capacity
• 모델이 학습할 수 있는 복잡성 또는 유연성 • 모델의 Capacity가 높을수록 더 복잡한 함수를 모델링할 수 있지만, 동시에 더 많은 데이터를 필요로 할 수 있고, 과적합(Overfitting)의 위험도 증가할 수 있습니다. • 모델의 Capacity는 모델 구조, 파라미터의 수, 히든 레이어의 수 등과 관련이 있습니다. 작은 Capacity를 가진 모델은 단순한 함수를 학습할 수 있지만, 복잡한 패턴을 학습하기 어려울 수 있습니다. 반면에 큰 Capacity를 가진 모델은 복잡한 함수를 학습할 수 있지만, 적은 데이터로도 모델이 데이터에 과적합될 수 있는 가능성이 높습니다. ◦ 인공 신경망에서는 모델에 있는 매개변수들의 수를 모델의 수용력(capacity)이라고 하기도 합니다. • 모델의 Capacity 선택은 학습 알고리즘의 목표와 데이터의 특성에 따라 달라집니다. 모델이 데이터에 잘 일반화되고 적절한 복잡성을 가질 수 있도록 Capacity를 조절하는 것이 중요합니다. 이를 위해서는 교차 검증과 같은 기법을 사용하여 모델의 성능을 평가하고 최적의 Capacity를 찾을 수 있습니다.
covariate
• 독립 변수(입력 변수) 중에서 예측을 위해 사용되는 변수. covariate의 선택은 도메인 지식과 데이터 분석의 목적에 따라 결정. • covariate의 선택은 데이터 전처리 단계에서 이루어지며, feature engineering 과정에서 변수들을 변환하거나 새로운 변수를 생성하는 등의 작업을 수행할 수도 있습니다 • ex : 주택 가격을 예측하는 문제에서는 주택의 크기, 위치, 시설 등이 covariate로 사용될 수 있습니다.
MDP(Markov Decision Process)
• 강화학습의 기본적인 수학적 모델 중 하나입니다. MDP는 시간 순서에 따라 의사 결정을 내리는 상황에서, 현재의 상태와 행동에 따라 미래의 보상을 최대화하기 위한 최적의 정책을 학습하는 프레임워크입니다. • 에이전트가 현재 상태에서 가능한 모든 행동 중에서 최적의 행동을 선택하고, 다음 상태로 전이되면서 보상을 얻게 됩니다. 이 과정을 반복하여 에이전트는 최적의 정책을 학습하고 보상을 최대화하는 방향으로 행동을 결정합니다. • 구성 요소 ◦ 상태(State): 시스템이 있는 특정 상태를 나타냅니다. 예를 들어, 로봇이 있는 위치, 게임의 게임 보드 상태 등이 상태가 될 수 있습니다. ◦ 행동(Action): 에이전트가 취할 수 있는 선택 가능한 행동을 나타냅니다. 예를 들어, 로봇이 움직일 수 있는 방향, 게임에서 캐릭터의 이동 등이 행동이 될 수 있습니다. ◦ 보상(Reward): 특정 상태에서 특정 행동을 취했을 때 얻는 보상을 나타냅니다. 보상은 에이전트의 목표에 따라 정의됩니다. 목표는 일반적으로 미래의 보상을 최대화하는 것입니다. ◦ 상태 전이 확률(State Transition Probability): 상태와 행동에 따라 다음 상태로 전이될 확률을 나타냅니다. 즉, 상태와 행동의 조합에 따라 어떤 상태로 이동할 확률을 가지는지를 의미합니다.
style transfer
• 하나의 이미지의 스타일과 다른 이미지의 콘텐츠를 결합하여 새로운 이미지를 생성하는 기술. • 딥러닝 모델을 사용하여 이미지의 스타일과 콘텐츠를 분리하고, 스타일을 한 이미지에서 추출하여 다른 이미지에 적용하는 과정으로 이루어집니다. • 주로 컴퓨터 비전 및 예술 분야에서 사용되며, 이미지의 스타일을 변환하거나 특정 작품의 스타일을 다른 이미지에 적용하는 등의 다양한 창작적인 활용이 가능합니다. 예를 들어, 유명한 화가의 그림 스타일을 사진에 적용하여 고품질의 예술적인 이미지를 생성할 수 있습니다.
CycleGAN
• 머신 러닝에서 사용되는 이미지 변환 알고리즘 중 하나로, 두 개의 서로 다른 도메인 간의 이미지를 변환하는 능력을 갖춘 모델입니다. 예를 들어, 말 이미지를 얼룩말 이미지로 변환하거나, 낮 이미지를 밤 이미지로 변환하는 등의 작업을 수행할 수 있습니다. • 비지도 학습 방식으로 작동하며, 훈련 데이터에는 동일한 이미지 쌍이 필요하지 않습니다. 대신, 두 도메인 간의 대응되는 이미지가 없어도 두 도메인 사이의 매핑을 학습할 수 있습니다. 이를 위해 CycleGAN은 두 개의 생성자(generator)와 두 개의 판별자(discriminator)로 구성됩니다. • 이미지 변환을 위해 순환 일관성 손실(cycle consistency loss)을 사용합니다. • 주로 이미지 스타일 변환, 도메인 간의 콘텐츠 이식, 그림체 변환 등의 응용 분야에서 사용됩니다. 예컨대, 사진을 예술 작품으로 변환하거나, 흑백 사진을 칼라 사진으로 변환하는 등의 작업에 활용될 수 있습니다. CycleGAN은 딥러닝 기반의 이미지 변환 기술 중 하나로서, 창의적이고 다양한 이미지 변환을 구현할 수 있는 강력한 도구입니다.
cycle consistency loss
• CycleGAN이나 다른 이미지 변환 모델에서 사용되는 손실 함수 • 이 손실 함수는 변환된 이미지와 원본 이미지 간의 차이를 최소화하여, 이미지가 원래 도메인으로 잘 복원될 수 있도록 학습합니다. 즉, 이미지를 한 도메인에서 다른 도메인으로 변환한 후, 다시 원래 도메인으로 돌렸을 때 입력 이미지와 비슷한 이미지를 얻을 수 있도록 학습하는 것입니다. • CycleGAN에서 중요한 구성 요소이며, 이미지 변환 과정에서 원본 이미지와 변환된 이미지 간의 일관성을 유지하는 데 도움을 줍니다. 이를 통해 모델은 두 도메인 간의 이미지를 서로 변환할 수 있으며, 변환된 이미지가 원본 이미지와 일관성을 유지하는 고품질의 결과물을 생성할 수 있습니다.
CNN(Convolutional Neural Network)
• 이미지와 같은 그리드 형태의 데이터를 처리하는 머신 러닝 모델입니다. 주로 이미지 인식, 컴퓨터 비전 등의 작업에 많이 사용되며, 이미지의 공간적 구조를 잘 이해하고 특징을 추출하는 데 강점을 가지고 있습니다. • 이미지 분류, 객체 감지, 세그멘테이션 등의 다양한 컴퓨터 비전 작업에서 우수한 성능을 보여줍니다. • 사전에 학습된 CNN 모델을 사용하여 전이 학습(Transfer Learning)을 수행할 수도 있습니다. • 다층 퍼셉트론을 사용할 때보다 훨씬 적은 수의 가중치를 사용하며 공간적 구조 정보를 보존한다는 특징이 있습니다. • 구성 ◦ 합성곱(Convolution) 레이어 : 입력 이미지에 필터(커널)를 적용하여 특징 맵(Feature Map)을 생성합니다. 이를 통해 이미지의 주요한 특징을 추출할 수 있습니다. ▪ feature map : 입력 이미지를 필터(또는 커널)를 통해 추출한 특징의 지도. ◦ 풀링(Pooling) 레이어 : 특징 맵의 크기를 줄이면서 중요한 정보를 유지합니다(max pooling, average pooling) ◦ 완전 연결(Fully Connected) 레이어 : 특징 맵에서 추출한 특징을 기반으로 분류 등의 작업을 수행합니다.
1D CNN(1-Dimensional Convolutional Neural Network)
• 주로 1차원 시계열 데이터를 처리하는 데 사용되는 합성곱 신경망 모델. • 이미지 처리에 사용되는 2D CNN과 비슷한 원리를 가지지만, 입력 데이터가 1차원으로 구성되어 있다는 점에서 차이가 있습니다. • 1D CNN은 시계열 데이터의 시간적인 특성을 잘 이해하고, 시퀀스 내에서 패턴을 감지하고 추출하는 데 강점을 가지고 있습니다. 주로 음성, 자연어 처리, 센서 데이터 등과 같은 시계열 데이터를 다룰 때 사용됩니다.
corpus
• 학습에 사용되는 텍스트 데이터의 집합 • 일반적으로 특정 주제, 도메인 또는 언어에 관련된 문서 집합 • 다양한 형태의 텍스트 데이터로 구성될 수 있습니다. 예를 들어, 자연어 처리(Natural Language Processing, NLP) 분야에서는 웹 문서, 뉴스 기사, 소셜 미디어 게시물, 문학 작품, 과학 논문 등 다양한 텍스트 데이터를 코퍼스로 활용합니다. • 코퍼스를 학습하여 언어 모델링, 텍스트 분류, 문서 요약, 기계 번역, 감성 분석 등 다양한 자연어 처리 작업을 수행할 수 있습니다. 코퍼스의 크기와 다양성은 모델의 성능과 일반화 능력에 영향을 미치므로, 적절한 코퍼스의 선택과 전처리는 머신러닝 기반 자연어 처리의 핵심 요소입니다.
pre-training
• 머신러닝과 딥러닝에서 주어진 작업에 앞서, 대규모의 데이터를 이용하여 모델을 사전에 학습하는 기법. • 전체 데이터에 대해 모델을 미세 조정(Fine-tuning)하기 전에 수행되며, 모델이 특정 작업을 수행하는 데 도움이 되는 일반적인 지식을 습득하는 데 사용됩니다. • 주로 자연어 처리와 컴퓨터 비전 분야에서 활용되며, 최근에는 트랜스포머와 같은 모델을 대상으로 다양한 사전 훈련 기법이 발전하고 있습니다. • 종류 ◦ Unsupervised Pre-training: 레이블이 없는 대규모의 데이터를 사용하여 모델을 사전에 학습합니다. 이 방법은 데이터에 있는 통계적 패턴과 구조를 학습하게 됩니다. 주로 오토인코더, GAN(Generative Adversarial Network), 언어 모델과 같은 방법이 사용됩니다. ◦ Self-supervised Pre-training: 레이블이 없는 데이터를 레이블이 있는 데이터처럼 취급하여 모델을 사전에 학습합니다. 예를 들어, 문장의 일부를 가려두고 그 부분을 예측하도록 학습하는 문장 생성 작업이나, 이미지를 자연스럽게 잘라서 다시 맞추도록 하는 이미지 재구성 작업 등이 있습니다. • 장점 ◦ 사전 훈련된 모델은 초기화 단계에서 더 좋은 시작점을 제공하므로, 작은 양의 레이블이 있는 데이터로도 효과적인 미세 조정(Fine-tuning)이 가능합니다. ◦ 사전 훈련된 모델은 보다 일반적인 특징을 학습하므로, 다양한 관련 작업에서 성능을 향상시킬 수 있습니다. ◦ 대규모 데이터를 이용하기 때문에, 사전 훈련 단계에서 높은 계산 비용을 투자하여도 미세 조정 단계에서 상대적으로 적은 데이터로 효과적인 결과를 얻을 수 있습니다.
projection layer
• 고차원의 입력 데이터를 저차원의 공간으로 투영하는 역할을 합니다. 이는 차원 축소, 잠재 변수 추출, 데이터 시각화 등의 다양한 목적으로 사용될 수 있습니다. • 데이터의 특성과 목적에 따라 다양한 방식으로 구성될 수 있으며, 알고리즘과 모델에 따라 다양한 변형이 존재합니다. 주어진 문제와 데이터에 가장 적합한 프로젝션 레이어를 선택하고 조정하는 것이 중요합니다. • 예제 ◦ 밀집 레이어(Dense Layer): 밀집 레이어는 입력 데이터와 가중치 행렬 간의 행렬 곱셈을 수행하여 입력 데이터를 저차원으로 투영합니다. 이는 입력 데이터의 각 요소가 모든 뉴런에 연결되는 완전 연결층으로 구성됩니다. ◦ PCA (Principal Component Analysis): PCA는 입력 데이터의 주성분을 추출하여 저차원의 잠재 공간으로 투영합니다. PCA는 입력 데이터의 공분산 행렬을 분해하여 고유벡터와 고유값을 계산하고, 이를 이용하여 주성분을 선택하고 잠재 공간으로 투영합니다. ◦ Autoencoder: 오토인코더는 입력 데이터를 잠재 공간으로 인코딩하고, 다시 재구성하는 과정을 거치면서 차원 축소를 수행합니다. 인코더 부분은 입력 데이터를 저차원으로 압축하고, 디코더 부분은 재구성을 통해 입력 데이터의 복원을 시도합니다. ◦ Word Embedding: 자연어 처리에서 사용되는 워드 임베딩은 단어를 저차원의 밀집 벡터로 투영하는 기법입니다. 이는 단어 간의 의미적 관계를 보존하면서 저차원의 표현으로 변환하여 효과적인 자연어 처리를 가능하게 합니다.
embedding layer
• 텍스트나 범주형 데이터와 같은 이산적인 데이터를 다룰 때 사용되는 층 • 일반적으로 입력으로 이산적인 값을 받고, 해당 값을 임베딩 벡터로 변환하여 출력합니다. 임베딩 벡터는 연속적인 실수 값을 가지며, 주어진 이산적인 값에 대한 고유한 표현을 가지게 됩니다. 임베딩 레이어는 학습 가능한 파라미터를 가지며, 이 파라미터는 임베딩 공간에서의 단어나 범주의 위치를 결정하는 역할을 합니다. 이러한 파라미터는 모델의 학습 과정에서 역전파(backpropagation)를 통해 업데이트됩니다. • 일반적으로 다른 층과 함께 사용되어 네트워크의 입력 데이터를 변환하거나 특성을 추출하는 데 사용됩니다. 예를 들어, 텍스트 분류 작업에서는 Embedding Layer를 사용하여 텍스트를 임베딩한 후, 해당 임베딩 벡터를 다른 층에 입력으로 제공하여 분류를 수행할 수 있습니다. • ex ◦ 자연어 처리(Natural Language Processing, NLP) 작업에서 단어의 의미와 관련된 정보를 포착하고 유사한 단어들이 비슷한 임베딩 벡터를 갖도록 만들어 줍니다. 이를 통해 모델은 단어 간의 유사성이나 의미 관계를 학습할 수 있습니다.
hidden state
• 모델이 과거의 입력 데이터를 기억하고 현재 입력에 대한 정보를 갱신하면서 내부적으로 유지하는 상태입니다. • RNN과 LSTM과 같은 모델에서 은닉상태는 시간 단계마다 업데이트되며, 현재 입력과 이전 은닉상태 간의 연산에 의해 계산됩니다. • 모델의 학습 과정에서 역전파(backpropagation)를 통해 업데이트되며, 모델의 예측 능력과 성능을 향상시키는 데 중요한 역할을 합니다. • 시퀀스 데이터나 순차적인 특성을 가진 데이터를 다루는 데 유용합니다.
teacher forcing
• RNN과 같은 시퀀스 모델을 학습시킬 때 사용되는 기법. • 훈련 과정에서 모델의 출력을 다음 입력으로 사용하는 것이 아니라, 실제 정답(타겟) 시퀀스를 다음 입력으로 주입하여 모델을 훈련하는 방법. ◦ 더 빠르고 안정적으로 모델이 학습됨. • 훈련과 테스트 단계에서 입력 데이터의 차이가 발생할 수 있으므로, 테스트 단계에서는 모델의 출력을 다음 입력으로 사용하는 “자기 회귀” 방법을 사용하여 시퀀스를 생성합니다.
BLEU(bilingual evaluation understudy)
• 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법.
RLHF(Reinforcement Learning with Human Feedback)
• 강화학습에 인간의 피드백을 포함시켜 학습하는 방법. • 일반적인 강화학습은 에이전트가 환경과 상호작용하면서 시행착오를 거치며 스스로 학습을 진행하는 방식이지만, RLHF는 인간의 전문가가 직접 에이전트의 동작에 대한 피드백을 제공하는 방식입니다. • chatGPT 학습에 사용됨.
epsilon-greedy
• 강화학습에서 사용되는 가장 기본적인 탐색(Exploration)과 활용(Exploitation) 전략 중 하나입니다. 에이전트가 환경과 상호작용하며 어떤 행동을 선택할지 결정하는데, 이러한 행동 선택을 조절하는 방법입니다. • 초기에는 탐색을 위해 무작위 행동을 많이 선택하다가, 학습이 진행됨에 따라 점점 더 많은 활용적인 행동을 선택하게 됩니다. • epsilon-softmax : epsilon-greedy의 확장으로, 더 부드러운 확률 분포를 생성하여 탐색과 활용을 더 세밀하게 조절하는 방법. • 알고리즘 동작 ◦ 입실론 값(ε)을 정합니다. 이 값은 일반적으로 0과 1 사이의 작은 양수입니다. ◦ 환경과 상호작용하면서, 무작위로 0부터 1 사이의 수를 생성합니다. ◦ 생성된 수가 ε보다 작으면 무작위로 행동을 선택합니다. 이는 탐색을 의미합니다. ◦ 생성된 수가 ε보다 크거나 같으면 현재 상태에서 가장 높은 보상을 가진 행동을 선택합니다. 이는 활용을 의미합니다.
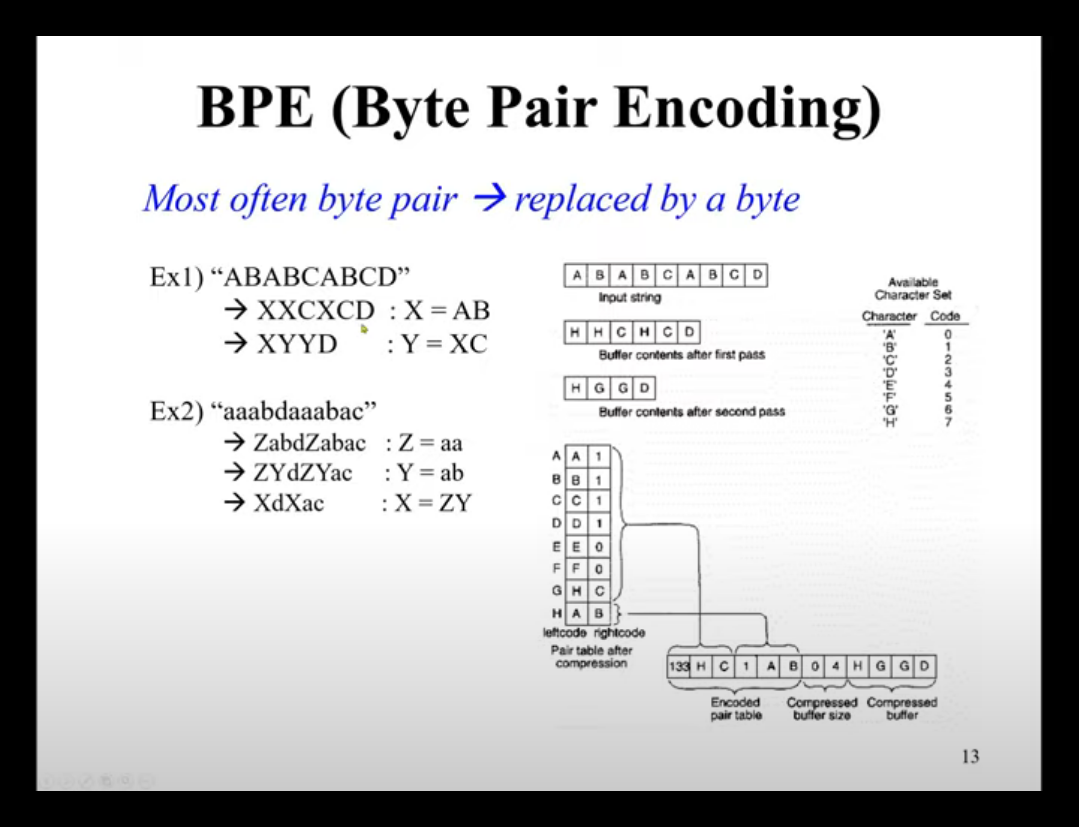
BPE(byte pair encoding)
• 데이터의 압축과 토큰화를 동시에 수행하는 기법입니다. 특히 자연어 처리(Natural Language Processing, NLP) 분야에서 주로 사용되며, 텍스트 데이터를 처리하기 전에 단어나 서브워드(Subword) 수준의 토큰으로 분할하는 데 사용됩니다. • 데이터의 특성에 따라 자동으로 서브워드 단위로 분할하므로, 기존의 단어 토큰화보다 더 세밀한 토큰화를 제공합니다. • OOV(Out-of-Vocabulary)에 대한 처리와 띄어쓰기가 없는 언어에서 유용하게 사용됩니다. • 자연어 처리 모델에서의 성능을 향상시키고, 번역, 감정 분석, 자연어 이해 등 다양한 NLP 작업에서 많이 사용되는 중요한 전처리 기법 중 하나입니다. • BPE를 참고하여 만들어진 Wordpiece Tokenizer나 Unigram Language Model Tokenizer와 같은 서브워드 분리 알고리즘이 존재합니다. ◦ wordpiece tokenizer : BPE가 빈도수에 기반하여 가장 많이 등장한 쌍을 병합하는 것과는 달리, 병합되었을 때 코퍼스의 우도(Likelihood)를 가장 높이는 쌍을 병합합니다.( BERT를 훈련하기 위해서 사용) ◦ Unigram Language Model Tokenizer : 각각의 서브워드들에 대해서 손실(loss)을 계산합니다. 여기서 서브 단어의 손실이라는 것은 해당 서브워드가 단어 집합에서 제거되었을 경우, 코퍼스의 우도(Likelihood)가 감소하는 정도를 말합니다. 이렇게 측정된 서브워드들을 손실의 정도로 정렬하여, 최악의 영향을 주는 10~20%의 토큰을 제거합니다. 이를 원하는 단어 집합의 크기에 도달할 때까지 반복합니다. • 단계 ◦ 데이터 압축: 주어진 텍스트 데이터를 바이트 또는 유니코드 단위로 분할하여 각 바이트 또는 유니코드 문자들을 토큰으로 인식합니다. ◦ 빈도수 기반 토큰화: 데이터에서 발생하는 모든 토큰들의 빈도수를 계산합니다. 이후에는 가장 빈도수가 높은 토큰들을 하나의 토큰으로 결합합니다. ◦ 반복적인 토큰 결합: 일정 횟수나 빈도수 이상으로 반복하여 가장 빈도수가 높은 토큰들을 합치고 새로운 토큰으로 대체합니다. 이 과정을 원하는 토큰 개수가 나올 때까지 반복합니다. ◦
memory network
• 자연어 처리와 같은 기계 학습 작업에 활용되는 인공 신경망의 한 종류입니다. • 신경망 모델 내부에 외부 메모리 구조를 가지고 있으며, 이를 활용하여 입력 정보를 보존하고 필요에 따라 엑세스하면서 학습하는 방식으로 동작합니다. • 주로 질의 응답(Question Answering), 기계 번역, 대화 시스템 등에서 활용되며, 특히 복잡하고 긴 문장을 다룰 때 유용합니다. • 입력과 출력 사이에서 메모리 구조를 이용하여 중간 정보를 보존하고 활용함으로써 복잡한 문제를 해결하는데 도움이 됩니다. • 정보의 보존과 엑세스를 제어하는 메커니즘을 통해 더 효과적인 학습과 추론이 가능해지는 장점이 있습니다.. 이를 통해 질문에 더 정확하고 자연스러운 응답을 제공하는 인공 지능 시스템을 개발할 수 있습니다. • 구조와 동작 방식 ◦ 외부 메모리: ▪ 메모리 네트워크는 외부 메모리 구조를 가지고 있습니다. 이 메모리에는 모델이 학습한 정보를 저장하고, 추후에 해당 정보를 재활용하여 질의나 요청에 응답합니다. ◦ 입력 인코딩: ▪ 메모리 네트워크는 입력 정보를 인코딩하여 메모리에 저장합니다. 주로 입력 문장의 각 단어를 임베딩(Embedding)하여 표현하고, 이를 메모리에 저장합니다. ◦ 질의 인코딩: ▪ 사용자가 제공한 질의나 요청을 인코딩하여 메모리에서 관련된 정보를 검색합니다. 이를 위해 질의 문장의 단어들도 임베딩되어 메모리에 접근할 준비가 됩니다. ◦ 메모리 엑세스: ▪ 질의 인코딩 결과를 활용하여 메모리에 저장된 정보를 접근하고, 질의와 관련된 정보를 찾습니다. 이를 통해 메모리에 저장된 지식을 활용하여 질의에 대한 응답을 찾습니다. ◦ 출력 디코딩: ▪ 메모리 네트워크는 메모리 엑세스를 통해 얻은 정보를 활용하여 질의에 대한 출력을 생성합니다. 출력은 주로 문장, 단어, 레이블 등의 형태로 나타납니다.
autoregressive
• 시퀀스 모델링의 한 방법을 나타내는 용어. • 출력 시퀀스를 한 단계씩 생성하는 동안 이전에 생성한 부분을 고려하는 모델입니다. • 번역, 텍스트 생성, 음성 합성 등의 다양한 시퀀스 생성 작업에 활용. • 주요 특징 ◦ 단계적 생성: 출력 시퀀스를 한 단계씩 생성합니다. 이전 스텝에서 생성한 결과를 입력으로 활용하여 다음 스텝에서 새로운 부분을 생성합니다. ◦ 자기회귀 방식: “자기회귀”(Autoregressive)라는 이름은 모델이 자신의 출력을 이용하여 다음 출력을 생성한다는 특징을 나타냅니다. ◦ 학습과 샘플링: 학습 단계에서는 실제 출력과 실제 타겟을 비교하여 모델을 최적화합니다. 그러나 샘플링 단계에서는 모델이 이전 출력을 사용하여 다음 출력을 샘플링하고, 이렇게 반복하여 원하는 길이의 시퀀스를 생성합니다. ◦ 예시: 자연어 처리에서 Autoregressive 모델의 대표적인 예로는 GPT-2, GPT-3와 같은 GPT 계열의 모델이 있습니다. 이 모델들은 Transformer 아키텍처를 기반으로 하며, 텍스트를 자동으로 생성하는데 매우 강력한 성능을 보입니다. • 장점 : 이전 정보를 활용하므로 문맥을 고려하여 자연스러운 결과를 생성하는 데 효과적입니다. • 단점 : 생성 과정이 순차적이기 때문에 병렬 처리가 어려워 학습과 추론이 비교적 느릴 수 있다는 점이 있습니다.