- 서포트 벡터 머신
- 패턴인식, 자료분석 등을 위한 지도학습 머신러닝 모델
- 회귀와 분류 문제해결에 사용
- 주어진 데이터 집합을 바탕으로 하여, 새로운 데이터가 어떤 범주에 속할 것인지를 판단하는, 비확률적 이진 선형 분류 모델을 생성
- 기존 분류기: 오류율 최소화를 특징
- SVM: 마진 최대화로 일반화 능력의 극대화를 추구
- 마진이 가장 큰 초평면을 분류기 (classifier) 로 사용할 때, 오분류가 가장 낮아진다
원리
-
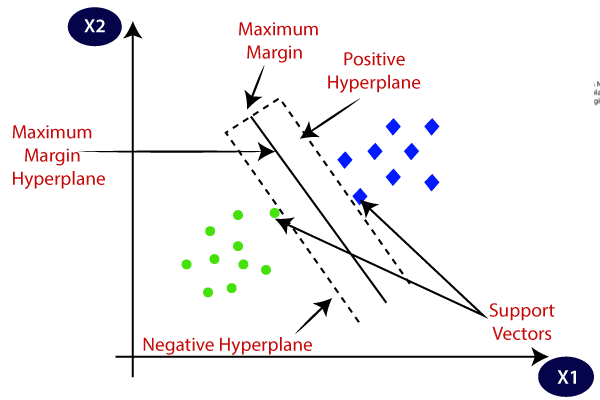
결정 초평면 (decision hyperline): 데이터의 각 그룹을 구분하는 분류자
- 초평면: 데이터의 차원 공간보다 한 차원이 낮은 차원의 하위공간 (subspace)
-
서포트 벡터 (support vector): 각 그룹에 속한 데이터들 중, 초평면에 가장 가까이 붙어있는 최전방 데이터 (결정경계를 지지, support)
-
마진 (margin): 서포트 벡터와 초평면 사이의 수직거리
분류되지 않은 새로운 값이 입력되면, 경계의 어느쪽에 속하는지를 확인하여 분류 과제를 수행한다.
- SVM 은 두 집단에 속한 각 데이터를 사이에서, 가장 큰 폭을 가진 경계를 찾는다.
- SVM 은 이와 같이 고차원 혹은 무한차원의 공간에서 마진을 최대화하는 초평면 (MMH, Maximum Margin Hyperplane, 최대 마진 초평면) 을 찾아 분류와 회귀를 수행한다.
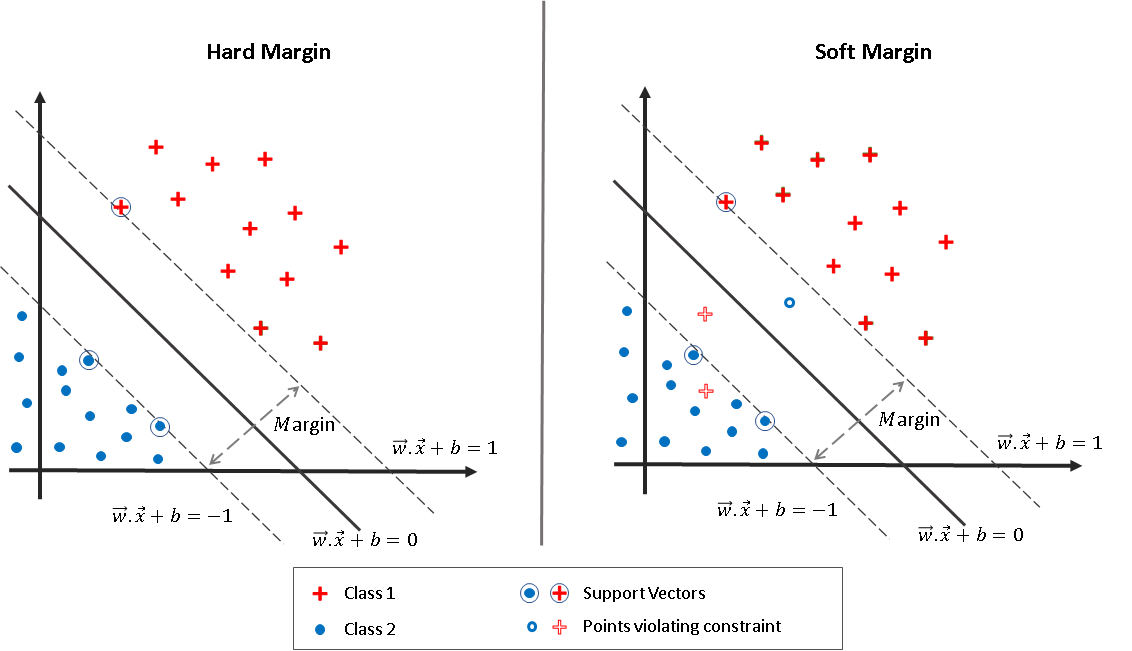
적절한 마진의 선택
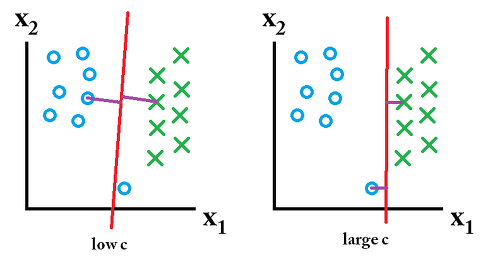
자신의 클래스가 아닌 다른쪽 클래스 근처에 위치한 이상치가 존재하는 상황. 이럴 경우에는 분류 경계면을 찾을때 약간의 오류를 허용하기 위한 파라미터 cost () 를 활용한다.
C는 데이터가 다른 클래스에 놓이는 것을 허용할 정도를 결정한다. C값은 제약조건의 강도이다. C값이 작으면 이상치가 존재할 가능성을 많이 허용하여 더욱 일반적인 경계면을 찾는다. C값이 크면 이상치의 존재 가능성을 적게 허용하여 더욱 세심한 분류 경계면을 찾는다.
-
하드 마진
- C값을 크게 설정하여 데이터들이 마진 안에 포함되는 것을 허용하지 않는다.
- 매우 좁은 마진을 가지며, 실전에선 모든 관측치를 완벽하게 분류하는 초평면은 존재하지 않을 수 있다.
- 이상치를 허용하지 않는 기준으로 결정경계를 잡으면 overfitting 이 터질 수 있다.
-
소프트 마진
- C값을 작게 설정하여 데이터들이 마진 안에 포함되는 것을 어느정도 허용한다.
- 서포트 벡터와 결정경계 사이의 거리가 멀어져서 마진이 큰 일반적인 분류 경계를 생성한다.
- 지나치게 많은 이상치를 허용하면 과소적합이 터질 수 있다.
커널 (Kernel)
SVM 은 선형 분류만이 아니라 비선형 분류에도 쓰일 수 있다. 이때는 입력자료를 다차원 공간으로 mapping 하여 해결할 수 있다. 이 과정에서 커널 함수를 이용해 계산량을 줄이는 기법인 커널 트릭 (kernel trick) 이 사용된다.
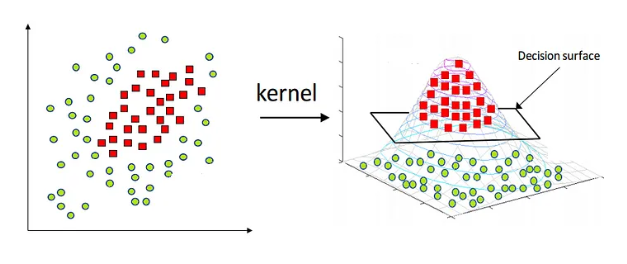
- 3차원 공간에 매핑한 후 2차원 공간으로 역매핑하면, 결정경계는 원과 같은 비선형의 꼴을 띤다.
- 비선형 데이터 분류 문제를 위해 사용할 수 있는 커널 트릭의 종류
- 각 커널마다 최적화를 도와주는 매개변수를 갖는다.
- 선형 커널
- 다항식 커널
- 시그모이드 커널
- 가우시안 RBF 커널: 성능이 좋아 가장 많이 쓰인다. 패러미터 를 통해 결정 경계의 곡률을 조정해 분류 경계면을 최적화한다.
장단점
| 장점 | 단점 |
|---|---|
| 분류와 예측에 모두 사용 가능 | 데이터 전처리와 매개변수 설정에 따라 정확도가 달라질 수 있음 |
| 신경망 기법에 비해 과적합 정도가 낮음 | 예측이 어떻게 이루어지는지에 대한 이해와 모델에 대한 해석이 어려움 |
| 예측의 정확도가 높음 | 대용량 데이터에 대한 모형 구축 시 속도가 느리며, 메모리 할당량이 큼 |
| 저차원과 고차원의 데이터에 대해 모두 잘 작동 | |
| 비선형 분리 데이터를 커널트릭을 사용해 분류 모델링 가능 |