Discriminant Analysis, DA
1. 판별분석의 정의 및 목적
-
정의: 2개 이상의 집단(Group, 모집단)이 알려져 있을 때, 새로운 관측값이 어느 집단에 속할지 특성에 기초하여 이미 알려진 집단 가운데 하나로 분류하는 기법
-
가정:
- 모집단에 대한 다변량 정규성
- 그룹 내 공분산 행렬의 동일성
- 변수들 간 낮은 다중공선성
-
목적
- 분류기(Classifier) 생성: 집단을 가장 잘 구분하는 변수들의 조합(판별식)을 찾음
- 분류(Classification): 생성된 판별식으로 새로운 데이터를 특정 그룹에 할당.
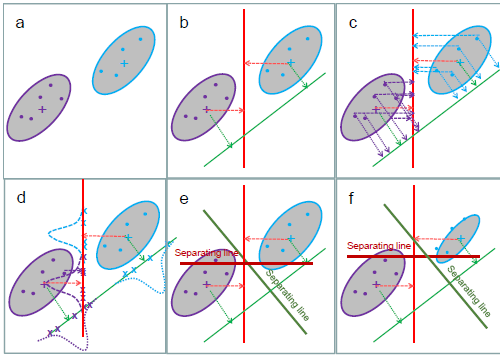 | 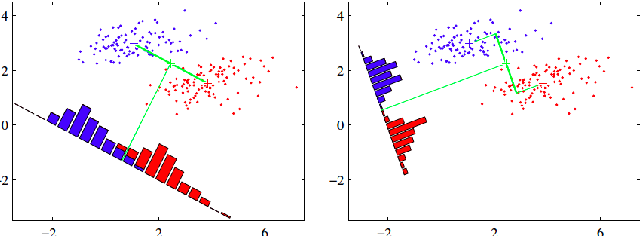 |
2. 판별분석의 기하학적 원리
판별분석은 데이터의 차원을 축소하면서 두 집단 간의 겹치는 부분(에러)을 최소화하는 최적의 직선(축)을 찾는 과정
- 각 그룹별 95% 자료를 포함하는 타원을 그린다.
- 타원을 교차하는 두 점을 지나는 직선을 그린 후, 이 직선을 새로운 축에 사영(Projection) 시킨다.
- 사영된 새로운 단일분포 (histogram) 간의 중첩 (겹치는 부분) 을 최소로 하는 직선을 찾는다.
이 직선 (새로운 축) 은 기존의 축 과 의 선형결합이다. 이 직선을 A와 B를 가장 잘 분류하는 **판별식 (분류기)** 라고 부른다.
3. 판별분석의 종류
판별분석은 두 가지 서로 다른 방향에서 해석될 수 있다.
1) Fisher
첫 번째는 데이터의 중심 간에 최대의 분리가 일어나고 동시에 데이터의 각 그룹 내의 변동을 최소화하는 예측변수들의 선형결합(판별식)을 찾는 것이다. 이 방법은 Fisher가 제안한 그룹-내(within-class)공분산 대비 그룹-간(between-class) 공분산을 최대로 하는 예측변수들의 선형결합을 찾는 것과 동일하다.
p차원의 예측변수 X의 공분산 행렬 Σ(n×p행렬)은 군집-내 공분산 W와 군집-간 공분산 B로 다음과 같이 분해된다.
2) Bayesian
두 번째는 베이지안 관점으로 주어진 예측변수 x자료를 가장 큰 사후확률을 가지는 군집 또는 사후확률의 분자에 해당하는 식을 최대로 하는 군집으로 분류하는 것이다.
1. LDA (선형판별분석)
조건부분포 에 대해 군집-특정적 평균벡터 과 공통의 공분산행렬 를 가지는 다변량 정규분포 를 가정한다.
가 given되어 있어도 분포는 같고 그룹에 따라 평균벡터 만 다르므로 다변량 정규분포식과 유사하다고 생각하면 된다.
사후확률의 분자는
여기에 로그 취하면
이를 판별함수(discriminant function)이라고 하며, 그룹 간 판별함수의 차이가 판별식이 된다.
판별함수 식이 간단하게 정리된 이유는 판별식을 구할 때 그룹간 동일한 항들은 제거되기 때문이다.
2. QDA (이차판별분석)
조건부분포 에 대해 군집-특정적 평균벡터 과 공통의 공분산행렬 를 가지는 다변량 정규분포 )를 가정한다.
이 때, 이차판별함수는 아래와 같다.
이후, 각 쌍의 군집 와 간의 결정 경계(decision boundary)는 이차식으로 표현된다.
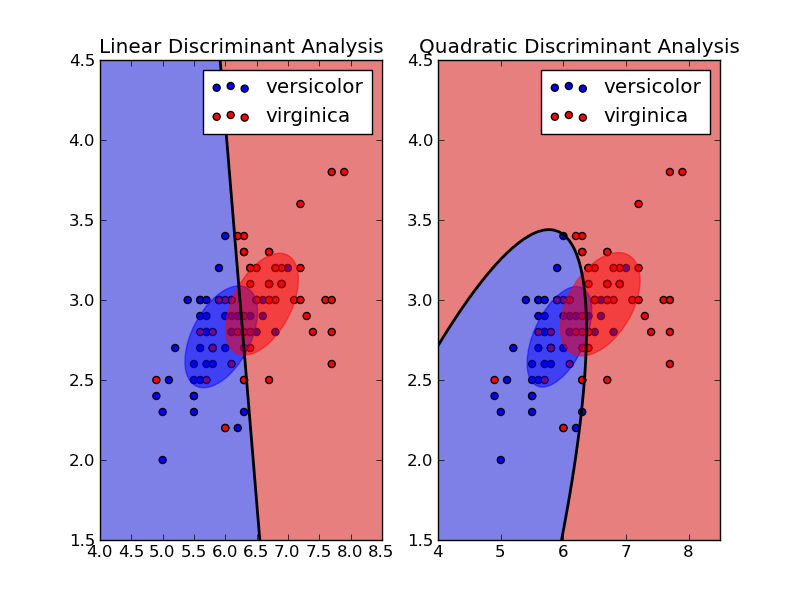
QDA가 더 유연하게 자료를 분류한다.
QDA는 LDA (선형 판별 분석) 와 달리 모든 군집(클래스)이 동일한 공분산 행렬을 공유한다고 가정하지 않는다. 대신 각 군집 마다 고유한 공분산 행렬 를 추정한다.
추정 데이터량: 예측변수(Feature)의 개수를 , 군집의 개수를 라고 할 때:
- LDA: 하나의 공분산 행렬 Σ만 추정하면 되므로 약 개의 모수를 추정
- QDA: 각 군집마다 행렬을 추정하므로 개의 모수를 추정
판별함수의 연산은 공분산의 역행렬을 반드시 요구한다.
군집별 공분산 행렬 가 역행렬()을 가지기 위해서는 해당 행렬이 Full Rank 여야만 한다. (=singular matrix 여서는 안된다.)
Full Rank 이기 위해서는, 각 군집 내의 샘플 수 가 예측변수의 수 보다 커야만 한다. ()
- 행렬곱의 Rank는 곱해지는 개별 행렬의 Rank보다 클 수 없으므로, 라면, 데이터 행렬의 Rank는 최대 가 되며, p×p 크기인 공분산 행렬 의 Rank 역시 최대 가 된다.
따라서 QDA를 안정적으로 사용하기 위해서는 충분한 양의 데이터(nk≫p)가 확보되어야 한다.
데이터가 부족한 경우에는 LDA를 사용하거나, 공분산 행렬에 편향을 주어 정규화하는 RDA 를 대안으로 사용한다.
3. Regularized DA (일반화 판별분석)
LDA와 QDA 간의 타협적인 방법으로 QDA의 구분된 공분산을 LDA의 공통인 공분산 쪽으로 축소(shrink)를 허용하는 것이다.
- 는 LDA에서 사용되는 공통의 공분산 행렬
- 은 QDA에서 사용되는 군집-특정적 공분산 행렬
는 0과 1 사이의 값. validation set 또는 cross-validation에 기초하여 최적의 성능을 나타내는 값으로 정해진다.