overfitting
- 모델이 학습 데이터에 너무 과도하게 적합되어 일반화 성능이 저하되는 현상
- 모델이 학습 데이터의 잡음(noise) 이나 이상치(outlier)에 과도하게 반응하여 그에 맞게 학습되기 때문
- 보통 더 많은 주의를 기울이고 해결에 공을 들임
- 언더피팅은 훈련 과정에서 바로 모델이 멍청하다는 걸 발견하지만, 오버피팅은 현장투입까지는 확인이 어려움.
- 현대의 고성능 모델은 데이터의 아주 미세한 패턴까지 학습할 수 있는 강력한 능력을 갖추므로, 성능을 최대한 끌어올리려다 보면 필연적으로 오버피팅의 경계선에 닿게 됨
- 오버피팅된 모델은 “시험 공부는 완벽하게 해서 기출문제는 다 맞히는데, 정작 수능(새로운 데이터)에서는 낙제하는 학생”과 같으며, 이는 서비스의 신뢰도를 심각하게 손상시킴
일반적인 해결방안은 아래와 같다.
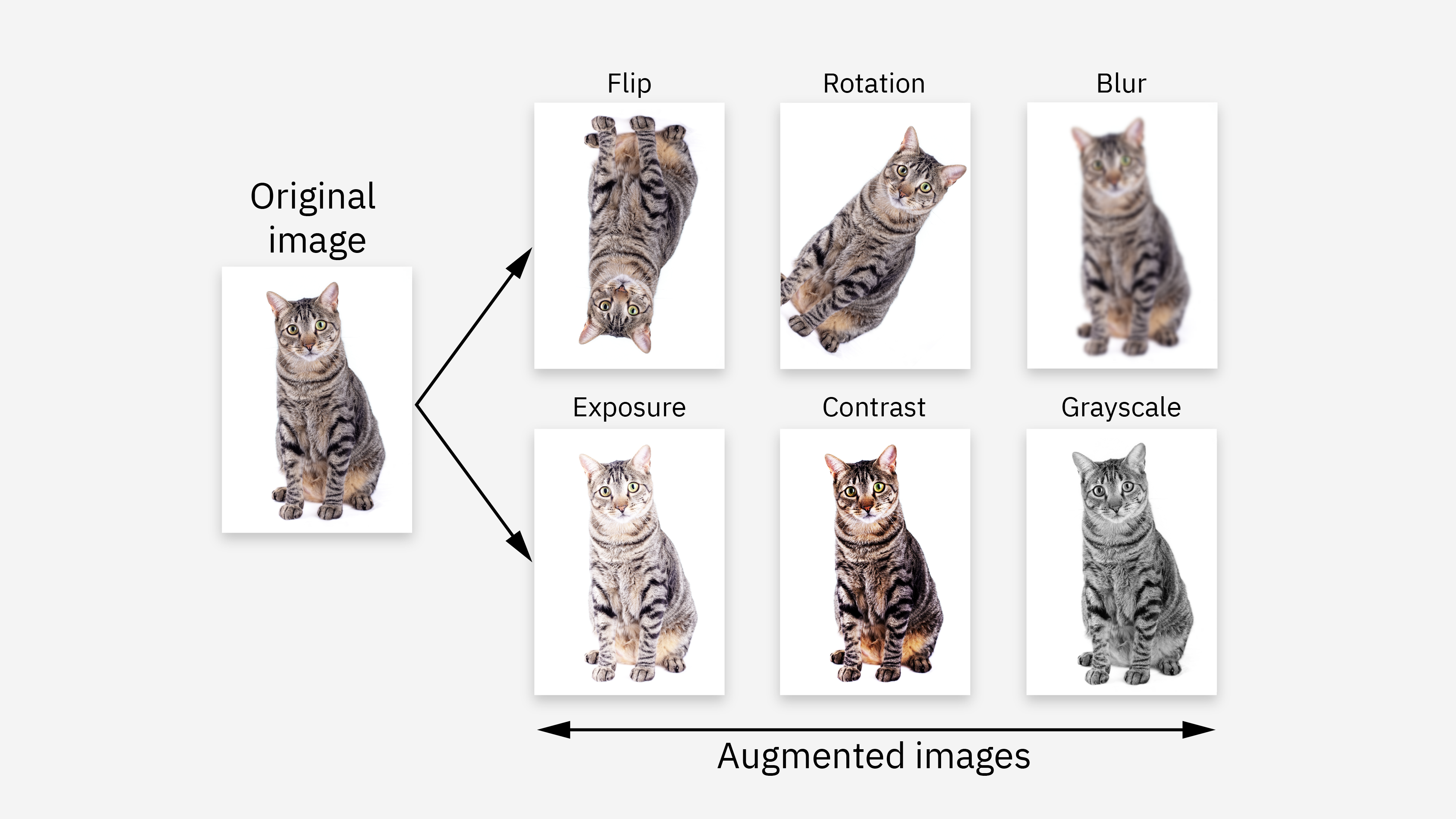
data augmentation (데이터 증강)
더 많은 훈련 데이터를 사용하는 것이 우선 첫번째.
그러나 데이터를 늘리고 싶다고 늘릴 수 있는 것이 아니므로, data augmentation 이라는 데이터 전처리 기법으로 데이터 총량을 늘림.
기존의 학습 데이터를 변형하거나 추가하여 데이터셋을 확장하는 방법으로, 모델의 성능을 향상시키고 과적합을 방지하는 데 도움이 됨.
• 예제 ◦ 이미지 : 좌우 반전, 회전, 크기 조절, 밝기 조절 등의 변형 ◦ 텍스트 : 번역 후 재번역을 통해 새로운 데이터를 만들어내는 역번역(Back Translation)
모델의 복잡도 감소
인공 신경망의 복잡도는 은닉층(hidden layer)의 수나 매개변수의 수 등으로 결정
- ex) 파라미터 수 줄이기, 특성 선택, hidden layer 줄이기
데이터 정규화 (normalization)
데이터의 스케일을 맞추거나 표준화하여 모델이 데이터의 크기나 분포에 영향을 덜 받도록 합니다.
regularization 기법 적용
• 모델의 복잡성을 제어하여 과적합(Overfitting)을 방지하는 기법 • 복잡한 모델을 좀 더 간단하게 하는 방법 • loss function에 추가적인 항을 도입하여 모델의 가중치(weight)를 제한하거나 페널티를 부과함으로써 모델의 일반화 능력을 향상 • 예제( regularization의 강도를 정하는 hyperparameter 사용됨 ) ◦ L1 Regularization은 가중치의 절댓값에 비례하는 페널티를 부과합니다. 이로써 가중치 값 중 일부가 0이 되면서 특성 선택(feature selection)의 효과를 가져올 수 있습니다. ▪ 어떤 특성들이 모델에 영향을 주고 있는지를 정확히 판단하고자 할 때 유용 ◦ L2 Regularization은 가중치의 제곱에 비례하는 페널티를 부과합니다. 이로써 가중치 값들이 전반적으로 작아지고, 모든 특성들이 약간의 기여를 할 수 있게 됩니다. ▪ 인공 신경망에서 L2 규제는 weight decay라고도 부릅니다.
dropout (딥러닝 only)
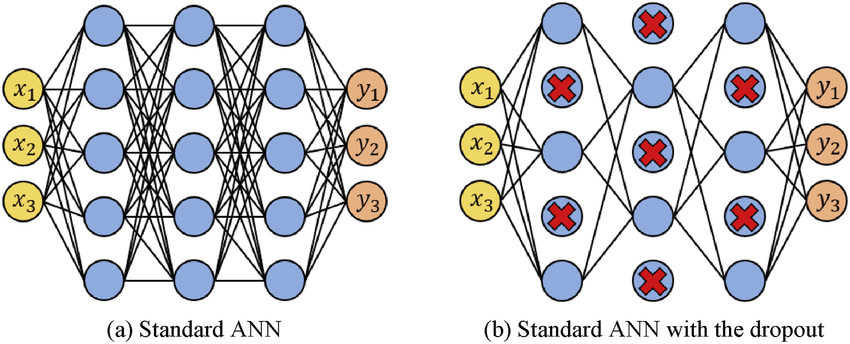
- 과대적합 방지를 위해, 신경망 훈련 과정에서 무작위로 일부 뉴런을 제외
매 훈련 이터레이션마다 새롭게 적용
- 첫 번째 이터레이션에서 제외한 뉴런을 두 번째 이터레이션에서는 포함할 수 있음
- 그 반대도 가능
매번마다 서로 다른 신경망을 훈련하는 꼴 서로 다른 신경망을 훈련하여 결과를 취합하는 기법인 앙상블 학습과 유사 드롭아웃을 적용하면 앙상블 효과가 나서 과대적합을 막을 수 있고, 성능 향상에도 도움이 된다
얼마나 많은 뉴런을 드롭아웃 할지는 하이퍼파라미터로 설정 (0.2로 설정하면 전체 뉴런의 20% 를 제외)
드롭아웃은 훈련 단계에서만 적용한다. 검증 / 예측 단계에서는 훈련된 뉴런을 모두 사용해야 하므로, 사용하지 않음
• 신경망 학습 시에만 사용하고, 예측 시에는 사용하지 않는 것이 일반적. • 학습 시에 인공 신경망이 특정 뉴런 또는 특정 조합에 너무 의존적이게 되는 것을 방지해주고, 매번 랜덤 선택으로 뉴런들을 사용하지 않으므로 서로 다른 신경망들을 앙상블하여 사용하는 것 같은 효과를 내어 과적합을 방지
교차검증 (cross-validation, CV)
- 교차검증 을 통한 모델 평가 (cross-validation)
조기 종료
검증 데이터의 성능이 최적일 때 학습을 종료하여 모델이 과적합되는 것을 방지합니다.
앙상블
여러 개의 다른 모델을 결합하여 예측 결과를 종합함으로써 일반화 성능을 향상시킵니다.
underfitting
• 모델이 학습 데이터에 대해 너무 단순하거나 제대로 학습하지 못해 새로운 데이터에 대해 부족한 성능을 보이는 현상. 즉, 모델이 데이터의 패턴을 충분히 학습하지 못해 예측력이 낮아지는 것을 의미 • 특징 ◦ Training 데이터에서의 성능이 낮음: 모델이 학습 데이터에서도 좋은 성능을 발휘하지 못하고, 오차가 크게 나타납니다. ◦ Validation 데이터에서의 성능도 낮음: 모델이 학습 데이터 외의 데이터에 대해서도 성능이 낮게 나타납니다. 즉, 일반화(generalization) 능력이 부족합니다. • underfitting 해결 방안 ◦ 모델의 복잡도 증가 (예: 더 많은 은닉층, 더 많은 유닛) ◦ 더 많은 특성(feature) 사용 ◦ Feature Engineering: 더 좋은 특성(feature)을 추출하거나 유용한 특성을 생성하여 모델에 입력합니다. 좋은 특성은 모델이 데이터의 패턴을 더 잘 파악할 수 있도록 도와줍니다. ◦ 더 많은 학습 데이터 수집: 학습 데이터의 다양성과 양을 증가시켜 모델이 더 정확하게 데이터의 패턴을 학습하도록 합니다. ◦ 학습 알고리즘 변경 또는 하이퍼파라미터 조정 ◦ Regularization: 모델의 복잡성을 제어하기 위해 Regularization 기법을 사용합니다. Regularization은 모델의 가중치를 제한하거나 패널티를 부여하여 모델의 일반화 성능을 향상시키는 방법입니다.