 데이터 준비 [1] 실습용 데이터 다운로드 [2] 분석 데이터 설명 [3] 데이터 불러오기 4.2 데이터 전처리 및 파생변수 생성 [1] 데이터 전처리 [2] 파생변수의 생성 4.3 유용한 통계 그래프 [1] 히스토그램 [2] 산점도 [3] 파이차트 [4] 상자그림
chapter 05 기술통계분석 5.1 평균, 분산, 표준편차 [1] 개념 및 주요 이론 [2] 분석 및 해석 5.2 왜도와 첨도 [1] 개념 및 주요 이론 [2] 분석 및 해석 5.3 기타 기술통계량 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 06 t-검정 6.1 t-검정 기초 6.2 일표본 t-검정 [1] 개념 및 주요 이론 [2] 분석 및 해석 6.3 독립표본 t-검정 [1] 개념 및 주요 이론 [2] 분석 및 해석 6.4 쌍체표본 t-검정 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 07 상관관계 분석 7.1 수치형 변수의 상관관계 분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 7.2 편(부분) 상관관계 분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 7.3 순서형 변수의 상관관계 분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 7.4 정준상관분석 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 08 범주형 데이터 분석 8.1 적합도 검정 [1] 개념 및 주요 이론 [2] 분석 및 해석 8.2 독립성 검정 [1] 개념 및 주요 이론 [2] 분석 및 해석 8.3 동질성 검정 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 09 신뢰성 분석 9.1 신뢰성과 타당성 [1] 측정오차 [2] 신뢰성 [3] 타당성 9.2 내적일관성 분석 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 10 분산분석 10.1 분산분석 기초 [1] 분산분석의 종류 10.2 일원분산분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 10.3 이원분산분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 10.4 다변량분산분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 10.5 공분산분석 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 11 회귀분석 11.1 회귀분석 기초 11.2 단순회귀분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 11.3 다중회귀분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 11.4 더미변수를 이용한 회귀분석 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 12 요인 분석 12.1 요인분석 기초 [1] 요인추출방법 [2] 요인 분석의 주요지표 [3] 요인의 회전 [4] 요인분석의 유형 12.2 탐색적 요인분석 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 13 분류예측분석 13.1 분류예측분석 기초 13.2 선형판별분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 13.3 로지스틱 회귀분석 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 14 군집분석 14.1 군집분석 기초 14.2 계층적 군집분석 [1] 개념 및 주요 이론 [2] 분석 및 해석 14.3 비계층적 군집분석 [1] 개념 및 주요 이론 [2] 분석 및 해석
chaper 15 포지셔닝 분석 15.1 포지셔닝 분석 기초 15.2 다차원 척도법 [1] 개념 및 주요 이론 [2] 분석 및 해석 15.3 상응분석 [1] 개념 및 주요 이론 [2] 분석 및 해석
chapter 16 컨조인트 분석 16.1 개념 및 주요 이론 16.2 컨조인트 분석을 위한 조사 및 분석 과정 16.3 시장점유율 예측 16.4 분석 및 해석
chapter 17 비모수 통계분석 17.1 비모수 통계분석 기초 17.2 적합도 검정 [1] RUN 검정 [2] Kolmogorov-Smirnov 검정 (단일표본) 17.3 동질성 검정 [1] Wilcoxon 부호-순위 검정 [2] Mann-Whitney U 검정 [3] Kruskal-Wallis H 검정 [4] Friedman 검정 17.4 상관성 검정 [1] Kendall 서열상관 분석
3-2번의 모델 결과에 대해 X뒤의 숫자가 가장 낮은 컬럼이 5단위 늘어나면 오즈비 몇 배로 변화?
주어진 Dataset에서 CRIM값이 가장 큰 10개의 지역을 구하고
10개의 지역의 CRIM값을 그 중 가장 작은 값으로 대체하라. 그리고
AGE 컬럼 값이 80이상인 대체 된 CRIM 평균값을 구하라
주어진 Dataset의 DIS 평균으로 부터 1.5 * 표준편차를 벗어나는 영역을 이상치라고 판단하고
DIS 컬럼의 이상치들의 합을 구하여라.
조사결과 70%의 성인 남성이 3년 동안에 적어도 1번 치과를 찾는다고 할때, 21명의 성인 남성이 임의로 추출되었다고 하자.
3-2 - a
21명 중 16명 미만이 치과를 찾았을 확률(반올림하여 소숫점 이하 3자리)
적어도 19명이 치과를 찾았을 확률(반올림하여 소숫점 이하 3자리)
df = df.dropna().reset_index(drop=True) df_filter = df.iloc[:int(len(df)*0.7)] result = df_filter[‘median_income’].quantile(0.25).round(2) print(result)
import pandas as pd
df =pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/krdatacertificate/e3_p1_2.csv')
df.head()
df['Value']
# df.query('Year>=1990 and Year<2000').
# Index.intersection() 메서드를 사용하거나 numpy.intersect1d 함수를 활용한다.
# 두 DataFrame 간의 공통 컬럼명을 추출할 때는 columns 속성에 intersection()을 적용한다.
# pd.Index.intersection(
# df.query(f'''Year==1990 and Value<={df.query('Year==1990')['Value'].mean()}''').index
# ,
# df.query(f'''Year==2010 and Value>={df.query('Year==2010')['Value'].mean()}''').index
# )
df.query(f'''Year==1990 and Value<={df.query('Year==1990')['Value'].mean()}''')
df.query(f'''Year==2010 and Value>={df.query('Year==2010')['Value'].mean()}''')
1. intersection() 메서드 사용
result1 = set1.intersection(set2)
2. & 연산자 사용
앰퍼샌드(&) 연산자를 사용하면 수식처럼 직관적으로 교집합을 구할 수 있다. 단, 이 기호를 사용할 때는 연산자의 양쪽 항이 모두 반드시 set 자료형이어야 한다.
result1 = set1 & set2
대응 표본 t 검정을 통해 B공장 제품들의 rpm이 A 공장 제품의 rpm보다 크다고 말할 수 있는지 검정하라. pvalue를 소숫점 이하 3자리까지 출력하고 귀무가설, 대립가설 중 하나를 출력하라*
Attention
어느 학교에서 수학 시험을 본 학생 100명 중 60명이 60점 이상을 받았다. 이 학교의 수학 시험의 평균 점수가 50점 이상인지 95%의 신뢰 수준에서 검정하려한다.
3-1-a
**검정 통계량을 소숫점 이하 3자리에서 구하시오**
Hide code cell source
import numpy as np
n = 100
p_hat = 0.6
p = 0.5
alpha = 0.05
# 검정 통계량 계산
z = round((p_hat - p) / np.sqrt(p * (1 - p) / n),5)
print(z)
2.0
3-1-b
**pvalue를 소숫점 이하 3자리까지 구하고 귀무가설과 대립가설중 유의한 것을 출력하라**
Hide code cell source
from scipy.stats import norm
p_value = round(1 - norm.cdf(z),3)
print(p_value)
print('대립')
0.023
대립
import pandas as pd
import numpy as np
# 데이터프레임 예시
df = pd.DataFrame({'col1': ['1', '2', 'invalid', '4']})
# pd.to_numeric을 사용한 형변환
df['col1'] = pd.to_numeric(df['col1'], errors='coerce')
# 'abc123def' -> '123'
df['col2'] = df['col1'].str.replace(r'[^0-9]', '', regex=True)
# '가격: 5000원' -> '5000'
df['col2'] = df['col1'].str.extract(r'(\d+)')
Hide code cell source
from scipy.stats import binom
n = 21 p = 0.7 k = 16
P(X < k) 계산
prob = binom.cdf(k-1, n, p) print(round(prob, 3))
0.637
3-2 - b
Hide code cell source
from scipy.stats import binom
n = 21 p = 0.7 k = 19
P(X >= k) 계산
prob = 1 - binom.cdf(k-1, n, p) print(round(prob, 3))
0.027
개인적으로 저는 식이 제공이 되었기 때문에 2번이 구현 난이도가 그리 높지는 않았다고 생각합니다…! 다만 평소와 결이 많이 다르긴 하네요 ㅠ
평소에는 불균형 관련 질문이 많이 나왔던 거 같은데 1번이 클래스 비율 1:2 정도였는데도 불구하고 이번엔 하나도 없어서 놀랐습니다
시계열에서 ARIMA 까지는 준비해갔는데 STL은 패키지를 적어가지 않았어서 어떻게 임포트하는지 찾느라 한참 걸렸네요 로지스틱 회귀도 적어간 코드가 버전 문제인지는 몰라도 작동을 안해서 어렵게 찾아 겨우겨우 했습니다…
1번이든 2번이든 저는 성능이 그리 높지 않았는데 (물론 제 문제일수도 있음) 둘 다 성능으로 평가하는 게 아니라 분석 위주로 보는 거 같아서 하이퍼파라미터 탐색은 아예 안 하고 분석 위주로 보고서 작성에 좀 더 힘을 썼습니다
이번에 떨어지면 필기를 다시 쳐야 하는지라 ㅠㅠ 붙으면 좋겠지만 4번을 거의 날려서 아쉽네요…
1번 (비행기 지연 데이터, train.csv와 test.csv 제공)
-
결측치 찾고 어떻게 처리했는지 설명
-
지연시간 기준으로 지연여부 변수 생성, 빈도표
-
EDA 진행 (연속형 변수와 범주형 변수 어떤 거 있는지, 종속변수-독립변수 간 독립성, 독립변수-독립변수 간 독립성)
-
EDA 기반으로 종속변수에 가장 영향 미칠 변수 연속형에서 세 개, 범주형에서 세 개
-
변수를 적절히 처리하고(처리 안하면 왜 안했는지 설명) 단일 모델 하나, 앙상블 모델 하나 학습 후 성능지표 두 가지 이상 리포트, 변수 중요도 설명
-
test.csv에 train과 똑같이 전처리 진행한 후 성능지표 두 가지 이상 리포트
2번
전처리 (배점 표기 x, 부분점수 없는듯함)
-
passenger, weather, air 세 개의 csv 존재
-
passenger에서 승차고객과 하차고객 합치고(counts) 시간축이 column으로 펼쳐져 있던 거를 row로 되도록 변환
-
weather는 네 개의 관측소에서 측정한 시간대별 지표(온도, 습도 등) 존재
-
passenger의 지하철역 위도/경도와 weather의 위도/경도 이용해서 haversine distance 계산 (문제에서 식 제공)
-
distance 기반으로 inverse distance weight 사용해서 지하철역에 시간대별 지표 추가 (문제에서 식 제공)
-
air와 merge해서 air_quality를 y로 사용
-
22년은 train, 23년은 test로 split
-
전처리된 데이터(counts, 날씨 지표)에 대해, 결측치가 있다면 직전 시간대의 값으로 채우고 기초통계량 리포트 후 분석
-
학습 데이터에서 air_quality 따라 counts, 날씨 지표에 차이가 있는지 통계 검정
-
분류 모델 학습 후 평가 데이터로 성능 뽑고 분석
3번 시계열
-
Sales 열에 대해 STL (Trend, Seasonal, Remainder)
-
F_s, F_t (계절성, 추세성) 계산 (문제에서 식 제공)
-
Remainder에서 이상치를 IQR 기준 / z 기준 둘 다 해서 겹치는 데이터 찾기
-
겹치는 데이터에 대해서 flag(event, holiday 등) 보고 왜 이상치가 되었을지 분석
4번 로지스틱 회귀
-
로지스틱 회귀를 위한 귀무가설, 대립가설 세우고 검정
-
VIF
-
유의한 변수 중 가장 영향 많이 끼친 변수 찾고, 오즈비 보고 어떻게 영향을 끼치는지
-
ROC 그리고 AUC
Data Scientist PhD
공유 감사합니다. 2번 문제 merge 할 때 어떤 컬럼으로 하셨나요?
2025.10.18. 19:48 답글쓰기
프로필 사진 왜옹 저는 date과 st_nm으로 했습니다!
2025.10.18. 20:07 답글쓰기
1 프로필 사진 wyiiw 공유 감사합니다~ 1-5번 문제에 성능 지표 2가지 이상 리포트 하라는 것은 기억나는데 변수 중요도도 출력하라고 있었나요?
2025.10.21. 13:33 답글쓰기
프로필 사진 왜옹 넵 분석 조건에 명시되어있었습니다!
2025.10.21. 13:34 답글쓰기
프로필 사진 Data Scientist PhD 저도 성능 지표 2가지 이상 비교하라는 건 기억나느데 변수 중요도 출력은 보지 못했거나 기억이 나지 않거나겠네요
2025.10.21. 22:53 답글쓰기
프로필 사진 wyiiw 저도 그렇네요, 어지간했으면 보였을텐데.. 문구가 작게 있었던건지 모르겠네요. 저도 기억하는게 1-5, 1-6번 마지막 문장이 성능지표로 비교 확인하라는 내용이었어요.
2025.10.21. 22:56 답글쓰기
프로필 사진 Data Scientist PhD wyiiw 제가 문제를 전부 타자치면서 다 적거든요. 변수중요도 문구 자체를 친 기억이 없습니다.
EDA 결과로 1-4에 종속변수에 영향을 미치는 변수 3개씩 고르는 건 기억 납니다.
2025.10.21. 22:57 답글쓰기
프로필 사진 왜옹 Data Scientist PhD 제 기억상 문제 하단의 네모박스?부분에 성능지표 두 가지랑 같이 있었습니다! 제가 1.6에 중요도 적었다가 문제 보고 1.5로 넘겼던 기억이 나네요
2025.10.21. 23:15 답글쓰기
프로필 사진 wyiiw Data Scientist PhD 그러시군요, 제가 밑에 네모박스를 제대로 못 본 것일수도 있겠네요.. Data Scientist PhD 님도 혹시 밑에 네모박스 기억나세요?
2025.10.22. 08:38 답글쓰기
프로필 사진 월급쟁이1인 문제를 다 기억하시는 게 정말 놀랍네요!!!
2025.11.09. 14:35 답글쓰기
| 알고리즘 | 기반 알고리즘 | 계절성 가정 | 이상치 강건성 | 양 끝단 / 결측치 처리 | 가법 / 승법 지원 | Python 구현체 |
|---|---|---|---|---|---|---|
| Classical | 단순 이동평균 (Moving Average) | 시간에 따라 변하지 않음 (고정) | 취약함 | 양 끝단 데이터 손실 (NaN 발생) | 가법, 승법 모두 지원 | statsmodels.tsa.seasonal.seasonal_decompose |
| X-11 | 반복적 이동평균 및 헨더슨(Henderson) 필터 | 시간에 따라 서서히 변함을 허용 | 강건함 (이상치 가중치 조절) | 양 끝단 추정 가능 (ARIMA 연장 활용) | 가법, 승법, 유사-가법(Pseudo-additive) 지원 | statsmodels.tsa.x13.x13_arima_analysis (외부 바이너리 필요) |
| SEATS | ARIMA 모형 기반 신호 추출 (Signal Extraction) | ARIMA 모형에 기반한 확률적 변화 | 매우 강건함 (내부 이상치 탐지) | ARIMA 예측을 통해 양 끝단 완벽 추정 | 가법, 승법 지원 | statsmodels.tsa.x13.x13_arima_analysis (외부 바이너리 필요) |
| STL | 국소 회귀 (LOESS) 반복 연산 | 하이퍼파라미터 조절로 동적 변화 허용 | 매우 강건함 (robust=True 옵션) | 양 끝단 모두 추정 (NaN 없음) | 가법 모형만 지원 (승법은 로그 변환 필요) | statsmodels.tsa.seasonal.STL |
| 구분 | KM | NA | Cox (NA와 연관) | AFT (KM과 연관) |
|---|---|---|---|---|
| 모델 유형 | 비모수적 | 비모수적 | 준모수적, 위험 (Hazard) 중심 | 모수적, 생존 시간 (Time) 중심 |
| 특정 분포를 가정하지 않음 | 특정 분포를 가정하지 않음 | 기저 위험을 가정하지 않음 | 특정 수명 (확률) 분포를 가정 | |
| 비례위험 가정 충족 필수 | 가속수명 가정 | |||
| 본질 | 관측된 데이터의 통계적 요약, 관측된 시점에서의 계단식 변화 | 데이터를 설명하는 수학적 함수(모델) | ||
| 역할 | 기준점 (Benchmark) | 예측 및 요인 분석 (Prediction) | ||
| 요약 | ”현실이 이러하다" | "어떤 요인(변수) 이 생존에 영향을 미치는가?" | "이 공식(AFT)으로 그 현실(KM)을 재현할 수 있는가?" | |
| "시간에 따라 생존할 확률은?" | "시간에 따라 위험이 얼마나 누적되는가?" | "A 약물 투여 시 사망 위험이 0.5배로 감소한다." | "A 약물 투여 시 생존 시간이 2배로 연장된다.” | |
| 주요 산출물 | 계단식 생존 곡선 그래프, Log-rank 검정 -value | 각 변수별 위험비(HR), 회귀 계수() | 가속 인자 (AF) | |
| 추정 대상 | 생존 함수 | 누적 위험 함수 | 위험비 (HR) | |
| 핵심 수식 | ||||
| 주요 목적 | 시점별 생존 확률 추정 및 군간 비교 | 위험의 누적 속도 및 패턴 파악 (특정 시점에 누적된 위험의 총량) | 공변량(Covariates)의 영향력 분석 | |
| 특정 그룹의 시간에 따른 생존 확률 추정 및 직관적 시각화 | 다중 변수가 사건 발생 위험(Hazard)에 미치는 영향력 수치화 | |||
| 분석 차원 | 단일 변수 분석 (Univariate) | 다중 변수 분석 (Multivariate) | ||
| 단변량, 범주형 변수 1개만 가능 (성별, 투약군 등) | 단변량 | 연속형, 범주형 모두 동시 투입 가능 (나이, 혈압 등) | 다변량 (연속형, 범주형 모두 가능) | |
| 단일/그룹 변수 비교 (logrank 사용) | 위험률의 시간적 변화 관찰에 유리 | 다변량 분석 가능 (기저 위험 가정 ×) | 다변량 (연속형, 범주형 모두 가능) | |
| 상호 관계 | (to NA) | Cox 모델의 기저 위험 추정 시 활용됨 | 차이 확인 (by KM) 후 요인 분석 (by Cox) | |
| 실무 분석 단계 | EDA 및 전체/그룹별 생존 트렌드 파악 | Cox 모형의 기저 위험 추정 및 잔차 진단 | 주요 요인 도출 및 생존 위험도 예측 | 특정 조건 하의 기대 생존 시간(Expected Time) 직접 예측 |
| 검증 방법 | logrank | 생존 곡선의 점근적 신뢰구간 계산 시 활용 | Wald test, Likelihood ratio test | AIC, 잔차 분석 (residuak), KM 곡선과 겹쳐 그리기 |
| 함수명 | 용도 및 핵심 개념 | 주요 사용 상황 (시험 대응) | |
|---|---|---|---|
sklearn.metrics | confusion_matrix | 예측 결과와 실제 값을 교차 표로 정리 | 오분류의 양상(FP, FN 중 어디에 치우쳤는지) 파악 |
| accuracy_score | 전체 중 맞춘 비율 | 클래스 분포가 균형 잡힌 데이터의 기본 평가 | |
| precision_score | 양성 예측 중 실제 양성 비율 | **Type I Error(FP)**를 낮추는 것이 중요할 때 (스팸 분류 등) | |
| recall_score | 실제 양성 중 양성 예측 비율 | **Type II Error(FN)**를 낮추는 것이 중요할 때 (암 진단 등) | |
| f1_score | 정밀도와 재현율의 조화 평균 | 클래스 불균형이 심할 때 모델의 전반적인 성능 평가 | |
| classification_report | 주요 지표를 한 번에 문자열로 반환 | 전반적인 성능을 일목요연하게 보고서 형태로 출력 | |
| roc_curve | 임계값 변화에 따른 TPR, FPR 변화량 | 최적의 임계값(Threshold)을 찾기 위한 시각화 기초 자료 | |
| roc_auc_score | ROC 곡선 아래 면적 | 모델의 변별력(Discrimination)을 단일 수치로 평가 | |
| auc | 주어진 곡선 아래 면적 계산 | roc_curve 등으로 구한 x, y 좌표를 바탕으로 면적 산출 | |
| predict_proba | 클래스별 예측 확률값 반환 | AUC 계산 및 임계값 조정 시 필수 데이터 추출 |
이번 포스팅에서는 10월 18일에 시행된 ADP 35회 실기 시험 복기를 해볼 것이다.
https://blog.naver.com/xoosl0331/224056804000
9월엔 토익스피킹, 10월 연휴 + IBK기업은행 필기시험과 ADP 실기시험이 날짜가 동일한 날에 봐서 ADP 준비를 거의 못하고 갔더니 시험을 아주 죽쓰고왔다.
그래서 다음 36회를 대비해서 이번 35회 시험 복기 겸 앞으로 계획을 포스팅 해보겠다.
머신러닝 파트
이번 머신러닝 파트에는 2문제가 나왔다.
1번 (비행기 지연 데이터)
데이터 변수는 19개, train 데이터 3만개 test 데이터 1만개 정도 있었다.
- 결측치 찾고 어떻게 처리했는지 설명
-
변수 3개인가 결측치가 존재했는데 몇개 되지도 않는 결측치였다. 그 중 2개 변수의 결측치는 동일한 데이터에 결측치가 발생했었고 1개는 안그랬다.
-
결측치 데이터들의 분포를 봤을 때 한쪽으로 치우쳐진 분포였어서 중앙값으로 대치해줬다.
- 지연시간 기준으로 지연여부 변수 생성, 빈도표
-
지연 시간 0.5보다 크면 1 아니면 0으로 해서 변수를 만들어주고 table 함수로 빈도표 생성해주면 되는 간단한 문제였다.
-
비율이 1:2정도 였으며 이 변수가 종속변수로 쓰인다.
- EDA 진행 (연속형 변수와 범주형 변수 어떤 거 있는지, 종속변수-독립변수 간 독립성, 독립변수-독립변수 간 독립성)
-
데이터 개수가 많아서 GGally 패키지 함수들은 사용하지 못하고 일일히 변수끼리 분포를 살펴보았다.
-
범주형 변수와 연속형 변수의 개수는 거의 반반이였는데 범주형 변수는 클래스 불균형은 심하진 않았고 요인의 개수도 엄청 많거나 그렇지는 않았다.
-
연속형 변수는 대부분이 한쪽으로 치우쳐진 분포를 가지고 있었으며 변환을 해도 크게 나아지는 건 없었고 상관계수가 높은 변수 조합이 2개인가 있었어서 PCA 2개 만들어서 차원축소를 해주었다.
- EDA 기반으로 종속변수에 가장 영향 미칠 변수 연속형에서 세 개, 범주형에서 세 개
-
이건 그냥 종속 변수와 연속형 변수는 box plot 만들어서 차이 많이 나는거 3개 썼고
-
범주형 변수는 chisq 검정해서 p-value 가장 낮은거 썻다
- 변수를 적절히 처리하고(처리 안하면 왜 안했는지 설명) 단일 모델 하나, 앙상블 모델 하나 학습 후 성능지표 두 가지 이상 리포트, 변수 중요도 설명
-
연속형 변수들은 표준화 변환을 하고 pca 2개 만든 것 빼고는 다른 변환은 딱히 안했던 것 같다.
-
모형은 random forest와 svm을 사용하려고 했는데 하이퍼파라미터 튜닝은 데이터 개수가 많아서 무리인 것 같아 cross validation으로 모형 평가를 했다.
-
근데 random forest만 해도 20분이 지나도록 모형 적합이 안되어서 포기했고 svm의 경우에는 변수 중요도를 사용하지 못하기 때문에 시간 문제로 logistic reg로 바꿔서 다시 모형 적합해서 결과를 냈다.
-
f1 score랑 auc, accuracy로 성능평가 했는데 성능이 매우 안좋았 던것으로 기억한다.
- test.csv에 train과 똑같이 전처리 진행한 후 성능지표 두 가지 이상 리포트
- 적합된 모형으로 test 데이터에 대한 예측을 해봤는데 과적합은 안나왔다.
변수 개수가 너무 많고 데이터가 3만개정도 되다보니 시험장 환경으로는 하이퍼파라미터 튜닝이나 cross validation은 무리 인 것 같다.
문제에서 하이퍼파라미터 튜닝하라고 쓰여있는 것 아니면 그냥 train 데이터를 train, validation으로 나누고 빠르게 모형 만든 다음에 문제 푸는게 나은 것 같다.
2번 시간 문제로 데이터 구경도 못해보고 시험장을 나옴..
전처리 (배점 표기 x, 부분점수 없는듯함)
-
passenger, weather, air 세 개의 csv
-
passenger에서 승차고객과 하차고객 합치고(counts) 시간축이 column으로 펼쳐져 있던 거를 row로 되도록 변환, 결측치는 직전 값으로 채우라고 되어있었 던거 같음.
-
weather는 네 개의 관측소에서 측정한 시간대별 지표(온도, 습도 등) 존재
-
passenger의 지하철역 위도/경도와 weather의 위도/경도 이용해서 하버사인 거리 계산 (문제에서 식 제공해주는데 찾아보니 패키지로도 사용가능한 듯)
-
distance 기반으로 inverse distance weight 사용해서 지하철역에 시간대별 지표 추가 (문제에서 식 제공)
-
air와 merge해서 air_quality를 y로 사용
-
22년은 train, 23년은 test로 split
시간이 있었어도 전처리 하느라 시간 다 썼겠지만 사람들이 너무 어려운 문제였다고 함.. 수학 풀러온 것 같다고
나는 구경도 못해봤으니.. 쩝..
통계파트
3번,4번 문제는 통계파트 문제이다. 머신러닝 2번 문제가 엄청 어렵게 출제가 되서 그런지 통계파트 문제가 쉽게 출제 되었다. (근데 3번은 거의 못풀었다.)
3번 시계열문제가 출제되었다.
기억 상 여러개의 변수가 있었으며 주기를 7로 하는 시계열 데이터라고 문제에 명시되어있었다.
- Sales 열에 대해 STL 분해 후 분석하기(추세, 계절성, 잔차)
-
1번은 stl 분해 그래프만 출력하면 쉽게 풀 수 있는 문제였다.
-
처음에 데이터를 불러오고 ts 객체로 만들어 stl 함수로 분해하려했는데 자꾸 오류가 나서 timetk 패키지의 plot_stl_diagnotics() 함수를 이용해서 그래프를 그리고 분석해주었다.
-
추세가 굉장히 강했으며 계절성이 뚜렷한 그래프였고 잔차를 보았을 때 이상치가 많은 데이터였다.
- F_s, F_t (계절성, 추세성 강도) 계산
- 문제에서 식이 제공되었고 계절성과 추세성의 강도를 측정하는 문제였다.
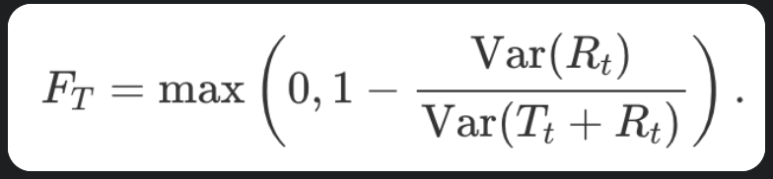
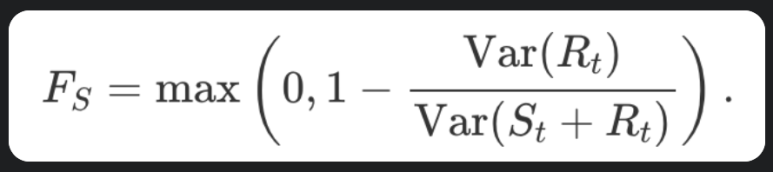
식이 대충 이러했는데 이런걸 배운적이 없어서 못풀었다.
구글에 찾아보니 feasts 패키지의 feat_stl 함수를 이용하면 된다고하는데 나중에 포스팅 해보겠다.
- Remainder에서 이상치를 IQR 기준 / z 기준 둘 다 해서 겹치는 데이터 찾기
-
시계열에서 잔차 추출 후 이상치를 찾아내는 문제이다. 시험 당시에 잔차를 추출하는 방법을 생각하지 못했는데 찾아보니 stl 분해 후에 거기서 객체뽑아낸다음 식에 맞게 추출하면 되는 문제였다.
-
그래서 못풀었다.
-
tk_stl_diagnotics 에서 reminder를 뽑아내서 분석하면 풀 수 있었을 것 같다.
- 겹치는 데이터에 대해서 flag(event, holiday 등) 보고 왜 이상치가 되었을지 분석
- 2,3번을 못푸니 4번도 못풀었다. flag에 해당하는 것은 데이터에 변수명이다.
4번 로지스틱 회귀
4번 문제는 기본적인 회귀분석이였다. 변수의 개수도 적당했어서 크게 어려운 것은 없었던 것 같다.
로지스틱 회귀분석을 만들라고 4번 문제에 명시되어 있었고 후속 문제 4가지가 있었다.
- 로지스틱 회귀에 영향을 미치는 유의한 변수를 찾기 위한 귀무가설, 대립가설 세우고 검정
-
적합 된 로지스틱 회귀모형을 이용해서 유의한 변수를 찾기 위한 귀무가설 대립가설을 세우고 검정하는 문제였다.
-
로지스틱 회귀계수는 z 검정을 통하여 수행되는데 범주형 변수가 제법 많았어서 모형을 적합하니 변수가 15개가 넘어갔던 것으로 기억하고 유의한 변수 절반 유의하지 않은 변수가 절반이였다.
-
유의한 변수, 유의하지 않은 변수를 나눠서 결과를 작성했다.
-
데이터는 따로 나누지 않았고 tidymodels logistic_reg() 함수를 이용해서 모형을 만들었다.
- VIF
-
이건 car 패키지의 vif 함수를 이용하면 쉽게 구할 수 있다.
-
parsnip을 이용해서 모형을 적합했기에 extract_fit_parsnip 을 이용해서 객체를 추출하고 vif 함수를 이용하여 다중공선성을 측정했다.
-
기억하기론 10을 넘기는 변수가 없었어서 다중공선성은 없었다.
- 유의한 변수 중 가장 영향 많이 끼친 변수 찾고, 오즈비 보고 어떻게 영향을 끼치는지
-
p-value랑 회귀계수를 이용해서 가장 많이 영향을 끼친 변수를 찾았었다. 유의한 변수들은 p-value가 다 매우 작았어서 회귀계수가 가장 큰 변수를 영향을 많이 끼친 변수라고 지정했었다.
-
그리고 회귀계수 추출 후 exp() 함수로 오즈비를 구한다음 y에 끼친 영향력을 설명했다.
- ROC curve 그리기, AUC 구하기
- 데이터를 분할하지 않았었기에 그냥 모형 적합에 이용한 데이터를 이용하여 yardstick 패키지의 roc_curve, roc_auc 함수로 구해주었다.
이번 ADP를 준비하기 위해서 참고한 자료
책은 호기롭게 6권 정도 빌렸으나 그 중 2개만 봤다.
- (R을 이용한 누구나 하는)통계분석 = Data analysis for beginner
- R 통계과목 풀 때 유용할 것 같았어서 이 책은 시험 볼 때 가져갔다. 별로 참고는 안했지만 공부 할 때는 쓸만 했다.
- 파이썬을 활용한 베이지안 통계
- 베이지안 통계에 대한 지식이 하나도 없어서 한번 읽어봤는데 ADP 시험에는 별로 쓸만한 것 같진 않다. 하지만 베이지안 통계에 대해서 처음 배우는 사람들에게는 괜찮은 책인 것 같다.
- 이 밖에 대학시절 전공책들
-
박동련 교수님의 시계열 분석 - 대학 시절 유일한 시계열 수업 때 쓰던 책이며 시계열은 이 책으로 공부해 갔었다. 그냥 함수 참고용으로 시험 때 가져갔었는데 유용하지는 않았다.
-
생명과학연구를 위한 통계적 방법 - 보건의학통계 수업 들을 때 쓰던 책인데 책은 SAS로 쓰여있지만 가설검정이나 생존분석 등 통계 이론 배우는데 참고했다.
- R을 활용한 기계학습 : 데이터 분석을 위한 머신 러닝 이론과 적용 / 브레트 란츠 지음; 전철욱 옮김
-
이 책은 빌렸는데 대학교 시절에 배웠던 내용들이 그대로 있어서 안봤음.
-
근데 머신러닝 처음 접하는 사람한테 추천할 만한 책인데 문제는 너무 두꺼움
- 멋쟁이천재사자 블로그
-
시험 막바지 준비기간에 “멋쟁이천재사자”라는 블로글 발견했는데 이 블로그에 ADP 관련 자료들이 아주 잘 정리되어있다.
-
이 분이 정리해 준 자료를 들고 시험장에 갔는데 시험 준비 기간동안 한번도 안봤어서 참고는 못했다.
-
다음 시험 준비할 때 참고할 것 같다.
시험 후기 및 앞으로의 계획
전반적으로 시험이 패키지에 의존하여 풀지 못하도록 문제들이 나오는 것 같다.
공교롭게도 ADP 실기가 10시부터 시작해서 2시에 끝났는데 2시 반까지 IBK 기업은행 필기시험을 보러갔어야 했어서 1시 40분쯤까지만 시험을 보느라 문제를 다 풀 생각도 안했지만
2번 문제는 전처리부터 괴랄해서 데이터 구경도 못하고 시험장을 나왔다.
필자는 패키지에 의존해서 문제를 푸는 스타일인데 머신러닝 2번 문제를 보니 앞으로는 그러면 안될 것 같다.
패키지 없이 푸는 방식들을 조금 배워야할 것같다.
앞으로 이 블로그에는 ADP를 위한 통계적 검정 방법부터 머신러닝 모형 만드는 것 까지 긴 시간에 걸쳐서 포스팅을 하면서 ADP 준비를 할 것이다.
마지막으로 시험장은 신도림역에 그린컴퓨터아트학원에서 봤는데
그럭저럭이였다 뭐 어느 곳에서 보든 시험 환경은 주최측에서 설정해주는거고 시험장 자체는 키보드 마우스 둘다 무난했는데 이제 막 추워지던 시기라서 에어컨을 마음대로 못틀어서 조금 더웠다
[출처] 제 35회 ADP 실기 불합격 기념 복기(with. R)|작성자 맞갖다