왜 정확도(Accuracy)만으로는 부족한가?
데이터의 95%가 ‘정상’이고 5%가 ‘질병’인 상황을 가정.
- 어떤 모델이 학습도 하지 않고 무조건 “정상”이라고만 답해도 정확도는 95%
- 이 모델은 실제 실력이 있는 것이 아니라, 데이터 분포 덕분에 우연히 높은 점수를 획득
Kappa는 바로 이 ‘우연의 효과’를 도려내고 모델의 순수한 성능을 보여준다.
- 장점: 불균형 데이터(Imbalanced Data)에서 모델의 성능을 훨씬 객관적으로 평가할 수 있음
- 한계: 계산 방식의 특성상 특정 클래스에 데이터가 너무 쏠려 있으면, 실제 성능보다 Kappa 값이 지나치게 낮게 나오는 ‘Kappa Paradox’ 현상이 발생할 수 있음.
- 불균형 데이터에 민감함: Kappa는 클래스 불균형이 극심할 때 매우 낮게 나올 수 있다. 이는 모델이 한쪽 클래스로 치우쳐 예측하고 있음을 경고하는 좋은 신호.
Cohen’s Kappa
- 는 observed accuracy (모델이 맞힌 비율)
- 는 expected accuracy (두 집단이 무작위로 선택했을 때 우연히 일치할 것으로 예상되는 확률. 말 그대로 우연히 일지된 평가를 받을 비율)
즉, 실제 정확도와 예측된 정확도를 구분지어서 위의 식으로 구한 수치.
- -1 부터 +1 까지의 값을 가진다.
- 0 일 경우, 관측된 클래스와 예측된 클래스 사이의 합의점이 전혀 없음.
- 예측을 완전히 틀렸다.
- 1은 관찰된 클래스와 예측된 클래스가 완벽히 일치한다. (BEST)
- 음수값은 예측이 실제값과 완전히 정반대에 있다. (거의 발생하지 않음)
from sklearn.metrics import cohen_kappa_score
# y_true: 실제 정답, y_pred: 모델의 예측값
y_true = [0, 1, 0, 0, 1, 0, 1, 0]
y_pred = [0, 0, 0, 0, 1, 0, 1, 1]
kappa = cohen_kappa_score(y_true, y_pred)
print(f"Cohen's Kappa: {kappa:.4f}")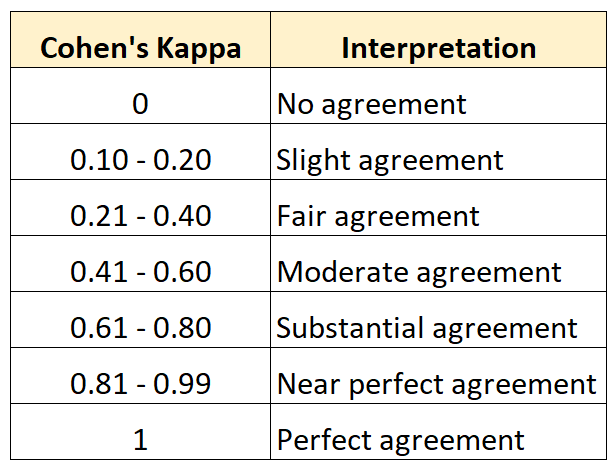
weighted Kappa
kappa 는 다중 클래스 분류에서도 사용할 수 있어 범용성이 높다.
3개 이상의 클래스들 사이 관계에 대한 kappa.
low, medium, high라는 순서형 클래스를 가지는 값이 있을 때, Kappa에 가중치를 매겨서 사용.
- 가중치 방식 (Weighting Schemes)
- Linear Weighting (선형 가중치): 등급 간의 차이에 비례해서 페널티 (예: 1단계 차이는 1점, 2단계 차이는 2점 감점)
- Quadratic Weighting (이차 가중치): 등급 간 차이의 제곱에 비례해서 페널티 멀리 떨어질수록 감점 폭이 기하급수적으로 커지며, 이는 통계적으로 ICC (내부합치도) 와 유사한 성격을 갖는다.
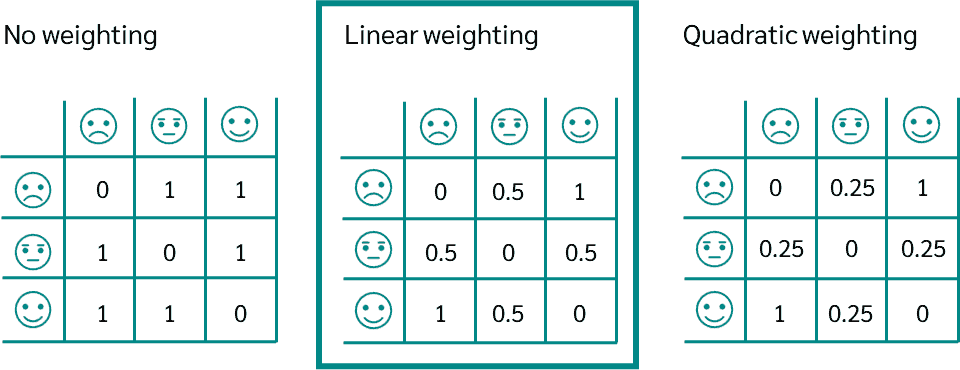
잘못된 관측이 발생할 때마다, kappa 값은 감소함. 이때
- low샘플을 medium이라고 예측했을 때 -1
- low샘플을 high라고 예측했을 때 -2
두 클래스 사이의 거리가 멀 때, 더 큰 감점을 부여함.
from sklearn.metrics import cohen_kappa_score
# y_true: [Low(0), Medium(1), High(2)]
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 2, 1, 1, 0] # 일부러 크게 틀린 샘플 포함
# 1. 일반 Kappa (Unweighted)
kappa = cohen_kappa_score(y_true, y_pred)
# 2. Weighted Kappa (Quadratic 방식 권장)
weighted_kappa = cohen_kappa_score(y_true, y_pred, weights='quadratic')
print(f"일반 Kappa: {kappa:.4f}")
print(f"Weighted Kappa: {weighted_kappa:.4f}")