Convolution Neural Network
- 입력데이터 크기 , 패딩 크기 , 스트라이드 크기
- 이는 데이터가 정사각형일때만 성립
- 가로 / 세로 크기가 다를 경우 가로 / 세로 각각에 수식을 적용해야 함함
이미지의 경우 보통 가로 / 세로 이외에 색상 등을 나타내는 채널 값이 필요함. 채널을 추가하면 가로 픽셀 수, 세로 픽셀 수, 채널 수로 3차원 데이터가 된다. 이 데이터를 미니배치 단위로 처리하면 배치 크기, 가로 픽셀 수, 세로 픽셀 수, 채널 수로 4차원이 된다. 보통 이미지 처리용 딥러닝 모델은 미니배치 단위로 훈련하므로, 기본적으로 4차원 데이터를 다룬다.
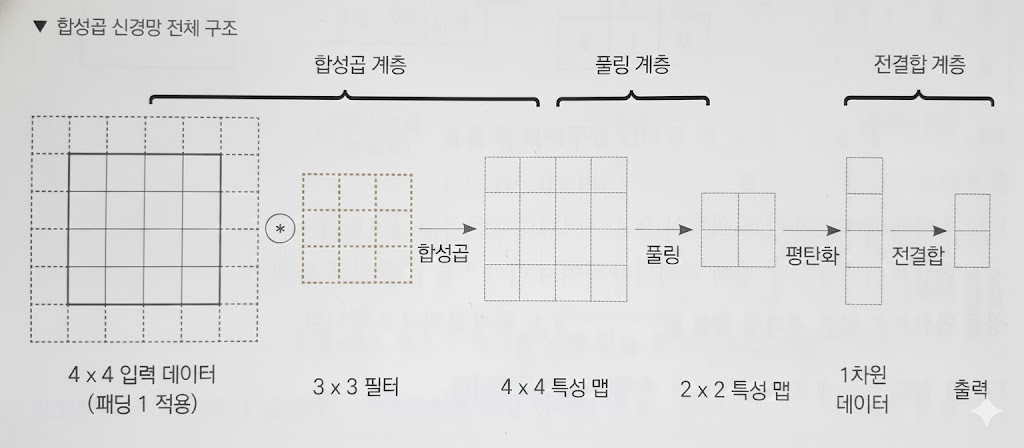
convolution layer
- 합성곱 계층
합성곱으로 이루어진 신경망 계층
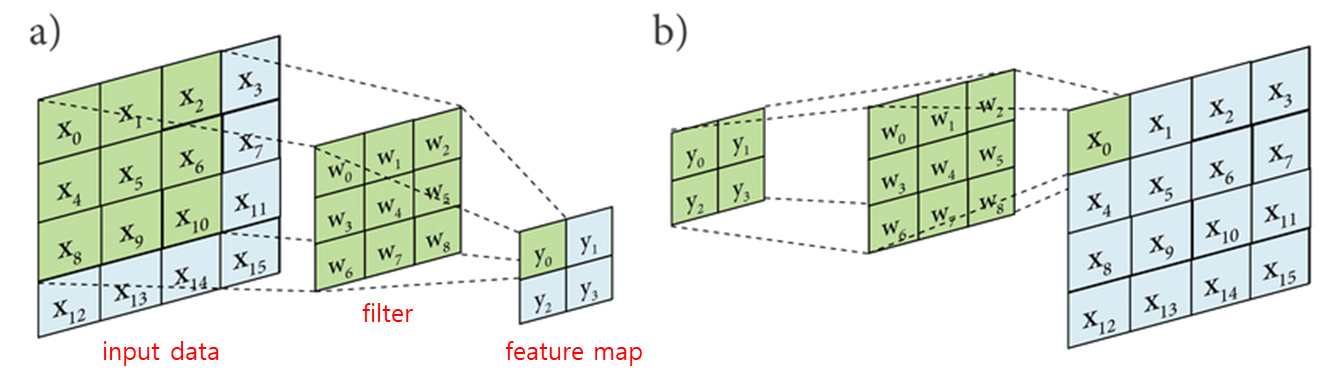
합성곱: 2차원 데이터의 일정 영역 내 값들을, 하나의 값으로 압축하는 연산
- 필터: 입력 데이터에서 특정한 특성을 필터링
- 필터를 통과하는 과정에서 특정 특성을 부각 / 약화
- 요소별, 특징별 특성을 가져오는 역할
- 특성맵: 필터 통과 후 압축된 데이터. 전체 데이터에서 중요한 특징만 추출된 것. 중요한 특징만 남아있는 결과물.
- 필터의 패턴과 일치하는 영역일수록, 특성 맵에서 숫자가 크다. 의 숫자가 가장 크다면, 입력 데이터의 왼쪽 위 영역이 필터의 패턴과 가장 유사한 부분인 것.
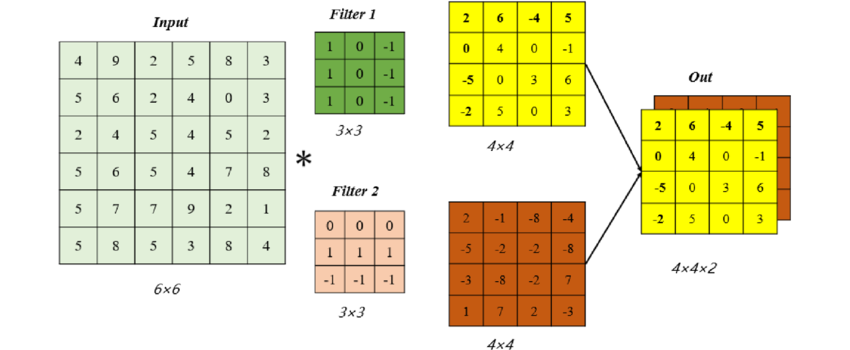
- 여러 특성을 추출해두기 위해, convolution layer 에서는 보통 필터를 여러개 사용한다. 아래와 같을 경우 필터 2개를 적용해둔 것.
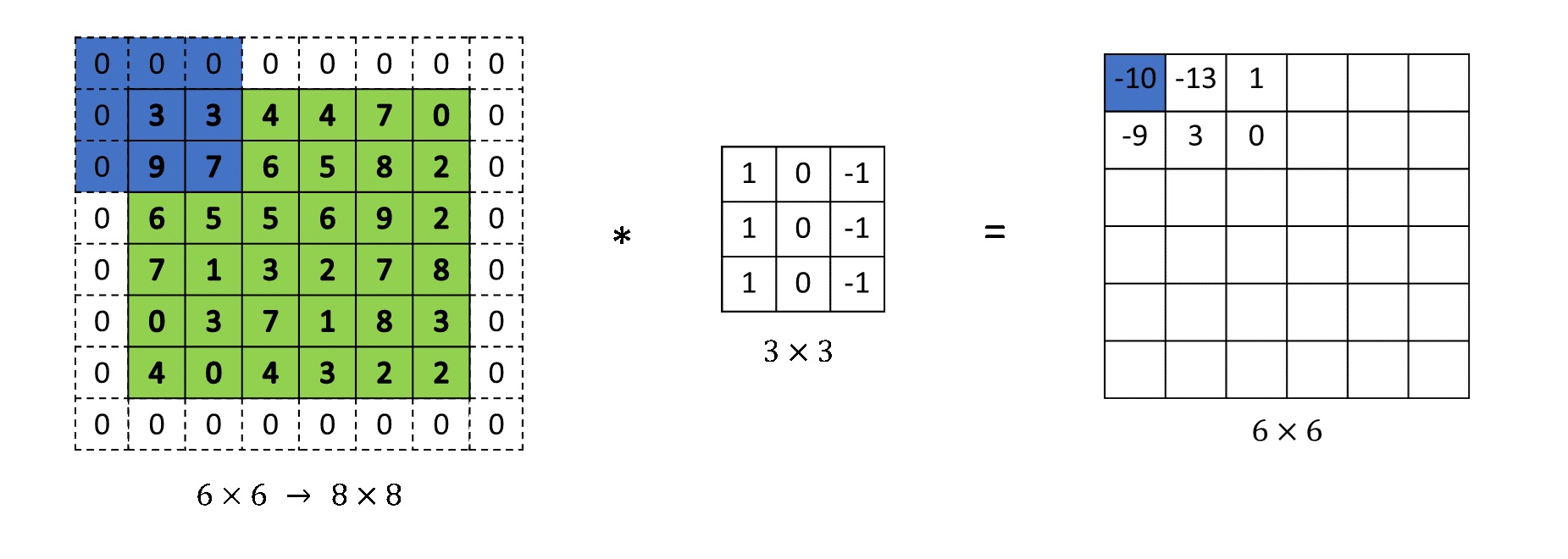
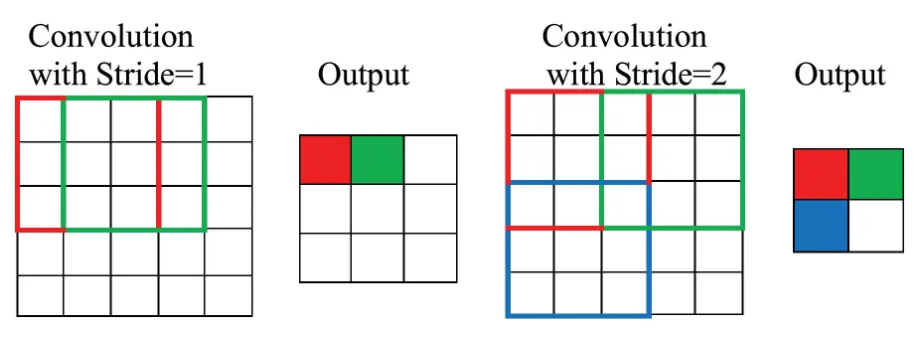
패딩, 스트라이드
합성곱 연산은 데이터의 크기를 줄이므로 여러번 반복하면 더이상 합성곱 연산을 적용할 수 없다.
- 필터 크기가 3×3 인데 output 이 2×2 가 되면 그 시점부터는 적용할 수 없을 것이므로
이상황을 막기 위해 출력되는 특성 맵과 입력 데이터의 크기를 동일하게 유지하면 된다. 이를 위해 데이터를 두껍게 만드는 것을 padding 이라고 한다.
stride 는 필터 이동 1회에 이동하는 간격을 지정한다. stride 가 크면 그만큼 feature map 크기가 감소한다.
stride 는 pooling 에서도 있으며, conv 랑 pool 의 stride 크기는 보통 동일하게 한다.
pooling layer

| convolution | pooling |
|---|---|
| 필터가 필요 | 필터 필요 × |
| 필터의 패턴과 유사한 영역 추출 | 특정 영역의 최댓값, 평균값으로 요약 |
| 물체 위치가 바뀌면 같은 물체로 인식 못함 | 특정 영역의 요약정보를 쓰므로 위치가 약간 변해도 같은 물체로 인식 |
| feature map 크기를 줄여 연산속도 up |
특성 맵 크기를 줄여 이미지의 요약 정보를 추출하는 기능
- 최대 풀링: 풀링 영역에서 가장 큰 값을 취함
- 영역에서 가장 뚜렷한 (밝은) 부분
- 평균 풀링: 풀링 영역의 평균값을 구함
- 영역의 평균적인 특징
fully-connected layer (전결합)
- 전결합 계층, 밀집 계층 (dense layer)
보통 마지막 부분에서 구현.
- 앞의 합성곱 / 풀링 계층이 이미지에서 특성을 뽑아내면
- 전결합 계층은 이 특성을 활용해 특정한 레이블로 분류하는 역할
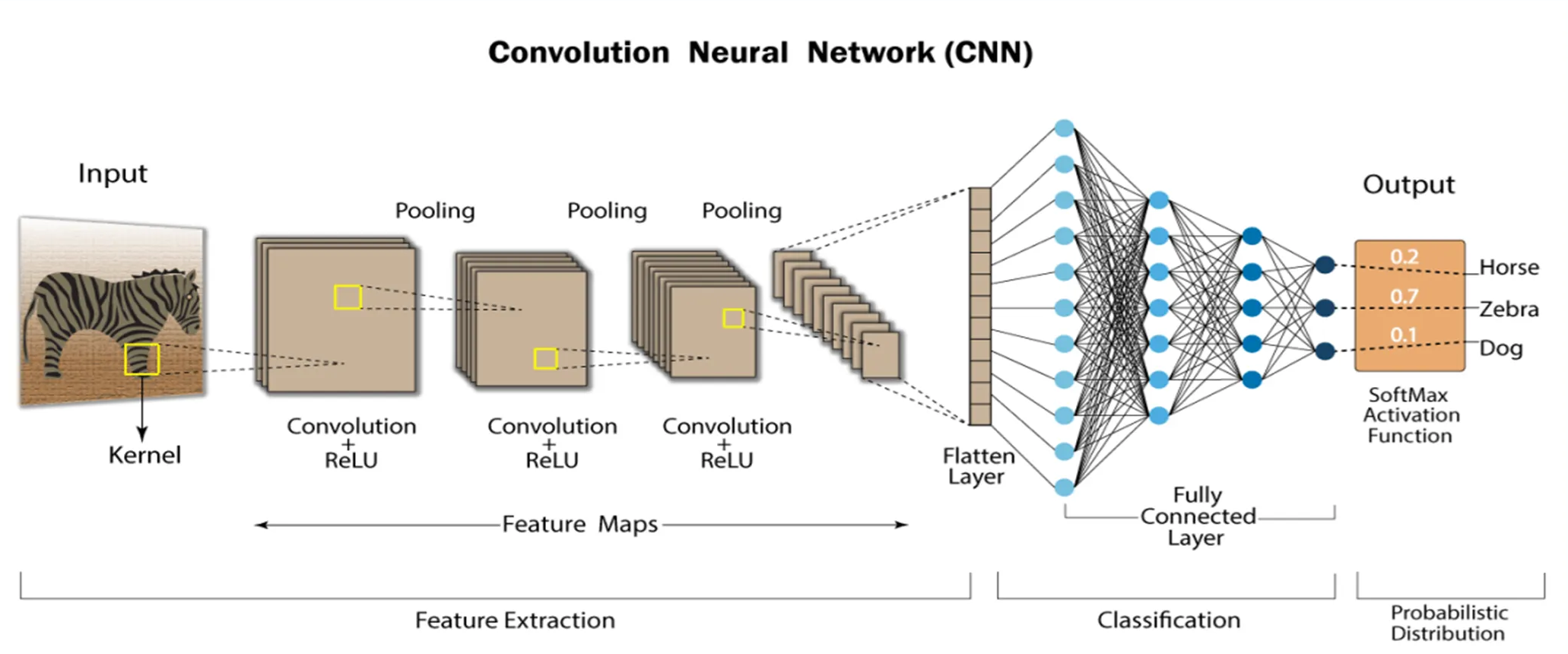
합성곱 / 풀링을 거친 2차원 데이터는 1차원으로 변형 뒤 전결합 적용 가능. 이 1차원으로 바꾸는 작업이 평탄화 (flatten).
개와 고양이를 구분하는 문제가 있다고 할 때, 최종 출력값은 개/고양이로 딱 2개. 최종 출력값은 1차원이므로, 전결합 계층의 입력도 1차원으로 받음.
이를 위해 평탄화를 해줘야 함. 전결합 계층을 거치면 최종 출력값, 즉 우리가 원하는 타깃값이 도출.
평탄화한 1차원 데이터를 바로 최종 출력값과 전결합하면 편할텐데, 전결합 계층을 여러개 만드는 이유는?
- 분류를 효율적으로 하기 위함.
- 평탄화된 데이터가 100개일 경우
- 100개의 특성을 바탕으로 바로 최종 출력값, 즉 타깃값을 구해도 됨
- 하지만 100개의 특성을 토대로 10개의 특성으로 먼저 구분한 후
- 다시 10개의 특성을 기반으로 최종 출력값을 구하는게 보통 더 효율적
- 물건이 쌓였을 때 1차로 분류한 후, 분류한 것을 바탕으로 분류하는게 나은 것처럼