입력 텍스트 단어의 15%를 무작위로 마스킹(Masking)하여 신경망에 인입한 뒤 원본 단어를 예측하게 함.
독립적으로 학습되지 않으며, NSP 태스크와 Loss를 합산하여 동시에 사전 훈련이 이루어짐.
NSP (Next Sentence Prediction)
QA, NLI 등 두 문장 간의 논리적 관계 이해가 필수적인 태스크 성능 고도화
실제 이어지는 문장과 랜덤 문장을 50:50 비율로 제공하여 두 문장의 연속성 여부(IsNext/NotNext)를 이진 분류로 학습함.
MLM 태스크와 결합되어 Loss 총합을 바탕으로 동시 학습이 진행됨.
Segment Embedding
복수 문장 입력 태스크 수행 시 개별 문장 간의 경계 구획
첫 번째 문장 영역에는 Sentence 0 임베딩 벡터를, 두 번째 문장 영역에는 Sentence 1 임베딩 벡터를 가산함.
문장의 최대 개수에 대응하도록 단 2개의 임베딩 벡터 종류만 보유하고 사용함.
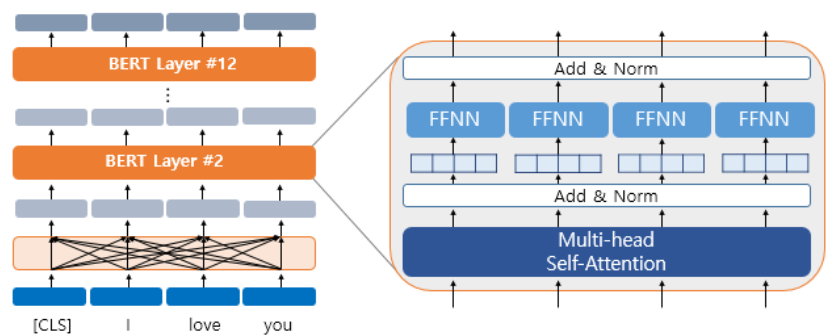
BERT(Bidirectional Encoder Representations from Transformers)
Transformer 아키텍처를 기반으로 하며, 양방향으로 문맥을 고려하여 단어의 임베딩을 학습합니다.
대규모의 텍스트 데이터를 사용하여 사전 훈련되며, 언어 모델링과 다양한 자연어 처리 작업에 활용될 수 있습니다.
자연어 이해, 문장 분류, 질문 응답, 개체명 인식 등 다양한 자연어 처리 작업에서 좋은 성능을 보여줍니다.
특징은 문맥을 고려한 양방향 임베딩, 다음 문장 예측(pretraining task), Transformer 아키텍처 등이 있으며, 이를 통해 다양한 자연어 처리 작업에 적용할 수 있는 강력한 모델입니다.
단계
사전 훈련 단계 : 대량의 텍스트 데이터를 사용하여 단어의 의미를 학습합니다(masked language model, next sentence prediction).
파인튜닝 단계 : 특정 자연어 처리 작업에 맞게 추가적인 훈련을 수행하여 성능을 개선합니다.
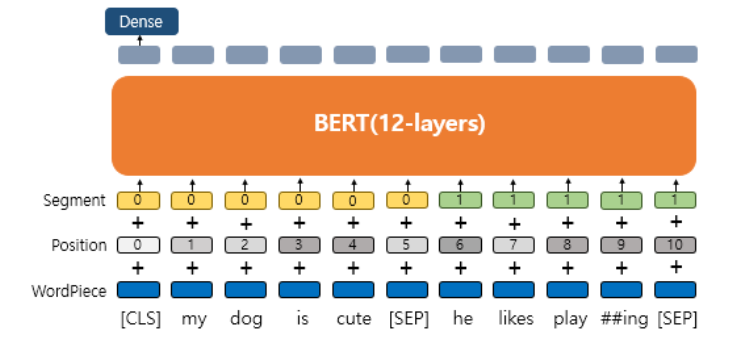
3개의 임베딩 층
WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
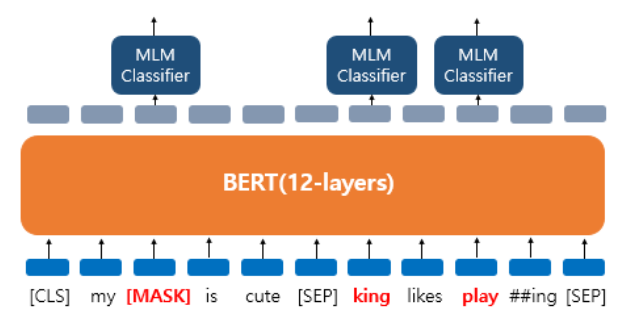
BERTMLM(masked language model)
BERT는 사전 훈련을 위해서 인공 신경망의 입력으로 들어가는 입력 텍스트의 15%의 단어를 랜덤으로 마스킹(Masking)합니다.
BERTNSP(next sentence prediction)
BERT는 두 개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련시킵니다. 이를 위해서 50:50 비율로 실제 이어지는 두 개의 문장과 랜덤으로 이어붙인 두 개의 문장을 주고 훈련시킵니다.
이어지는 문장의 경우
이어지는 문장이 아닌 경우 경우
Sentence A
The man went to the store.
The man went to the store.
Sentence B
He bought a gallon of milk.
dogs are so cute.
Label
IsNextSentence
NotNextSentence
마스크드 언어 모델과 다음 문장 예측은 따로 학습하는 것이 아닌 loss를 합하여 학습이 동시에 이루어집니다.
BERT가 언어 모델 외에도 다음 문장 예측이라는 태스크를 학습하는 이유는 BERT가 풀고자 하는 태스크 중에서는 QA(Question Answering)나 NLI(Natural Language Inference)와 같이 두 문장의 관계를 이해하는 것이 중요한 태스크들이 있기 때문입니다.
BERT segment embedding
BERT는 QA 등과 같은 두 개의 문장 입력이 필요한 태스크를 풀기도 합니다. 문장 구분을 위해서 BERT는 세그먼트 임베딩이라는 또 다른 임베딩 층(Embedding layer)을 사용합니다. 첫번째 문장에는 Sentence 0 임베딩, 두번째 문장에는 Sentence 1 임베딩을 더해주는 방식이며 임베딩 벡터는 두 개만 사용됩니다.