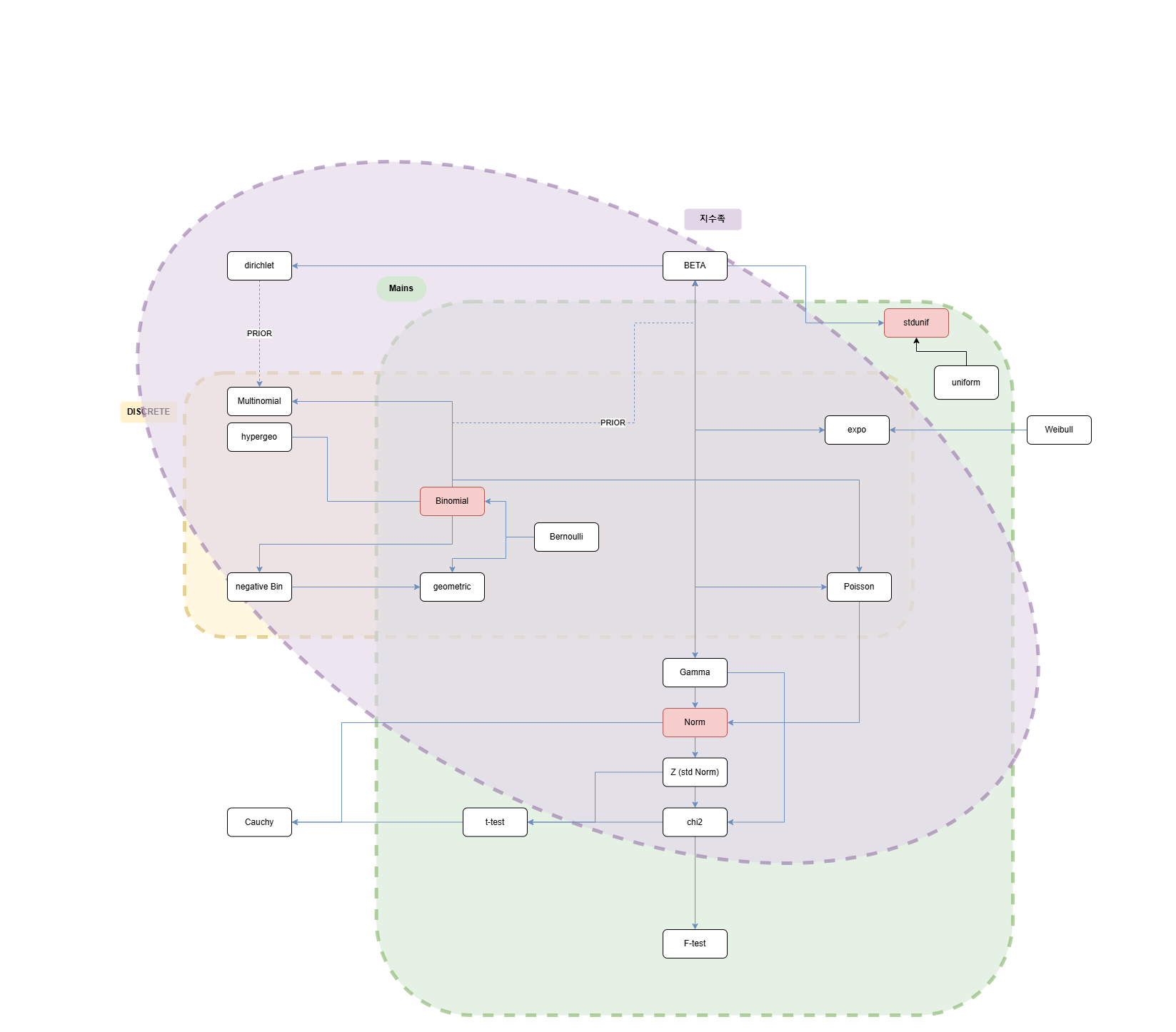
지나치게 세분화된 피처를 더 큰 분류로 묶으면 성능이 좋아지는 경우가 있다.
훈련 데이터에는 매월 1일부터 19일까지의 데이터가 있다. 20일부터 월말까지의 데이터는 테스트 데이터에 있다. 따라서 일자는 피처로 사용할 수 없다. day 를 피처로 사용하려면 훈련 데이터와 테스트 데이터에 공통된 값이 있어야 하므로.
원핫인코딩은 sparse matrix 를 만든다. 메모리 낭비가 심하므로 행렬 형식을 변환한다. 대표적으로 COO (coordinate list), CSR (compressed sparse row) CSR 이 메모리를 더 적게 쓰면서 연산이 빠름.
파생피쳐) 하나의 row 가 가진 결측값 개수 파생피쳐) 명목형 피처의 고윳값별 개수
앙상블은 성질이 서로 다른, 다양한 모델로 진행되어야 의미가 있다.
피쳐 조합의 특정 조합의 판매량이 0이더라도 있는게 낫다. 아예 조합이 데이터에 존재하지 않을 경우 생성한다.
from itertools import product
items = [df['col1'].unique(), df['col2'].unique(), df['col3'].unique()]
all_combinations = list(product(*items))
값을 하한값과 상한값에서 잘라내는 기법을 clipping 이라고 한다.
np.clip(minval, maxval) # minval 미만이면 minval, maxval 이상이면 maxval
np.clip(a, 0, None) # 0보다 작은 값만 0으로 바꾸고, 큰 값은 무제한 허용.
np.clip(a, None, 100) # 100보다 큰 값만 100으로 바꾸고, 작은 값은 무제한 허용import gc
del var0
gc.collect()LightGBM 에서, 고윳값 갯수가 너무 많은 범주형 데이터는 수치형 데이터로 취급해야 성능이 더 잘 나온다. 범주형 데이터는 고윳값 하나하나가 일정한 의미를 갖는데, 그 고윳값이 너무 많아져버리면 고윳값이 갖는 의미가 상쇄된다. 따라서 수치형 데이터와 별반 차이가 없어짐.
레이블 인코딩은 단점이 있다. 서로 가까운 숫자를 비슷한 데이터로 판단하여 성능을 떨어트릴 수 있다. 그런데 트리 기반 모델을 사용할 땐 레이블 인코딩을 해도 큰 차이가 없다. 트리 기반 모델 특성상 분기를 반복하면서 피처 정보를 반영하므로 레이블 인코딩의 단점이 어느정도 무마된다.
고윳값이 5개 미만인 대분류는 모두 ‘etc’로 바꾼다. 대분류 하나가 범주를 일정 개수 이상을 갖는게 성능 향상에 유리하기 때문.
시차 피처 (time lag feature) 는 과거 시점에 관한 피처로, 시계열 문제의 성능 향상에 도움되는 경우가 많다.
훈련 데이터에서 테스트 데이터에 있는 상점ID만 추출하면 성능이 더 좋아진다. 데이터가 많다고 무조건 좋은 것이 아닏. 꼭 필요한 데이터가 있어야 한다. 이러한 방법은 테스트 데이터가 고정되어 있는 경우에만 유효하다. 테스트 데이터가 변할 수 있는 현업에는 적절하지 않다. 테스트 데이터에 있는 피처만 추출해서 훈련한 모델은 일반적인 상황에서 범용적으로 사용할 수 있는 모델이 아니다. 반면 캐글에서는 테스트 데이터가 고정되어 있으니 성능 향상을 위해 고려해볼만 하다.
sales_train[sales_train['상점ID'].isin(unique_test_shop_id)]데이터 로더는 지정한 배치 크기만큼만 데이터를 부러오는 객체. 배치 크기는 보통 4~256. 배치 크기가 작으면 규제 효과가 있어 일반화 성능이 종하진다. 단, 한번에 불러오는 데이터가 적어 훈련 이터레이션이 많아지고 훈련시간도 길어진다. 게다가 배치 크기가 작을수록 학습률도 작게 설정해야 하는데, 훈련 시간을 지연시키는 또다른 원인. 배치 크기는 2의 제곱수로 설정하는게 효율적.
에폭은 ‘훈련 데이터 전체’ 를 한번 훑었음을 뜻함. (문제집 1권을 다 풀었다) 그런데 신경망 가중치가 최적화되기에는 1에폭만 훈련해서는 부족하다. 보통 수십~수백 에폭만큼 훈련을 진행한다. 훈련 데이터 전체를 여러차계 반복 훈련 (같은 문제집을 반복해서 풀면 시험성적이 올라간다) 에폭이 너무 적으면 과소적합, 너무 많으면 과대적합
배치크기는 매 훈련 이터레이션에서 한번에 훈련할 데이터 개수. 배치크기가 32면, 훈련 데이터 32개를 한 묶음으로 보고 가중치를 함께 갱신하겠다는 뜻.
반복횟수는 1에폭의 훈련을 완료하는데 필요한 훈련 이터레이션. 간단하게 훈련 데이터 크기를 배치 크기로 나누면 된다. (소수점은 올림 처리)
반복횟수 = 훈련 데이터 개수 / 배치 크기
상태 설정과 기울기 계산 비활성화
신경망 모델은 훈련 단계와 평가 단계에서 상태가 서로 다르다.
예를 들어 피팅 > dropout (딥러닝 only) 은 훈련 단계에서만 적용해야 한다.
따라서 model.eval() 을 실행하면 평가 상태라고 인식해서 모델이 드롭아웃을 적용하지 않는다.
이번 모델에서는 드롭아웃 / 배치정규화를 적용하지 않아 model.eval() 을 사용하지 않더라도 결과에 차이는 없다.
하지만 나중에 코드를 수정할 수도 있으므로 평가 단계에서는 무조건 model.eval() 을 적용하는 습관을 들이는 것이 좋다.
with torch.no_grad() 는 범위 내의 코드에서 기울기 계산을 비활성화한다.
평가 단계에서는 역전파를 쓰지 않아 기울기를 계산할 필요가 없기 때문이다. (역전파는 훈련 단계에서만 적용)
물론 backward() 메서드로 역전파를 한적이 없다면 torch.no_grad() 가 없어도 결과에 영향은 없다. 기울기를 계산한 뒤 역전파를 실행해야 가중치가 갱신되므로.
그럼에도 torch.no_grad() 를 적용하는 이유는 필요없는 계산을 피해 메모리를 아끼고 속도를 높이기 위함이다.
tensor.tolist() albumentations
이미지 크기를 키우면 (3232 -> 800800) 성능이 증가하기도 함
이미지 변환기 albumentation
efficientnet
tqdm
성능개선
- 에폭 늘리기
- 스케쥴러 추가
- TTA (테스트 단계 데이터 증강) 기법
- 레이블 스무딩 적용
스케쥴러는 훈련 과정에서 학습률을 조정하는 기능을 제공. 훈련 초반에는 학습률이 큰게 좋다. 빠르게 가중치를 갱신하기 위해. 그러다가 훈련을 진행하면서 학습률을 점차 줄이면 최적 가중치를 찾기가 더 수월하다. 골프를 생각하면 이해가 쉬움. 처음에는 공을 강하게 쳐서 멀리 날아가게 한다. 홀과 가까울수록 약하게 쳐서 조금씩 움직이게 한다.
새로운 예측기법)
- TTA
- 테스트 단계에서 활용하는 데이터 증강 기법
- 테스트 데이터를 여러차례 변형한 뒤 예측함. 마치 테스트 데이터가 늘어난 효과를 얻는다.
- 테스트 데이터에 여러 변환을 적용한다 -> 변환된 테스트 데이터별로 타겟 확률값을 예측한다 -> 타겟 예측 확률의 평균을 구한다
- 이렇게 구한 평균 확률을 최종 제출값으로 사용한다. 앙상블 효과가 있어 한차례만 예측할때마보다 성능이 좋아질 가능성이 높다. TTA 는 보통 5번~10번.. 반복하면 소요 시간 대비 효과가 미미하다.
- 레이블스무딩
- 딥러닝 모델이 과잉확신하는 경우가 있다. 확신이 과하면 성능이 떨어질 우려가 있다. 과잉 확신한 예측값을 보정하는 것.
- , preds 는 예측 확률값, alpha 는 레이블 스무딩 강도, K 는 타깃값 개수. 모델이 예측한 확률을 감쇠시키고, uniform 만큼 보정함
- 훈련 데이터를 100% 활용 (k-fold 의 의도적 off)
albumentation 변환기를 사용하지 않는 이유는 imagefolrder 때문. imagefolder 는 데이터셋을 만들어주는 라이브러리인데, torchvision.transforms 로 만든 변환기를 받도록 설계되어 있음.
훈련함수 직접 작성.
초기 최소 손실값은 무한대로 설정한다. 에폭 1에서 검증 데이터 손실값은 2.0. 2.0은 무한대보다 작으므로 최소 손실값을 2.0으로 갱신 후, 이때의 모델 가중치를 저장. … 마지막 에폭까지 반복. 그러면 모든 에폭 중 검증 데이터 손실값이 가장 작은 에폭에서의 모델 가중치가 저장되어 있다.
머신러닝 경진대회에서 배운 조기종료와의 차이점. 조기종료는 평가점수가 더이상 좋아지지 않으면 훈련을 멈췄다. 지금은 훈련을 끝까지 진행하되, 가장 성능이 좋았던 에폭에서의 모델 가중치를 기억하는 방식.
EfficientNet
꼭 복잡한 모델이 성능이 좋은 것은 아니다. 다이너마이트가 땅을 파는데 효과적이나, 나무 한그루를 심을때 다이너마이트를 사용하지는 않듯이.
데이터 다운캐스팅
torch.save from_pretrained
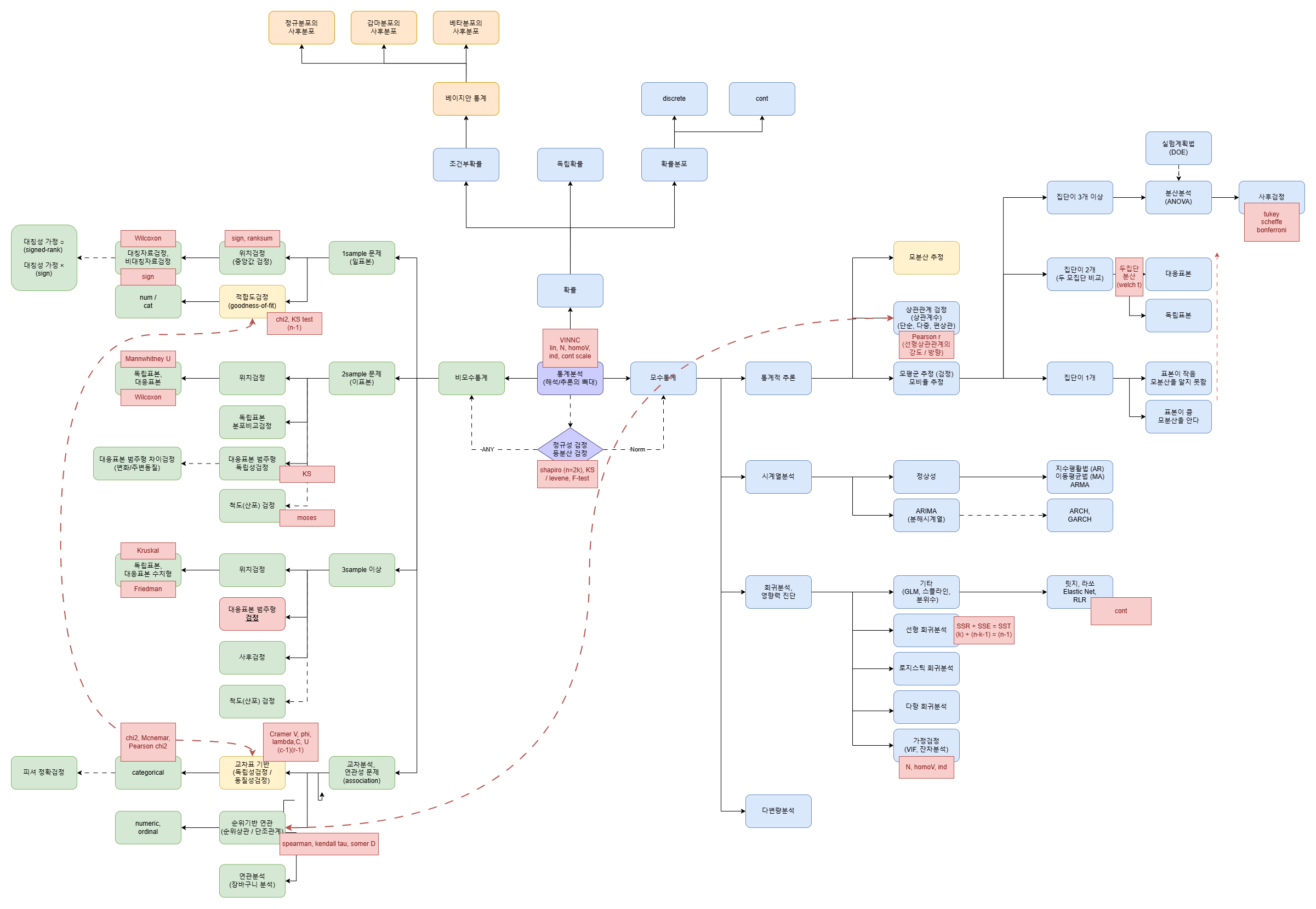
| 모수 | 모집단 수 | 비모수 |
|---|---|---|
| 1 sample t | 1 pop | sign, signrank |
| ind t | 2 pop | ranksum, Mann U |
| rel t | 1 pop 전후 | signrand |
| ANOVA | 3+ pop | Kruskal, Friedman |
z: 표본이 모집단에 속하는가 t: 두 집단의 평균값 차이
여기서 thm 5.1. 과 복합하는 것으로 이하를 얻을 수 있음.
분포검정의 의미
통계 분포라는 건 결국 현실의 임의의 사상 (event) 가 어떤 규칙을 따를 것이라는 가설을 뒷받침하는 것.
노멀분포.
세상에는 노멀분포를 따르되 평균이 이 아닌 거나, variance 가 이 아닌 일 수 있음.
하지만 얘들은 결국 근본으로 돌아가면 노멀분포를 따른다는 점에서 과 같은 것이고.
- = 표준화를 거치면 노멀분포로 환원 가능.
가설이란 해당 사상 (event) 는 노멀 분포를 따를 것 같은데? 라는 게 가설.
노멀 분포를 따른다면 시행횟수를 늘렸을 경우 결과값들의 집합 (set) 이 노멀 분포를 따르는 모양이 나오는게 정상이겠지?
근데 안따르네?
이거 우리 모두 착각하던거 아님? 사실 노멀분포 안따르는거 아니냐고!
노멀분포 따르면 양심적으로 결과값들을 정리했을 때 이 영역 안에는 있어야지. 없잖아!!
체크하고자 하는 것은 바로 이 부분.
즉 일반적인 분포 검정 (test) 에서 우리는 기본적으로 해당 사상이 노멀분포를 따를 것이라는 가정을 깔고 들어간다. 그게 상식이니까.
근데 노멀분포를 안 따르고 있을 경우, 그 ‘상식’ 에 기반하면 당연해야 하는 일들이 당연하지 않다는 결과값이 나올 것이고, 그제서야 우리는 노멀분포가 아닌 다른 가능성에 무게를 두는 것.
자유도란?
제약조건(반드시 맞아야 하는 조건)들을 고려했을 때, 독립적으로 움직일 수 있는 정보 조각의 개수.
표준정규 를 따르는 확률변수 를 개 합한다. 이때 이 합이라는 확률변수는 를 따르며, 이 가 자유도가 된다.
즉, , 즉 dof 는 “독립인 표준정규 성분이 몇 개 들어갔는가” 를 의미한다.
이제 contingency table 기준으로 생각해보자.
3×3 독립성 검정을 예로 들자. 여기서 정해져야 하는 값의 갯수는 이다. 9개 셀에 대해 값을 채워넣어야 하니까. 근데.
rowsum 개 중 마지막 1개는 앞의 개가 정해지면 자동으로 결정된다. 값의 총합 은 고정되어 있으니까.
colsum 개도 마찬가지로 개만 독립이다.
자유도가 n-1 인 이유
‘추정’을 진행할 때, 자유도는 왜 차감되는가?
수식으로는 아주 간단하다.
즉 로 나누어져야 분산의 불편추정량 (unbiased estimator, UE) 로서 성립한다.
참고
반면 MLE처럼 분모를 으로 두면 하향편향이 생긴다. 평균 를 데이터에서 추정하면서 자유도 1을 ‘소모’했기 때문.
참고로 회귀처럼 모수 개를 추정하면 같은 논리로 자유도가 로 일반화된다.
직관을 붙이면, 직관은 잘 작동하지 않는다. 이건 이미 발생한 현실계 기준 이 아니라, 표본을 뽑는다는 행위를 추상화한, 아직 행동이 발생하지 않은 추상계 기준 이기 때문이다.
즉, 자유도는
- 이미 실현된 데이터에 대한 조작 가능성이 아니라,
- 제약이 걸린 확률모형에서 독립적으로 변할 수 있는 성분의 개수 를 말한다.
원래 표본 은 서로 독립이어서 개의 자유정보를 갖는다. 하지만 이렇게 보유하고 있는 정보덩어리에서 분산을 구하기 위해선 평균이 무조건 있어야 하므로, 어쩔 수 없이 평균 를 데이터에서 추정했다. 이러면 ‘잔차들의 합은 0’ 이라는 제약이 생긴다.
즉,
당연하다. 평균 를 개 합하면 의 합과 같으니까. 즉 이건 데이터에서 평균을 ‘추정’ 한 순간 피할 수 없는 제약이다.
따라서 이 제약은 독립적으로 변할 수 있는 임의성(정보) 를 정확히 1개 줄인다. 따라서 개만 독립적으로 변할 수 있고, 나머지 하나는 자동 결정된다.
근본적으로 ‘마음대로 고른다’는 건, 모든 가능한 표본을 상상할 때, 제약을 제외하면 독립적으로 바뀔 수 있는 성분의 수가 라는 의미이다.
- 한 번 관찰된 데이터에서 뭔가를 바꿀 수 있다는 뜻이 아니다.
선형대수 관점: 잔차 벡터가 사는 공간의 차원
잔차벡터 는 항상 아래를 만족한다. 즉, 는 에 수직인 부분공간 에 산다.
전체 공간 의 차원은 , 그중 방향(평행이동) 1차원을 “평균 맞추기”로 고정했으니, 남는 부분공간의 차원은 n-1. 이것이 자유도가 된다.
- 회귀일반화: 설계행렬 가 열랭크 이면, 잔차는 의 열공간에 수직인 부분공간(영차원 )에 살고, 그래서 .
표준오차 vs. 표준편차
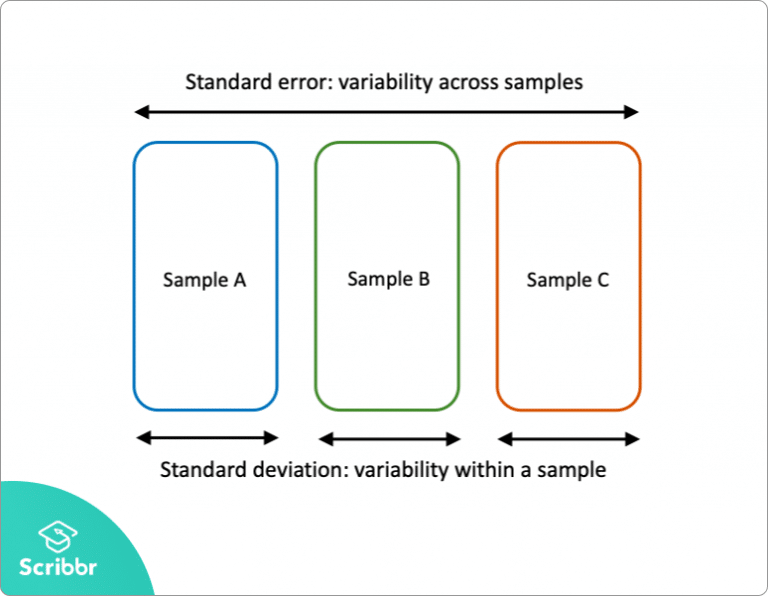
| 구분 | 표준오차 (SE) | 표준편차 (SD) |
|---|---|---|
| 의미 | 평균 추정의 불확실성 표본평균의 불확실성 | 데이터의 흩어짐 (변동성) 데이터 값들이 평균으로부터 얼마나 흩어져 있는지 |
| n(표본 크기) 영향 | n이 커질수록 감소 | 변화 없음 |
| 활용 | 추론 통계 (가설검정 - pval, 신뢰구간) | 데이터 자체 특성 설명 |
| 같은 시험 점수 데이터를 10명만 뽑아 평균 내면 오차가 클 수 있음. 하지만 1,000명을 뽑아 평균을 내면 실제 전체 평균과 더 가까울 확률이 높음. 이때 줄어드는 불확실성을 수치로 표현한 게 표준오차. | 시험 점수가 70점 평균인데, 표준편차가 2점이면 학생들이 대부분 68~72점 근처에 있음. 반대로 표준편차가 15점이면 성적이 들쭉날쭉함. | |
| 그 반에서 몇 명만 뽑아 평균을 냈을 때, “그 평균이 진짜 전체 평균과 얼마나 차이날까?” | 반 친구들 시험 점수가 얼마나 들쭉날쭉한지. |
…